Boosting
- Sequential Ensembles exploit the dependence of base estimators
- sequential ensembles train a new base estimator in such a manner that it minimizes mistakes made by the base estimator trained in the previous step
- Boosting aims to combine weak learners, or “simple” base estimators. In contrast, parallel ensembles like
Bagginguse strong learners as base estimators - Decision trees typically use decision stumps, or decision trees of depth 1 as base estimators (weak learners)
- Sequential ensemble methods such as boosting aim to combine several weak learners into a single strong learner. These methods literally “boost” weak learners into a strong learner
AdaBoost: AdAptive BOOSTing
To ensure that the base learning algorithm prioritizes misclassified trainng examples, Adaboost maintains weight over individual training examples. Misclassified examples will have more weight
When we train the next base estimator sequentially, the weights will allow the learning algorithm to prioritize (and hopefully fix) mistakes from the previous iteration. This is the “adaptive” component of AdaBoost, which ultimately leads to a powerful ensemble. The whole training set is used for each iteration
Each weak estimator is different from each other and classify the problem in diversely different ways. Reweighting allows AdaBoost to train a different base estimator at each iteration, one that is often different from an estimator trained at the previous iterations.
Adaptive reweighting or updating adaptively, promotes ensemble diversity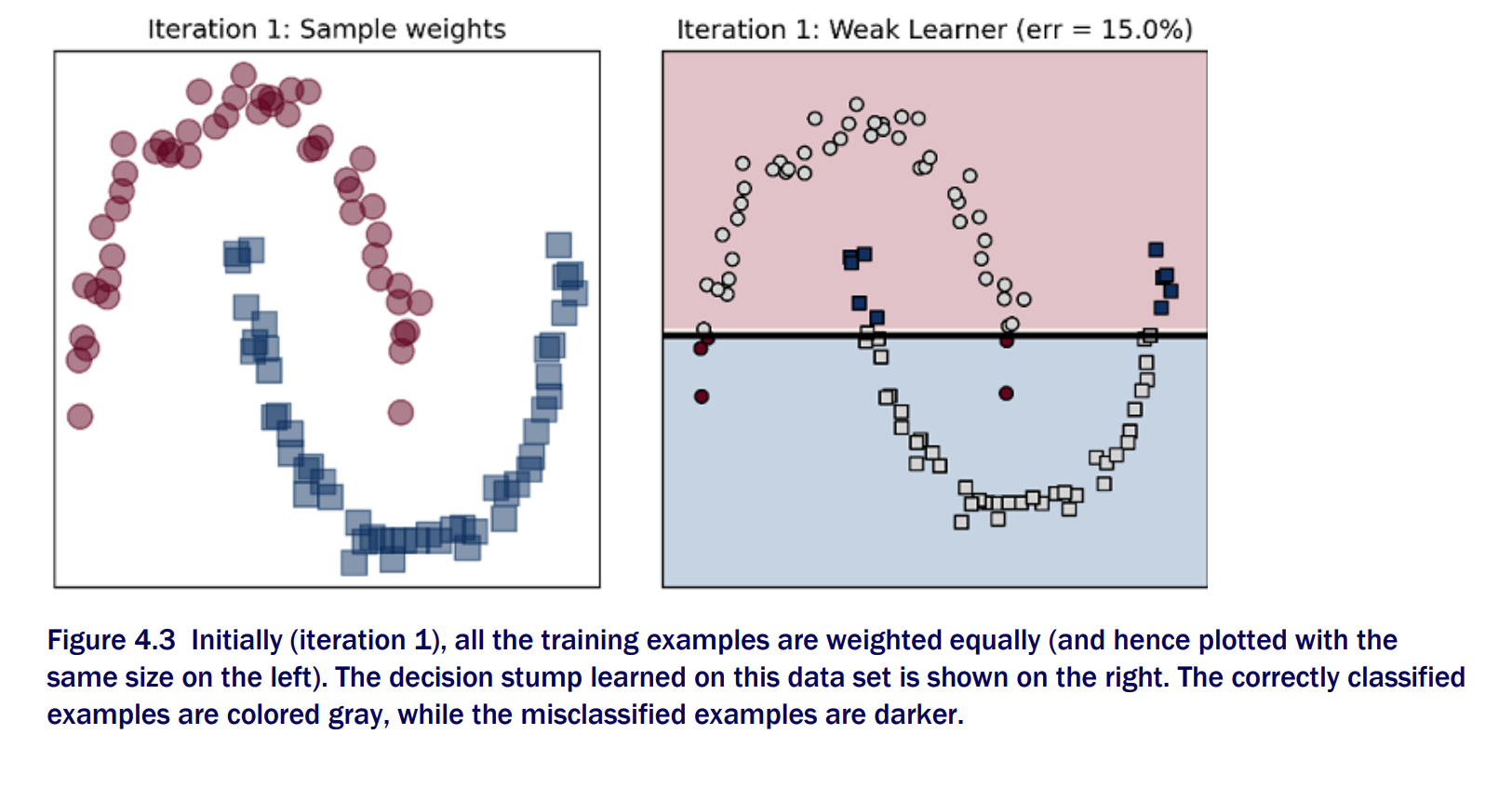
Boosting Iteration 1 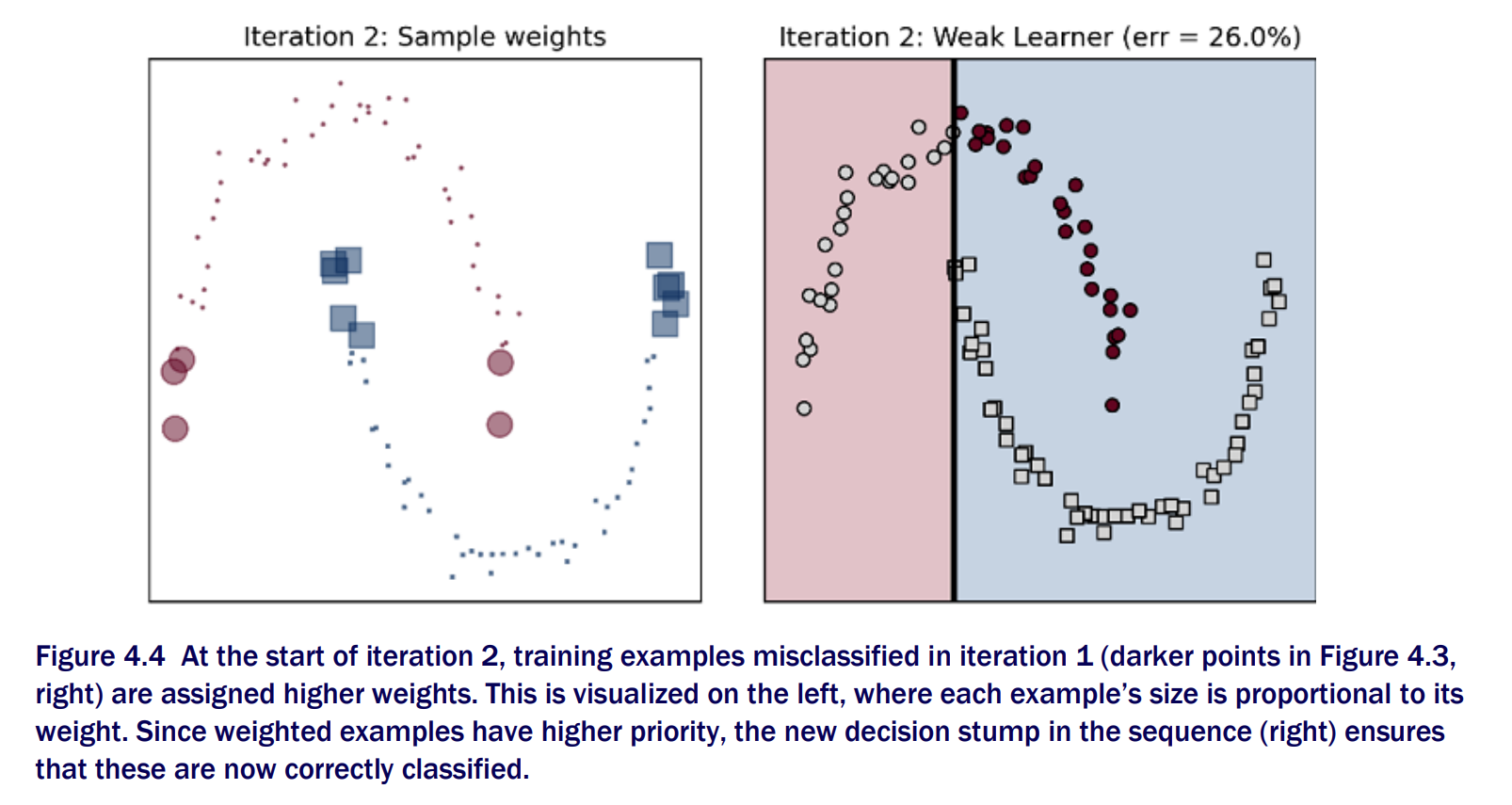
Boosting Iteration 2 
Boosting Iteration 3 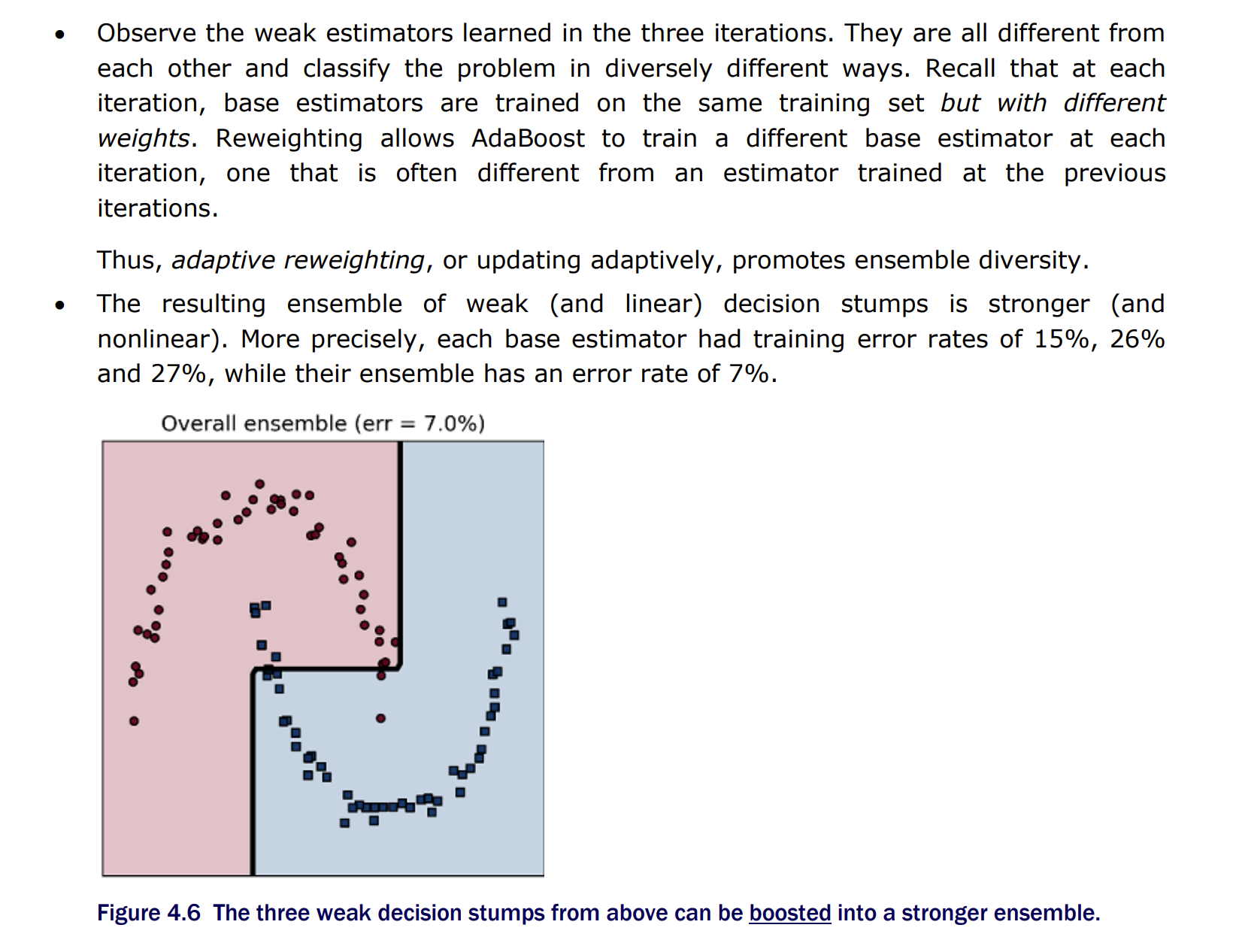
Boosting - Ensemble of weak learners
Adaboost Steps
Use decision stumps as base estimators which are weak learners
Keep track of weights on individual training examples
Keep track of weights of individual base estimator

Adaboost Algorithm 
Weighing weak learners 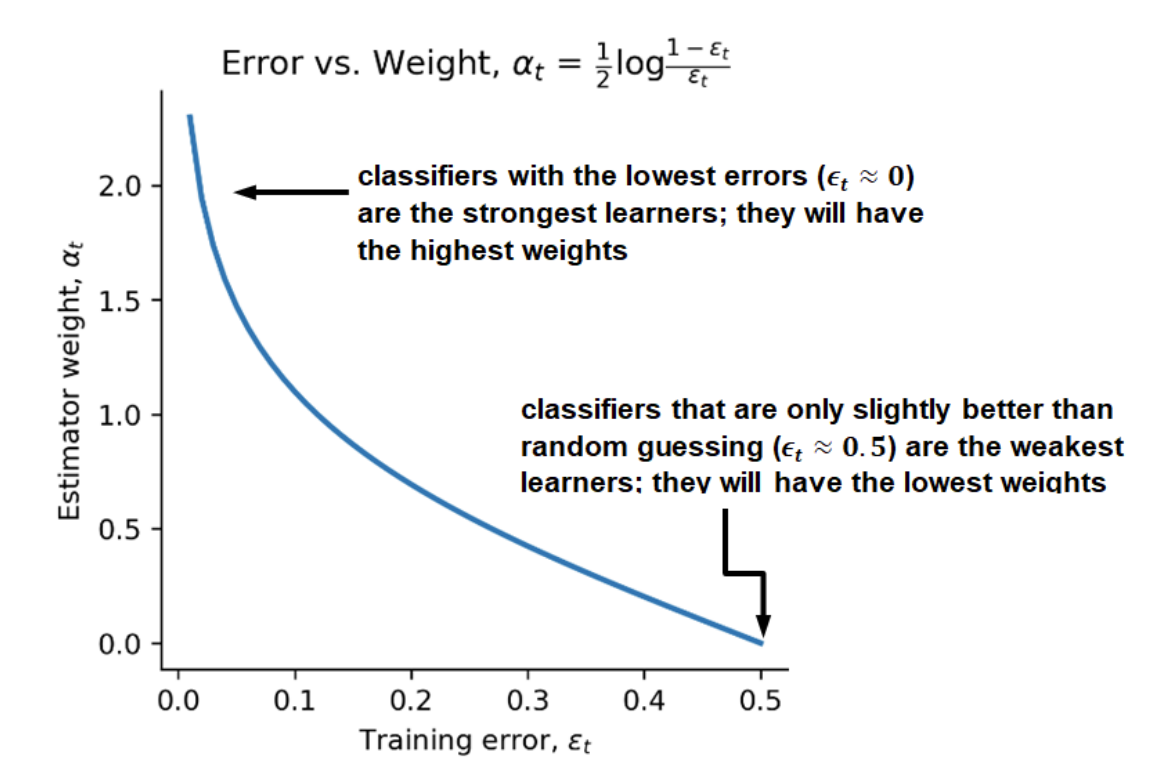
Weighing weak learners 
Training example Weights 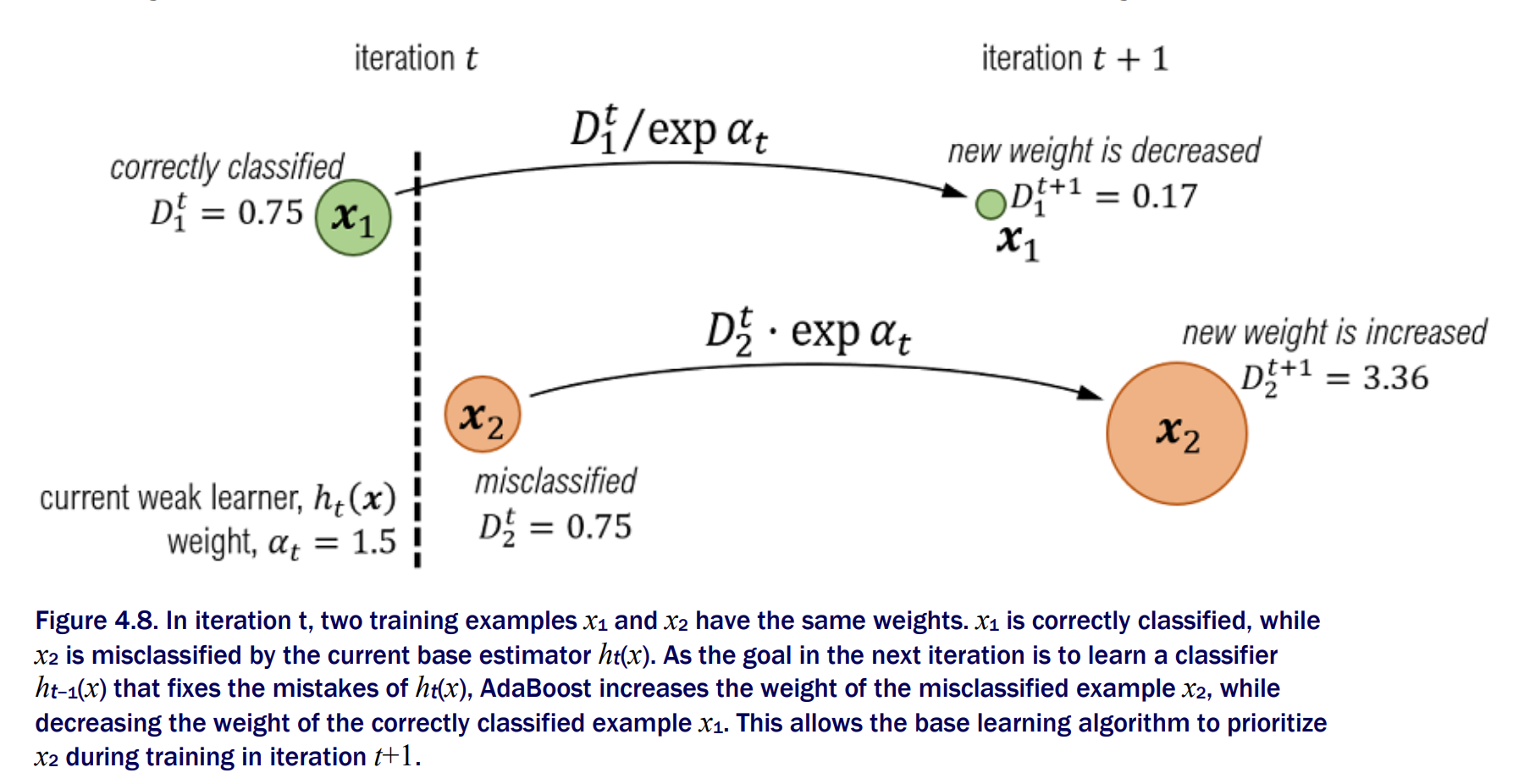
Training example weights
Adaboost Implementation
