Computer Vision Using Transformers
Attention Transformer Architecture
![]()
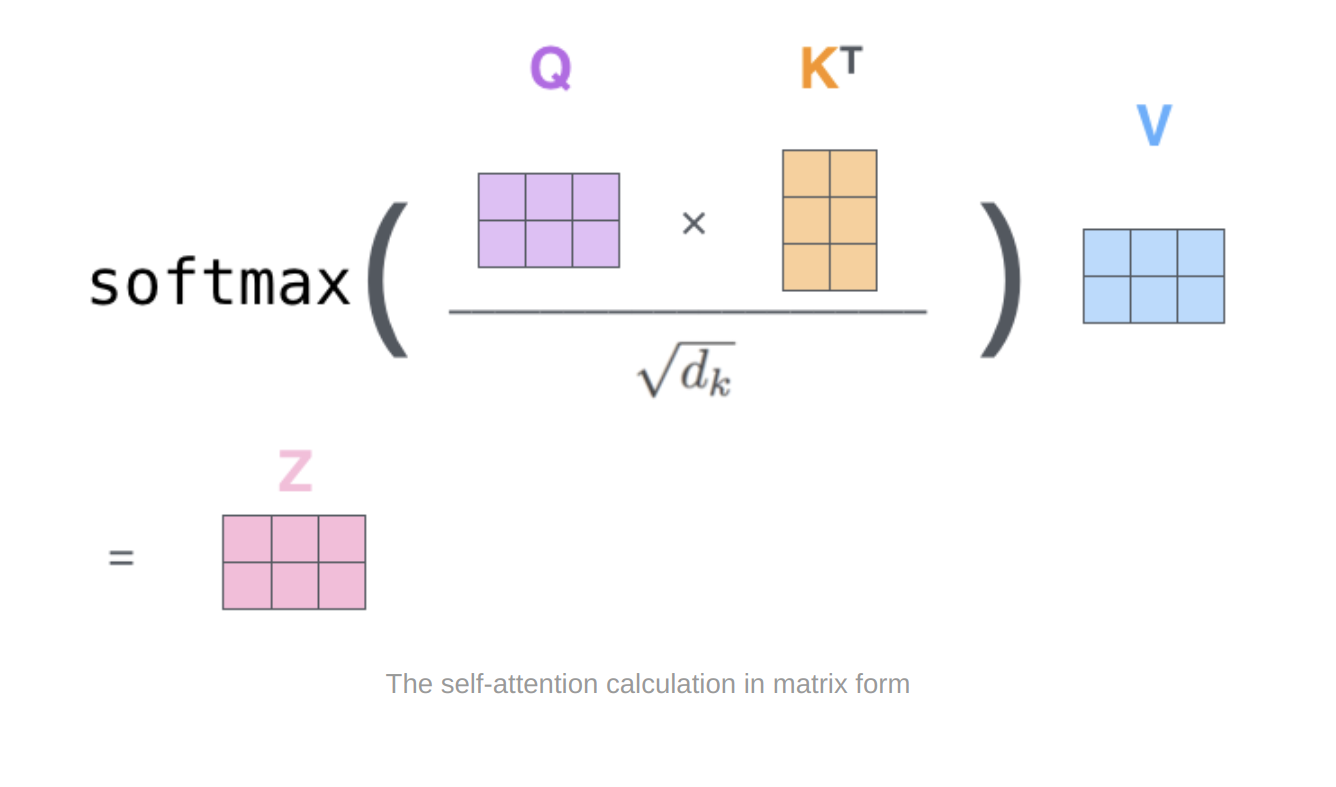
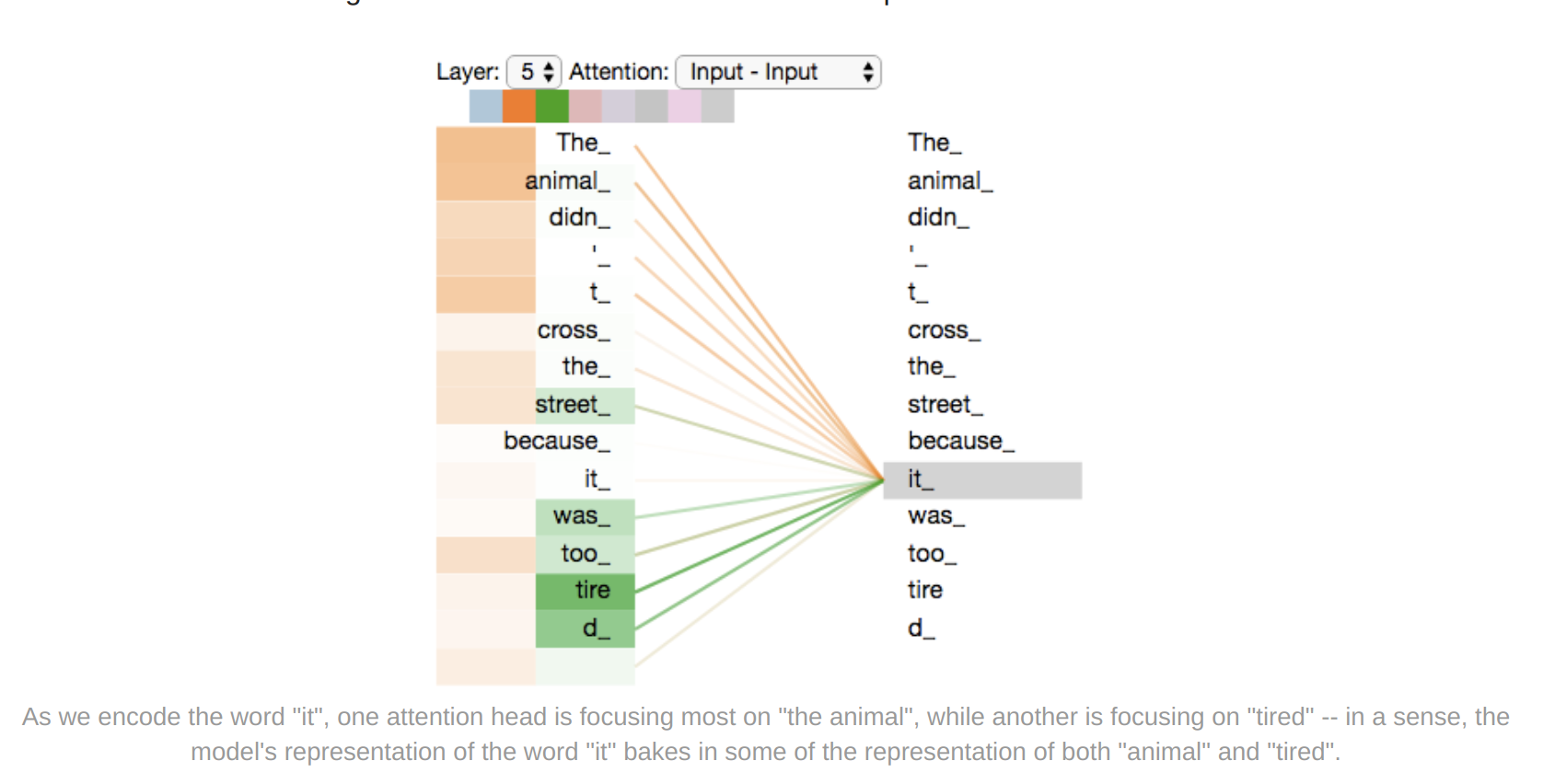
