Ethics and Bias in Data Science - Mitigation (Part - II)
In this blog post, we will discuss the tools at the disposal of Data Scientists to mitigate the bias and improve the fairness of analysis and models.
We will use Fairlearn package for our understanding. Fairlearn python package comprises algorithms for mitigating and metrics for evaluating bias of a dataset or model. It is essential to learn a few key concepts about fairness which will help us when we dive into the code.
First things first - what is fairness?
It is difficult to define fairness. There are atleat 21 different mathematical definitions of fairness. For the sake of this article, the term fairness means, “impartial and just treatment or behaviour without favouritism or discrimination to any individual or group”. The meaning of fairness will also change according the challenge at hand and the context. We should chose a definition for fairness in consultation with all the stakeholders after deliberating the impact for the company and the society.
Important terms
Protected Attribute An attribute or variable which divides the population into groups whose outcomes should be equal. Examples are attributes like gender, race, caste, age, etc.
Privileged Protected Attribute The value of the protected attribute belonging to a group which benefitted historically with a systemic advantage. If males get loans easily when compared to females, then they are Privileged Protected Attribute.
Favourable label The value of a label for an instance favourable for the recipient. Loan approved is a favourable label.
Unfavourable label This is the opposite of favourable label. Loan getting rejected is an unfavourable label.
Fairness Metric This is the quantification of bias in the data or model. A metric which quantifies how much a male is at an advantage when compared to a female is an example of fairness metric.
Individual Vs Group Fairness Individual fairness means similar individuals treated similarly. Example, in college admissions, females treated separately from males according to their EMCET scores.Group fairness is partitioning the population into distinct groups and checking if the statistical measures are equal for all the groups.
We’re all equal (WAE) Vs What you see is what you get (WYSIWYG) These two are different philosophies for the group fairness.According to WAE philosophy, the observations do not inform about the capability of the group because of structural bias. Example, EMCET scores are not an accurate indicator of the success in college for males and females. There are structural biases present because of which the EMCET scores are not an indicator of success.WYSIWYG believes the observations reflect true capabilities. Example, EMCET scores are an indicator of success in college. Metrics for WAE and WYSIWYG world views are different. Chose a suitable metric depending on the worldview of data scientists and different stakeholders for the project and the problem being tackled.
Mitigation algorithms The mitigation algorithms are of three types. Pre-processing, in-processing and post-processing depending on the machine learning life stage at which we use them. There are pre-processing algorithms which will either change the feature or label to de-bias the data. Some pre-processing algorithms assign weights to the instances without changing the features or labels. Algorithms need selection according to the requirement. In-processing algorithms play with the hyper-parameters like regularization to produce de-biased results. Post-processing algorithms change the final outputs to produce fair results.
Practical Example
Now let us turn our attention to a toy example to see how this works in action. The dataset for this exercise is ‘Loan Prediction’ data provided by Analytics Vidhya for practice. According to their website, The Dream Housing Finance company wishes to automate the loan eligibility process. The company captures historical data like Gender, Married, Dependents, Education, self-employed, LoanAmount etc of the past customers along with Loan_status i.e. if the loan is approved or not. The aim is to look at patterns in the data and decide if the company should provide loan to the customer or not.