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
def fit_boosting(X,y,n_estimators=10):
n_samples, n_features = X.shape
# Initialize the weights for the training set
D = np.ones((n_samples,))
estimators = []
for t in range(n_estimators):
# Noramlize the weights (add to 1)
D = D / np.sum(D)
h = DecisionTreeClassifier(max_depth=1)
h.fit(X, y, sample_weight=D)
ypred = h.predict(X)
# Calculate the error for the weak learner
e = 1 - accuracy_score(y, ypred, sample_weight = D)
# Update the weights for the weak learner
a = 0.5*np.log((1 -e) / e)
# calculate the sign for each training example
# If the training example is correct then its weight will be reduced
# If the training example is incorrect then its weight will be increased
m = (y == ypred) * 1 +(y != ypred) * -1
# Calculate the new weights for the training set
D *= np.exp(-a * m)
# Save the weak learner and its weight
estimators.append(a,h)
return estimatorsAdaboost with scikit-learn

Adaboost in practice
- The adaptive property (adapt to mistakes made by previous week learners) is a disadvantage when outliers are present. The weak learners continue to misclassify the outlier, in which case Adaboost will increase its weight further, which in turn, causes succeding weak learners to misclassify, fail and keep growing its weight
- It correctly classifies the outlier, in which case Adaboost overfit the data
Training Robust Adaboost Models
Learning Rate It adjusts the contribution of each estimator to the ensemble. (A learning rate of 0.75 decrease the overall contribution of each estimator by a factor of 0.75). In case of outliers, learning rate should be lowered.

Adaboost Learning Rate 
Adaboost Learning Rate
Early Stopping and Pruning
- Identifying the least number of base estimators in order to build an effective ensemble is known as early stopping.

Summary
- AdaBoost, or Adaptive Boosting is a sequential ensemble algorithm that uses weak learners as base estimators.
- In classification, a weak learner is a simple model that performs only slightly better than random guessing, that is 50% accuracy. Decision stumps and shallow decision trees are examples of weak learners.
- AdaBoost maintains and updates weights over training examples. It uses reweighting both to prioritize misclassified examples and to promote ensemble diversity.
- AdaBoost is also an additive ensemble in that is makes final predictions through weighted additive (linear) combinations of the predictions of its base estimators.
- AdaBoost is generally robust to overfitting as it ensembles several weak learners. However, it is sensitive to outliers owing to its adaptive reweighting strategy, which repeatedly increases the weight of outliers over iterations.
- The performance of AdaBoost can be improved by finding a good tradeoff between the learning rate and number of base estimators
- Cross validation with grid search is commonly deployed to identify the best parameter tradeoff between learning rate and number of estimators.
- Under the hood, AdaBoost ultimately optimizes the exponential loss function.
- LogitBoost is another boosting algorithm that optimizes the logistic loss function. It differs from AdaBoost in two other ways
Reference
- Manning book
Ensemble methods for machine learning