Self Attention
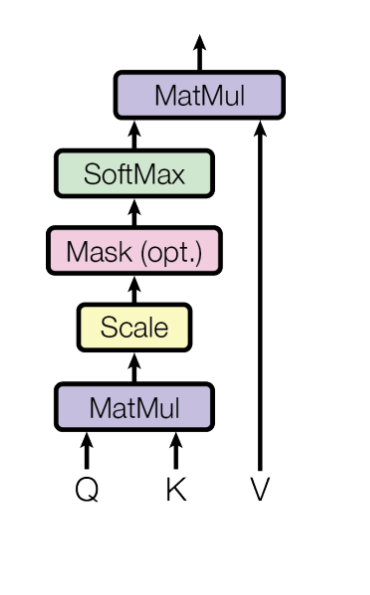
Self Attention
Self Attention
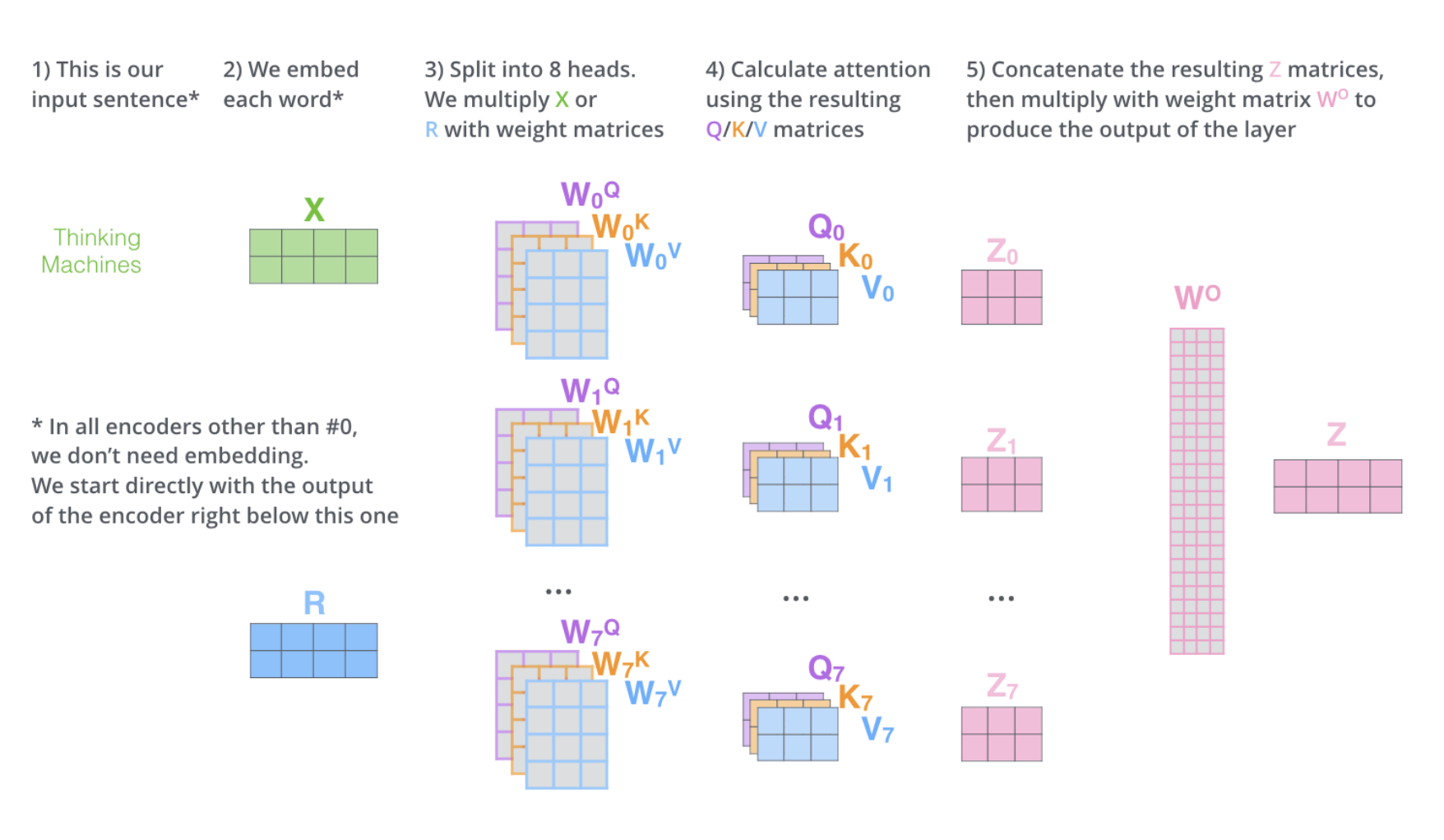