The variables in the dataset are:-
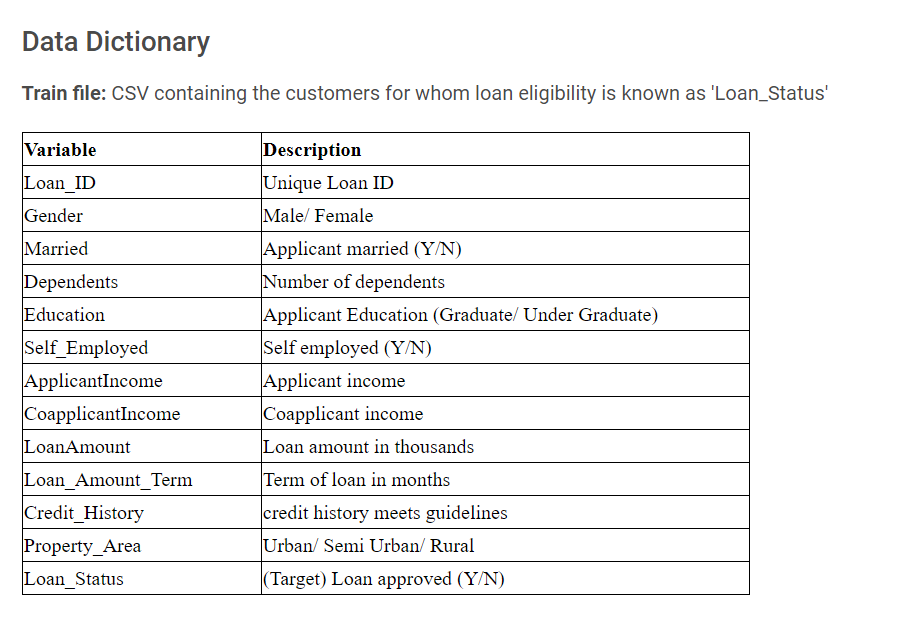 (credit: Analytics Vidhya)
(credit: Analytics Vidhya)
Let us see with a toy machine learning algorithm, what will happen if we are not mitigating the bias and what are the results if bias is mitigated. As this is an exercise done for demonstrating a specific point, I took many shortcuts. For example, here I am not dividing the dataset into train and test. In an actual scenario, we must follow all the machine learning best practices. With that caveat in place, Let’s dive in…
Link to Notebook and data with all the steps. In this dataset the protected variable is ‘Gender’ and the privileged, protected variable is male. The favourable label is loan getting approved. Now let us plot the number of male and female loan applicants in the data.
gender = data['Gender'].value_counts()
plt.figure(figsize=(12,6))
sns.barplot(gender.index, gender.values, alpha=0.8)
plt.title('Number of loan applicants - Men and Women')
plt.ylabel('Number of applicants', fontsize=12)
plt.xlabel('Gender', fontsize=12)
plt.show()
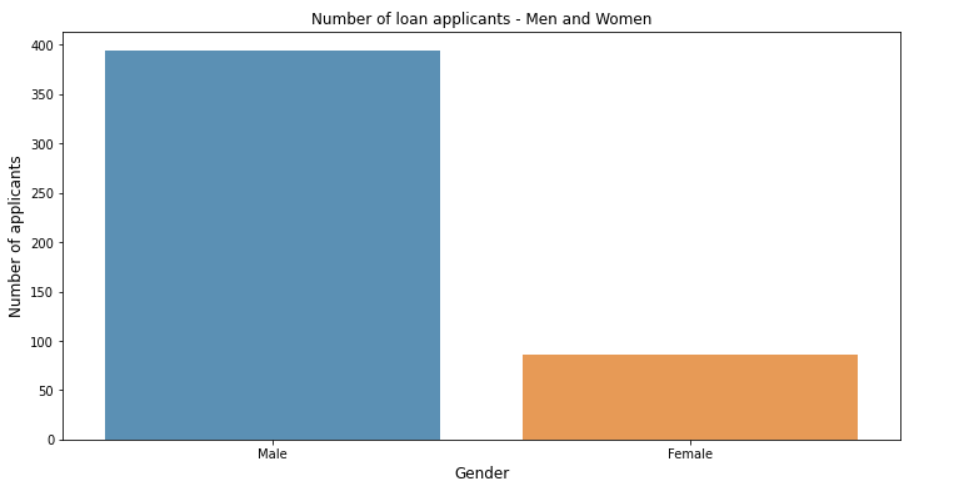
Now we apply logistic regression model without any constraints to check the overall and protected variable accuracies.
clf = LogisticRegression(penalty='l2', class_weight = 'balanced',random_state = 786)
clf.fit(X,y_true)
LogisticRegression()
y_pred = clf.predict(X)
group_summary(accuracy_score,y_true,y_pred,sensitive_features = gender)
The overall accuracy for the dataset is 74%. The accuracy for male is 77% and for female it is 58%. As this is an imbalanced dataset let us have a look at recall. Fairlearn package has the option to create a beautiful dashboard with a few lines of code.
