CNN Interpretation
Learned Features
- The approach of making the learned features explicit is called Feature Visualization
- Feature visualization for a unit of NN is done by finding the input that maximizes the activation of that unit
- Feature visualization can be done at Neuron, feature map, entire convolution layer etc.
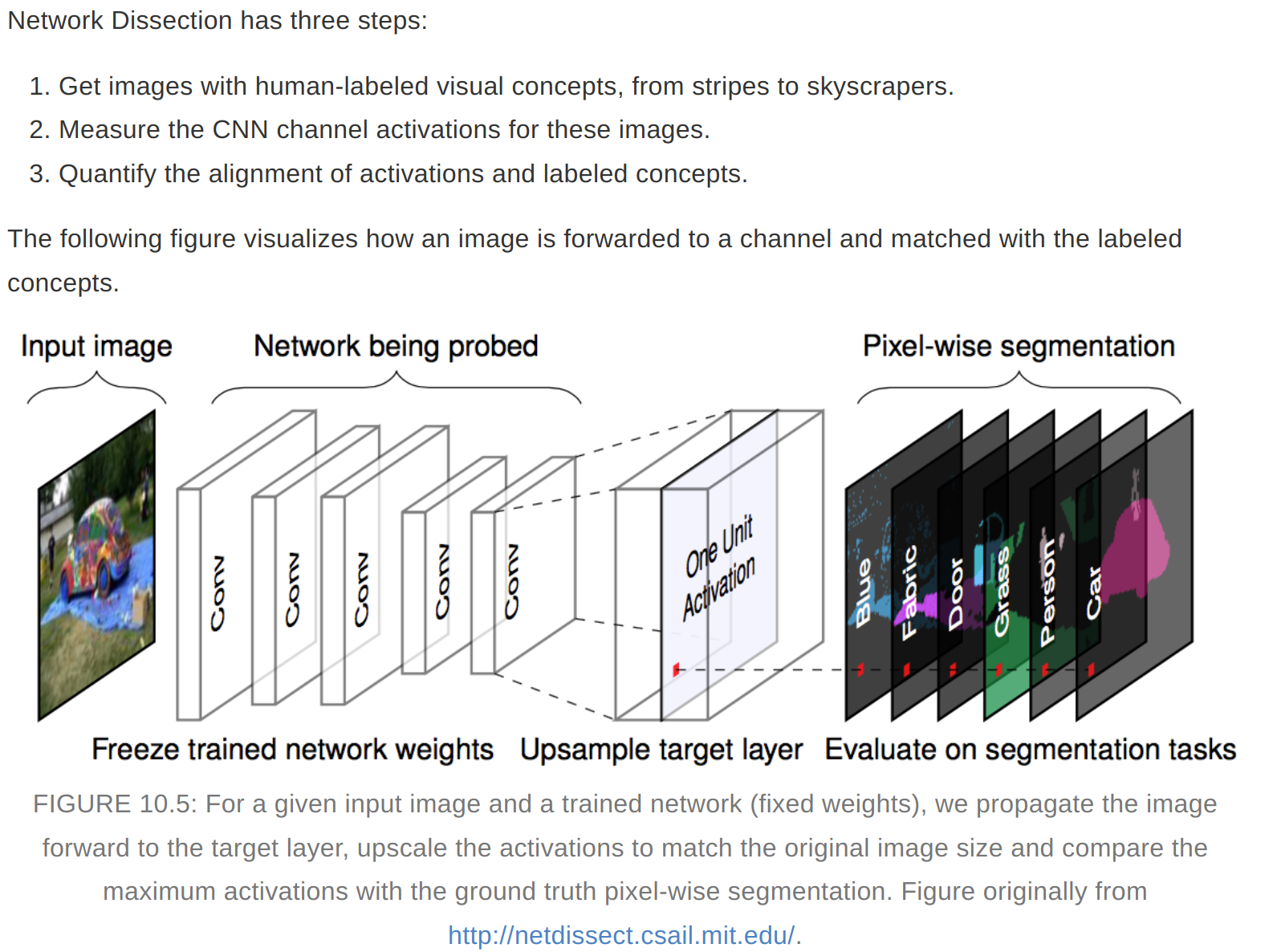
Network Dissection
- It links highly activated areas of CNN channels with human concepts
Pixel Attribution (Saliency Maps)
- This method highlights the pixels that were relevant for a certain image classification
- Pixel attribution can be of two methods
- Perturbation based - Manipulate parts of the image to generate explanations
- Gradient based - Many methods compute the gradient of the prediction with respect to the input features
Gradient based methods
- Vanilla Gradient
- DeconvNet
- Grad-CAM
- Guided Grad-CAM
- SmoothGrad
Detecting Concept
- TCAV - Testing with concept activation vectors - For any given concept, TCAV measures the extent of that concept’s influence on the model’s prediction for a certain class. For example, TCAV can answer questions such as how the concept of “striped” influences a model classifying an image as a “zebra”. Since TCAV describes the relationship between a concept and a class, instead of explaining a single prediction, it provides useful global interpretation for a model’s overall behavior.
- Different types of CAV:-
- Automated concept based explanation (ACE)
- Concept bottleneck models
- Concept whitening
Adversarial Examples
- An instance with small, intentional feature perturbations that cause a ml model to make a false prediction
Influential Instances
- We call a training instance “influential” when its deletion from the training data affect the resulting model.
- Two approaches:-
- Deletion diagnostics
- Influence functions
Deletion Diagnostics
- DFBETA - Measures the effect of deleting an instance on model parameters
- Cook’s distance - Measures the effect of deleting an instance on model predictions
- DFBETA works only for parameterized models
- we can build a interpretable model between the influence of the instances and their features. This will provide more insights into the model.
- The disadvantage of this method is that retraining is required for each instance in the dataset.