Why Multi-Head Attention
- It expands the models ability to focus on different positions
- It gives the attention layer multiple “representation subspaces”
![]()
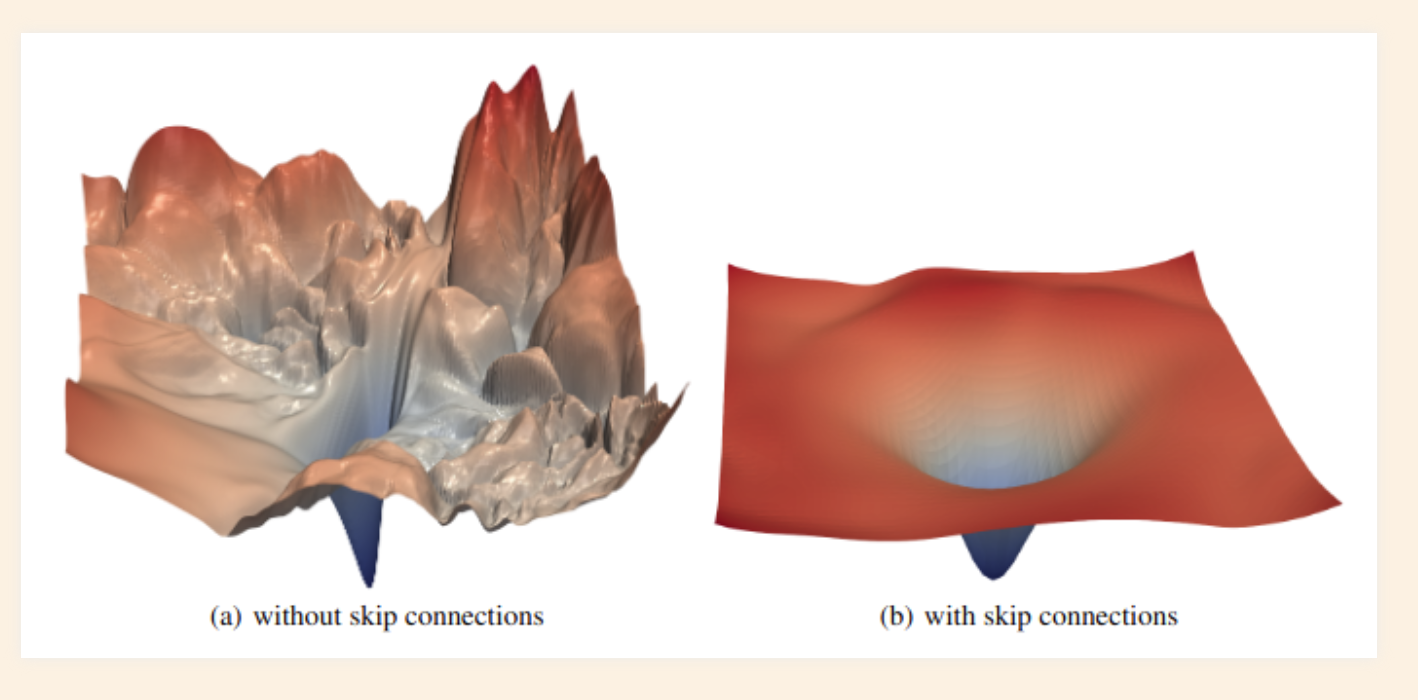
Skip connections
- Skip connection help a word to pay attention to its own position