from fairlearn.widget import FairlearnDashboard
FairlearnDashboard(sensitive_features = gender,
sensitive_feature_names=['sex'],
y_true = y_true,
y_pred = y_pred)
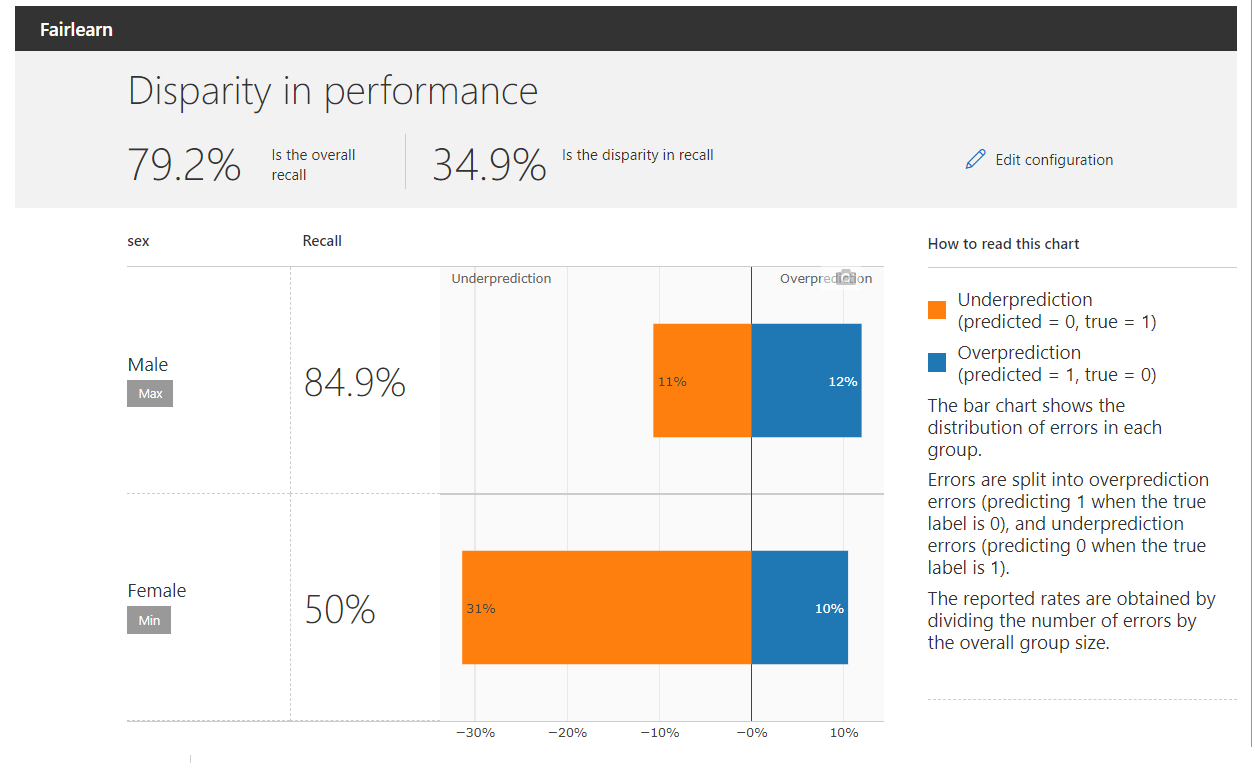
Recall means “what proportion of actual positives was identified correctly?’’. Here positives means loans approved. Out of the all the loans approved, how many of them were identified correctly. The recall for the complete data is 79.2% and the disparity in recall for both the groups is 34.9%.
