Tile2Vec - Unsupervised representation learning
Research by Neal Jean and Sherrie Wang
Learning a lower-dimensional representation of the data that can be used for any number of downstream ML tasks
Landscapes in remote sensing datasets are highly spatially correlated. The idea is to extract enough learning signal to reliably train deep neural networks
Distributional Hypothesis
- The distributional hypothesis in linguistics is the idea that a word is characterized by the company it keeps. words that appear in similar contexts should have similar meanings.
- In natural language processing (NLP), this assumption that meaning can be derived from context is leveraged to learn continuous word vector representations like Word2vec and GloVe
Tobler’s First law of Geography
- Everything is related to everything else, but near things are more related than distant things.
Approach
- To extend the Word2vec analogy from NLP, an image tiles is used similar to be our “words” and spatial neighborhoods (defined by some radius) to define the context. The image tiles that are geographic neighbors (i.e. close spatially) should have similar semantics and therefore representations, while tiles far apart are likely to have dissimilar semantics and should therefore have dissimilar representations.
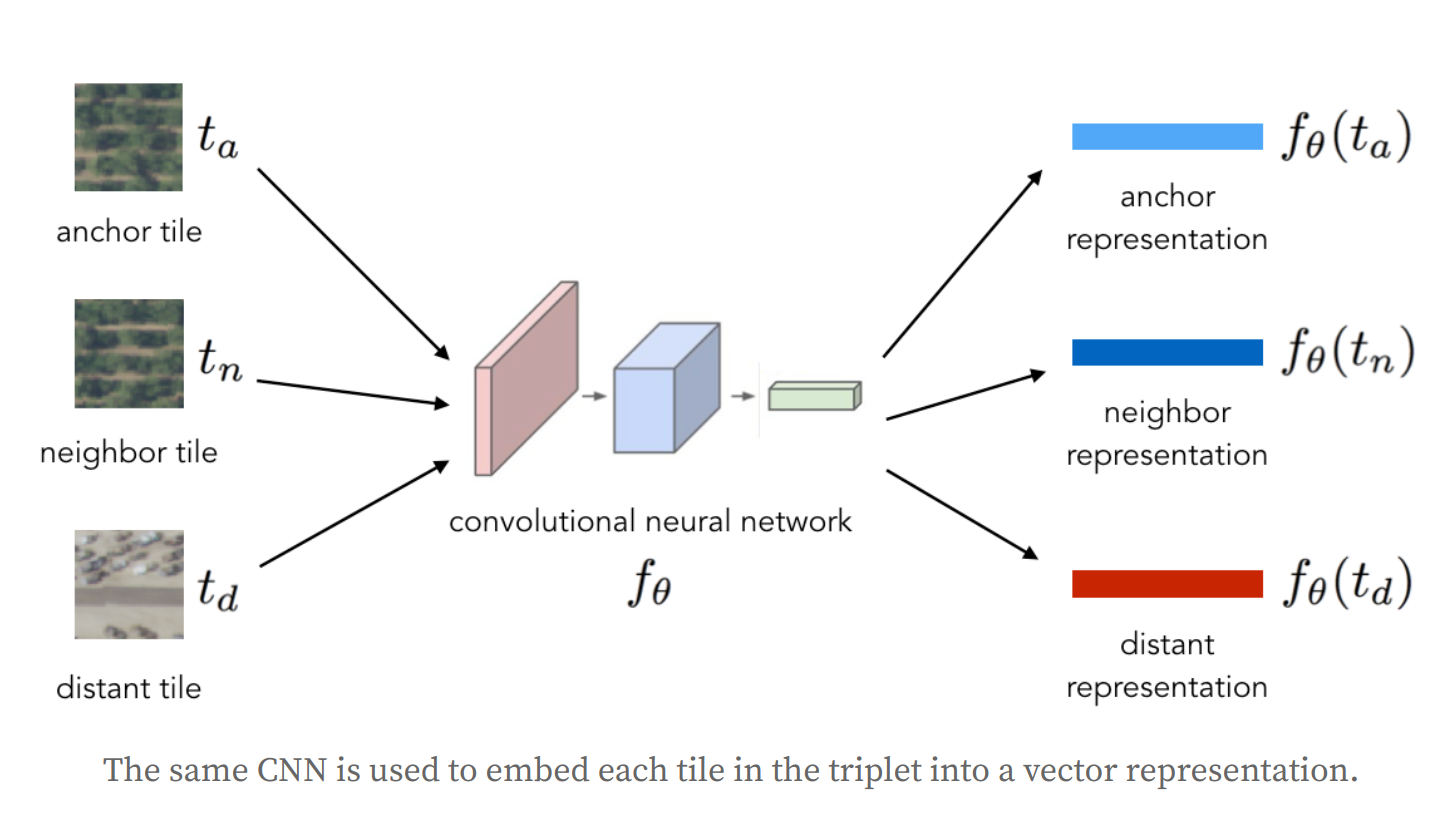
- To learn a mapping from image tiles to low-dimensional embeddings, train a CNN on triplets of tiles, where each triplet consists of an anchor tile, neighbor tile and a distant tile.
- Tiles from the same neighborhood are more likely to be similar than their more distant counterparts.
- A CNN is trained to minimize the distance between the anchor and neighbor embeddings, while maximizing the distance between the anchor and distant embeddings.

Model
- Tile2Vec CNN is a ResNet-18 architecture without the classification layer
Poverty prediction using Tile2Vec
- For each Uganda cluster, the team extracted a median composite through Google Earth Engine of roughly 75 × 75 pixels (5 km2) centered at its location. They randomly sample 10 tiles from this patch and average their Tile2Vec embeddings. These embeddings are then input to a ridge regression to predict log consumption expenditures.