- Keep the gradients smooth
![]()
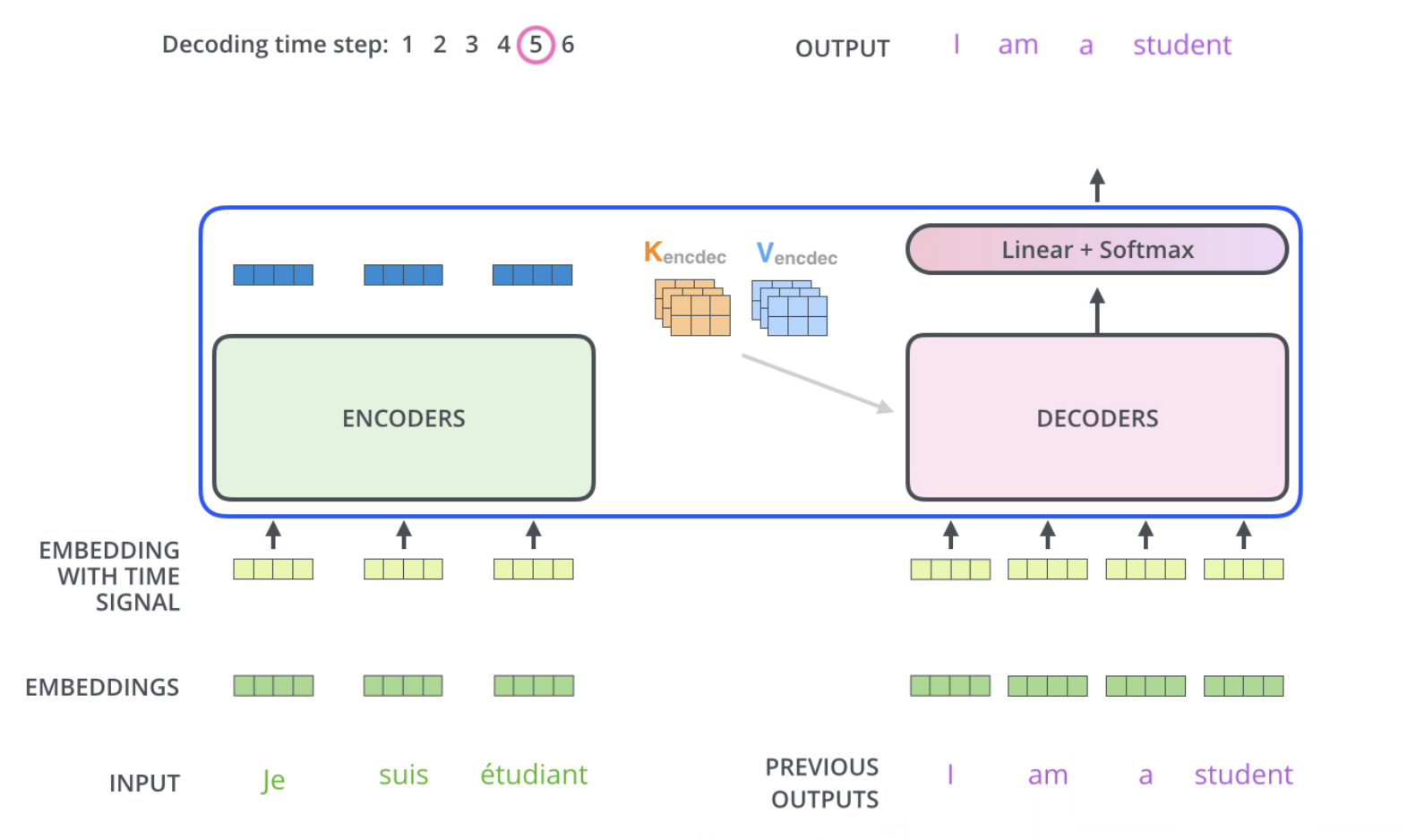
Steps in Decoder
Vision Transformer
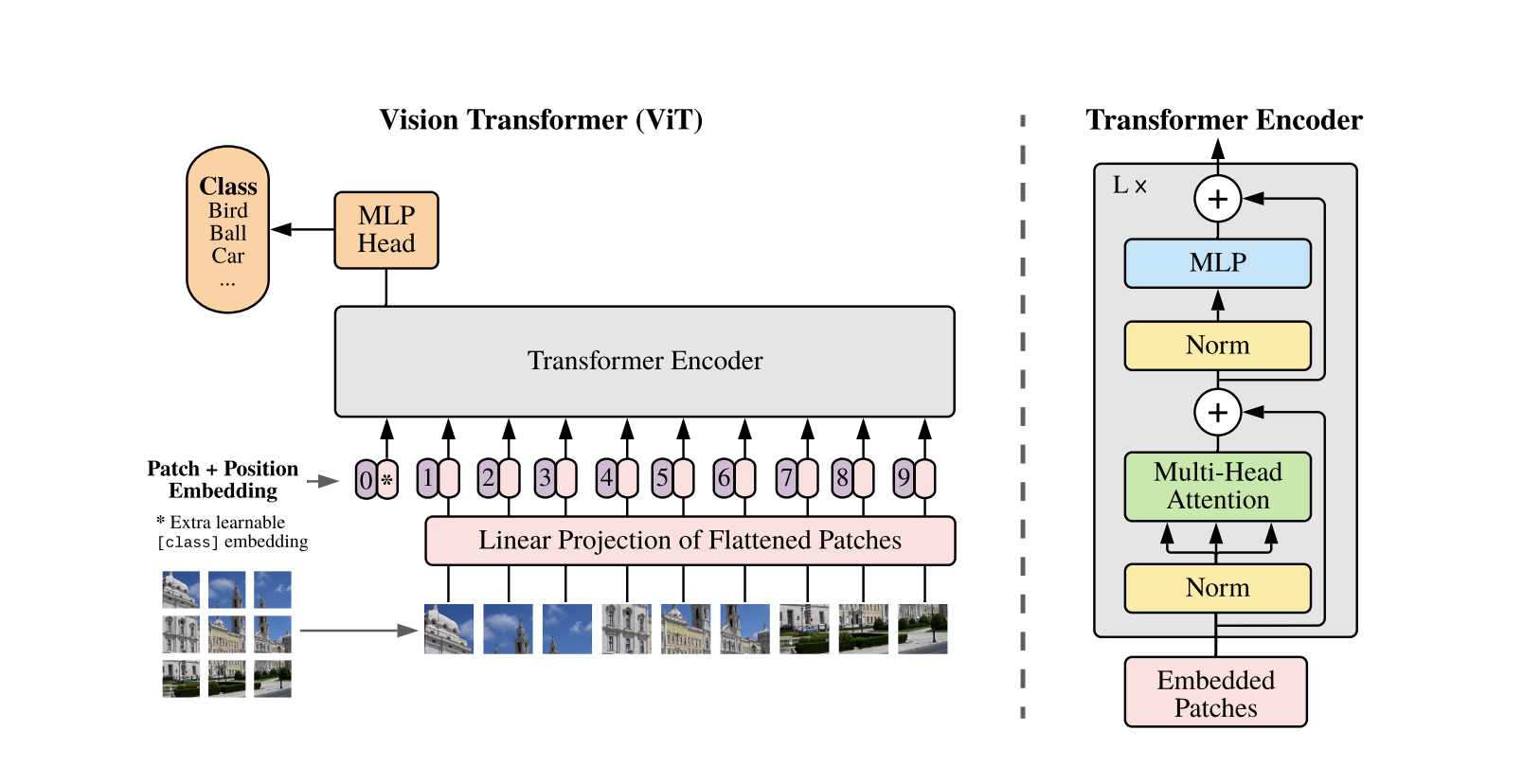