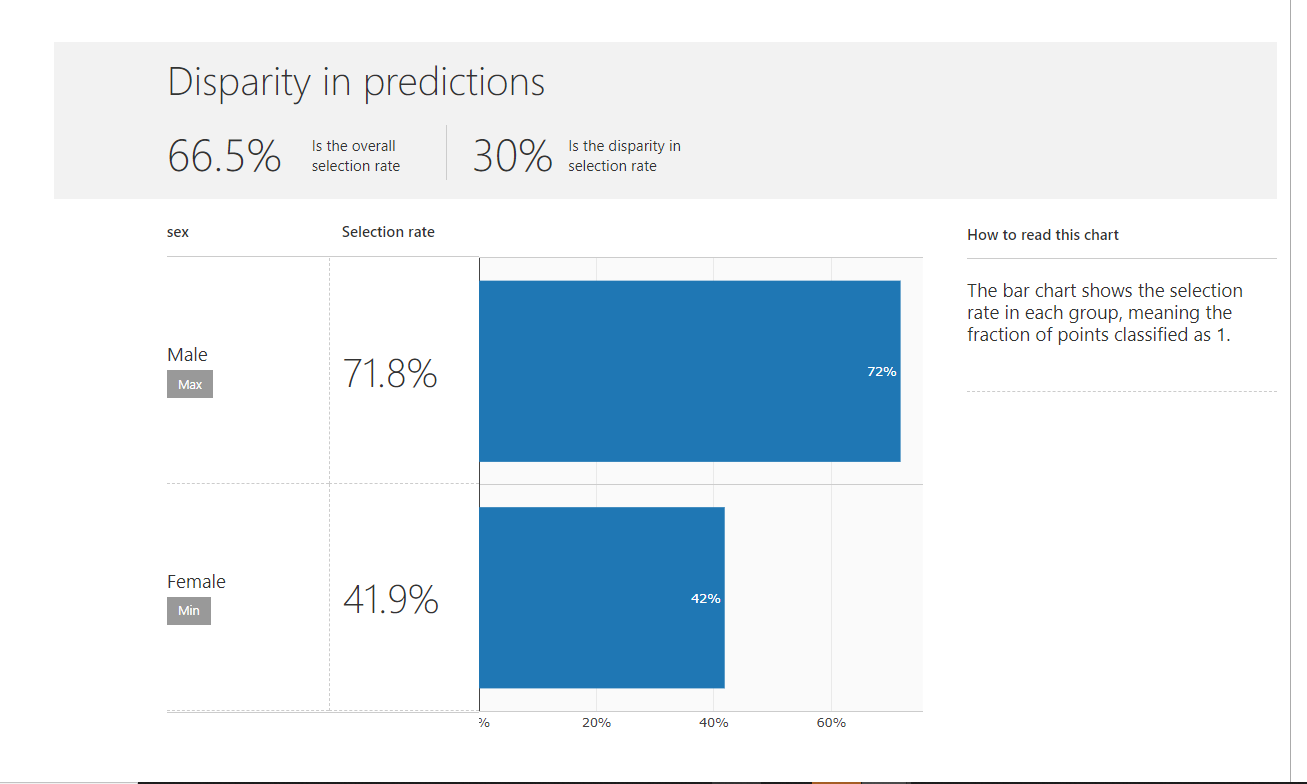
The disparity in predictions - The difference in number of instances classified as postivie for both the groups is 30%. This means if this algorithm is used for deciding if a loan should be provided then the probability of women getting loans is 30% lesser than for men.
Now Let us use an algorithm for mitigation. This algorithm will take into account a constraint - Demographic parity, while optimizing the cost function. Demographic parity means that the two different groups should get equal number of loans. The algorithm results should not depend on the protective attribute i.e. Gender. Lets see the results on the same Logistic regression algorithm using Demographic parity.