ViT Architecture
ViT Vs CNN
- Inductive Bias and Locality Vs Global
![]()

Object Detection with DETR
- DEtection TRansformer(DETR)
![]()

Object Detection with DETR
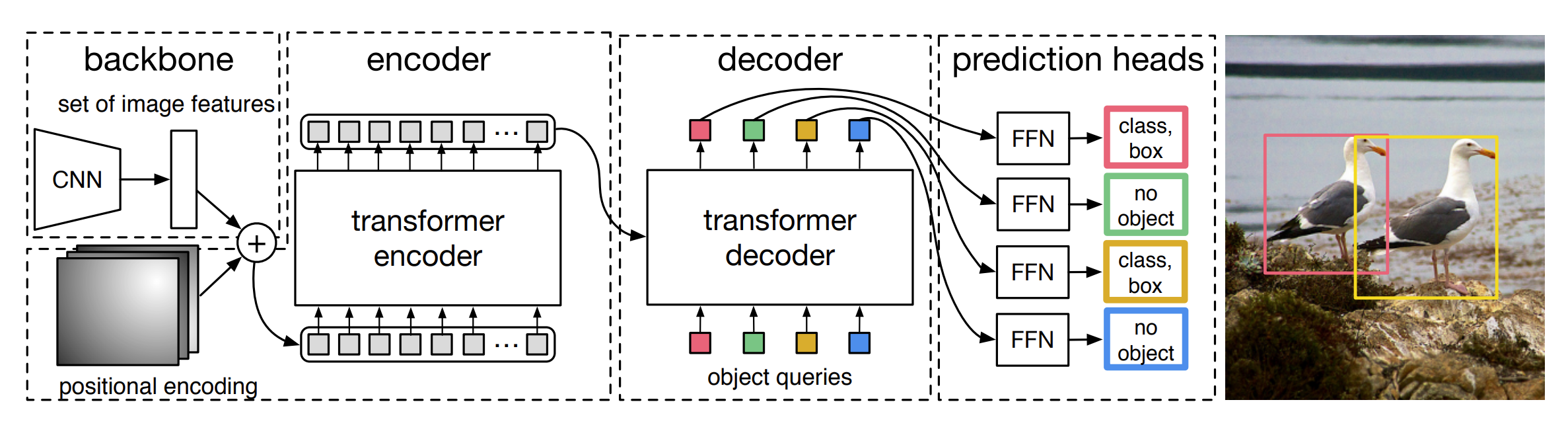
Object Detection with DETR
Object Detection with DETR

Why DETR