from fairlearn.reductions import ExponentiatedGradient , DemographicParity
np.random.seed(786)
constraint = DemographicParity()
clf =LogisticRegression(penalty='l2', class_weight = 'balanced',random_state = 786)
mitigator = ExponentiatedGradient(clf, constraint)
mitigator.fit(X, y_true, sensitive_features = gender)
y_pred_mitigated = mitigator.predict(X)
Let’s Check the accuracy after mitigation on overall level and for both groups
from fairlearn.metrics import selection_rate_group_summary
selection_rate_group_summary(y_true, y_pred_mitigated, sensitive_features = gender)
There is a slight dip in accuracy but the disparity between both the groups reduced from 19% to less than 1%
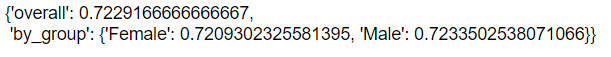
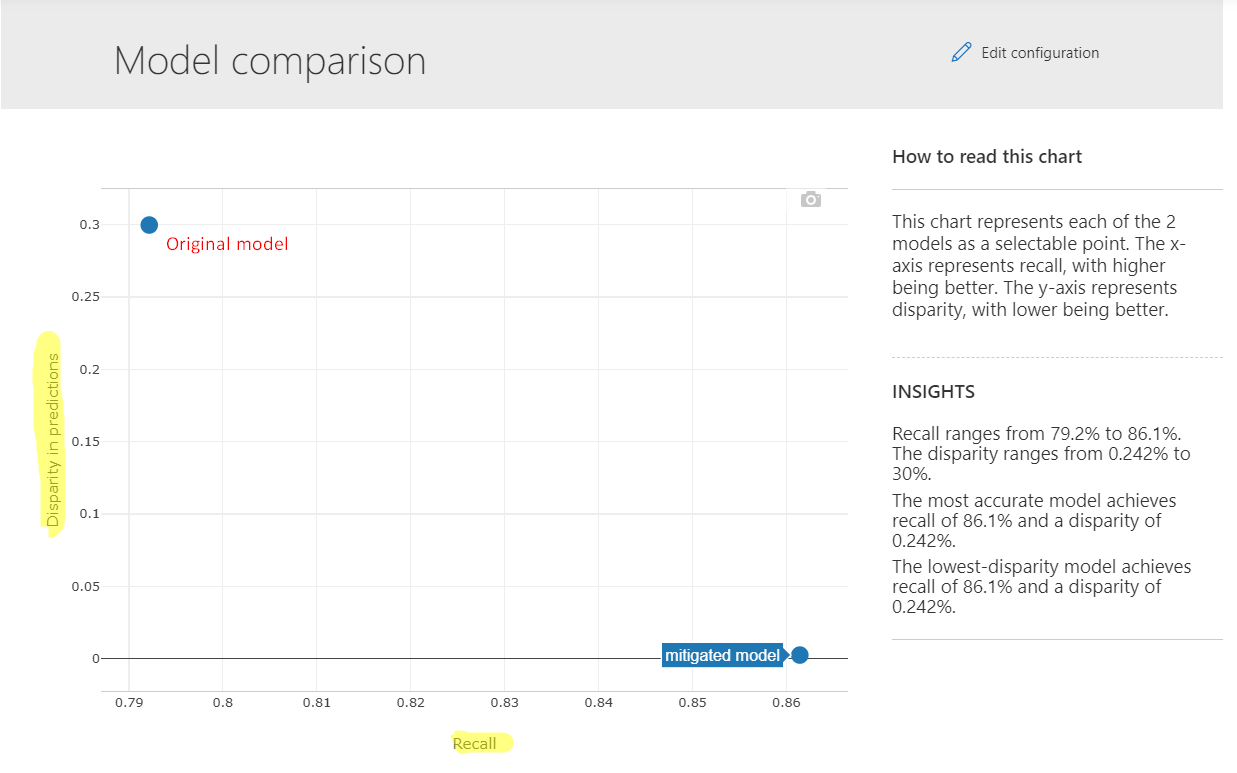
Lets check the performance on Recall with the mitigated algorithm
FairlearnDashboard(sensitive_features = gender,
sensitive_feature_names = ['sex'],
y_true = y_true,
y_pred = {"initial model": y_pred, "mitigated model" : y_pred_mitigated})
The Recall for the mitigated algorithm is 86.1% compared to 79.2% for the inital algorithm. The disparity reduced from more than 34% to 1.15%. A win-win situation for any data scientist. This is a toy example and in a real life scenario the recall of the debiased algorithm may be less than the original algorithm. As mentioned earlier this needs to be deliberated with all the stakeholders and an appropriate decision should be taken.
Summary
Data, machine learning, and Artificial Intelligence are becoming ubiquitous. Deployment of machine learning systems without thinking through the implications is a grave risk for the company and the society. In the first part of the article, we discussed the cost of bias in data and machine learning algorithms. In the second part, we looked at an example of measuring and mitigating bias. We just scratched the surface here. Finally, we saw a code example of how to mitigate bias by using a constraint on the cost function.
As mentioned earlier there lies a great responsibility on the shoulders of a data scientist. The way forward is tough, but that makes us what we are and that differentiates a data scientist from a great data scientist. Let us take the first step in the right direction to make this world fair. As said by Lao Tzu, a journey of a thousand miles begins with a single step. In the next blog post we will learn about another exceptional package for dealing with bias.