Why DETR
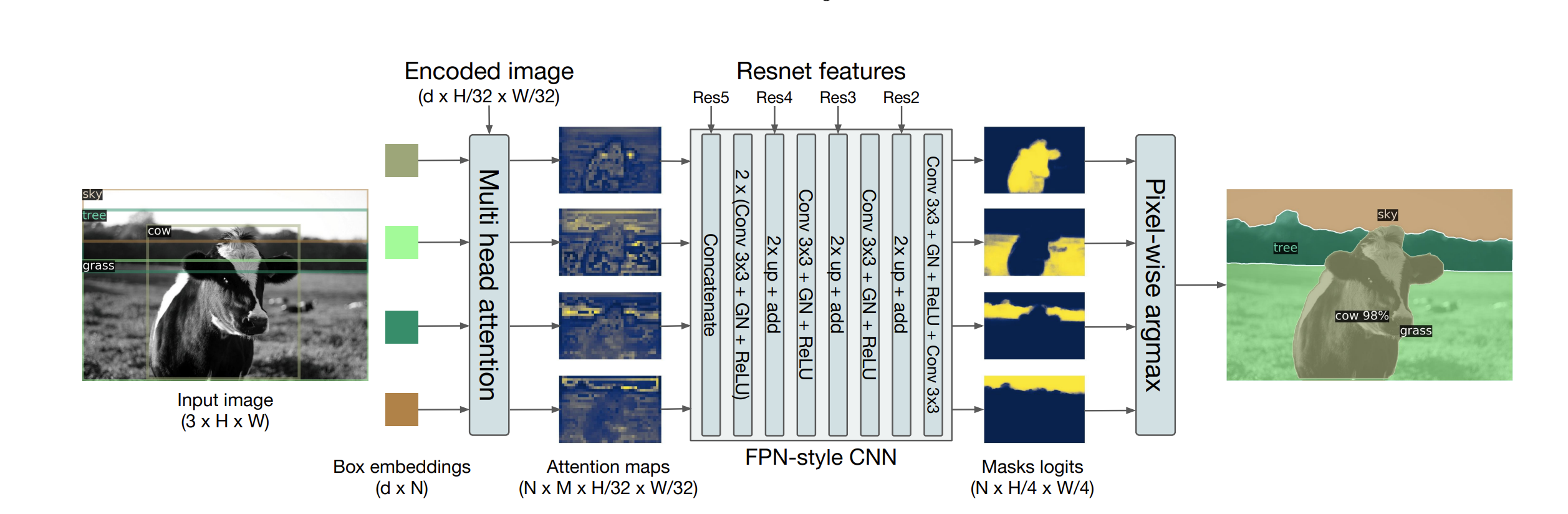
Why DETR
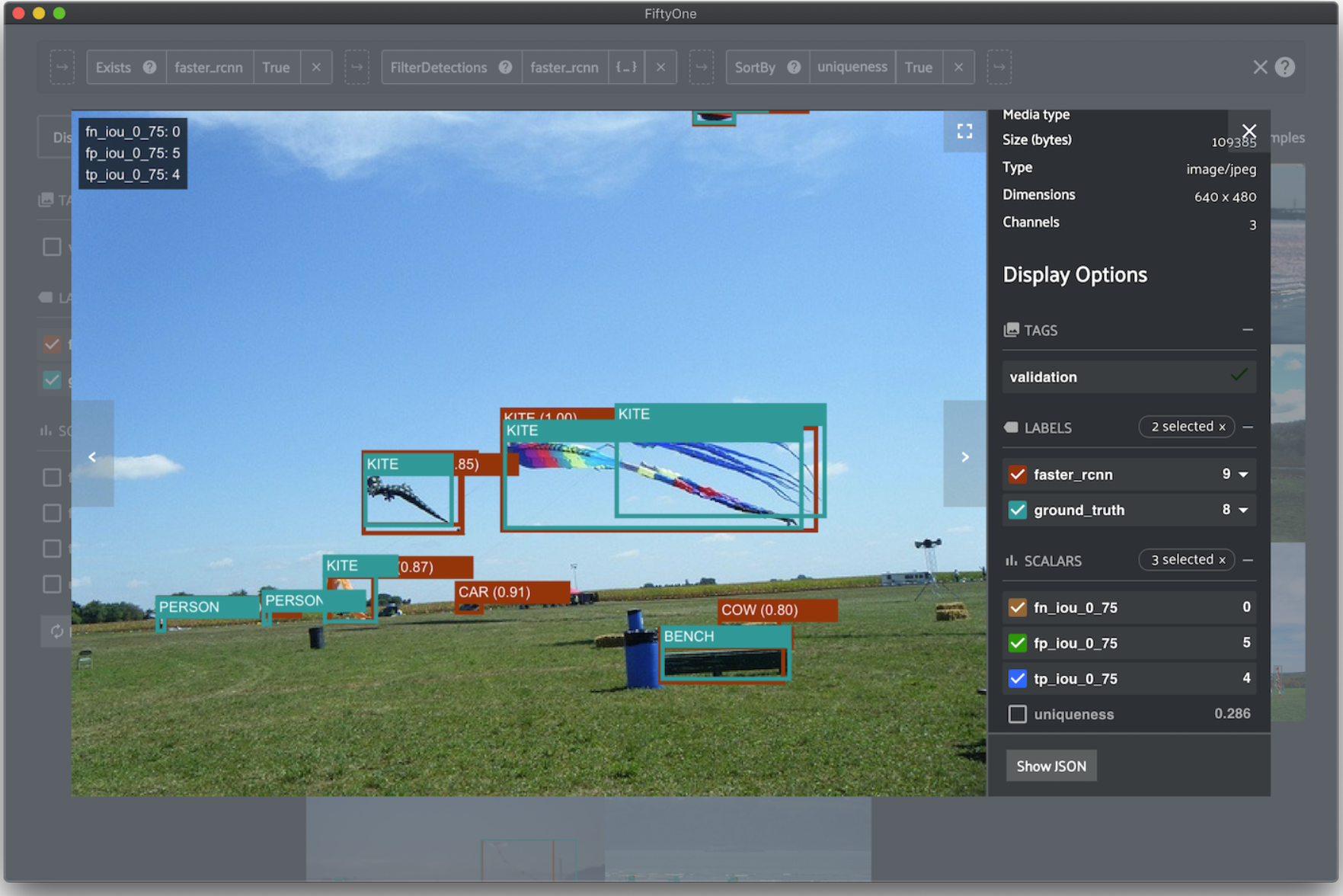
Tool Suggestion for Monitoring
- Fiftyone
![]()