Question Answering (QA)
Getting specific answers to the user question by searching through oceans of documents.
There are many flavours of QA systems
* Extractive QA
* Abstractive or Generative QA
* Community QA
* long-form QA
* QA over structured dataExtractive QA
This is a type of QA where the answer is identified as a span of text in a document.
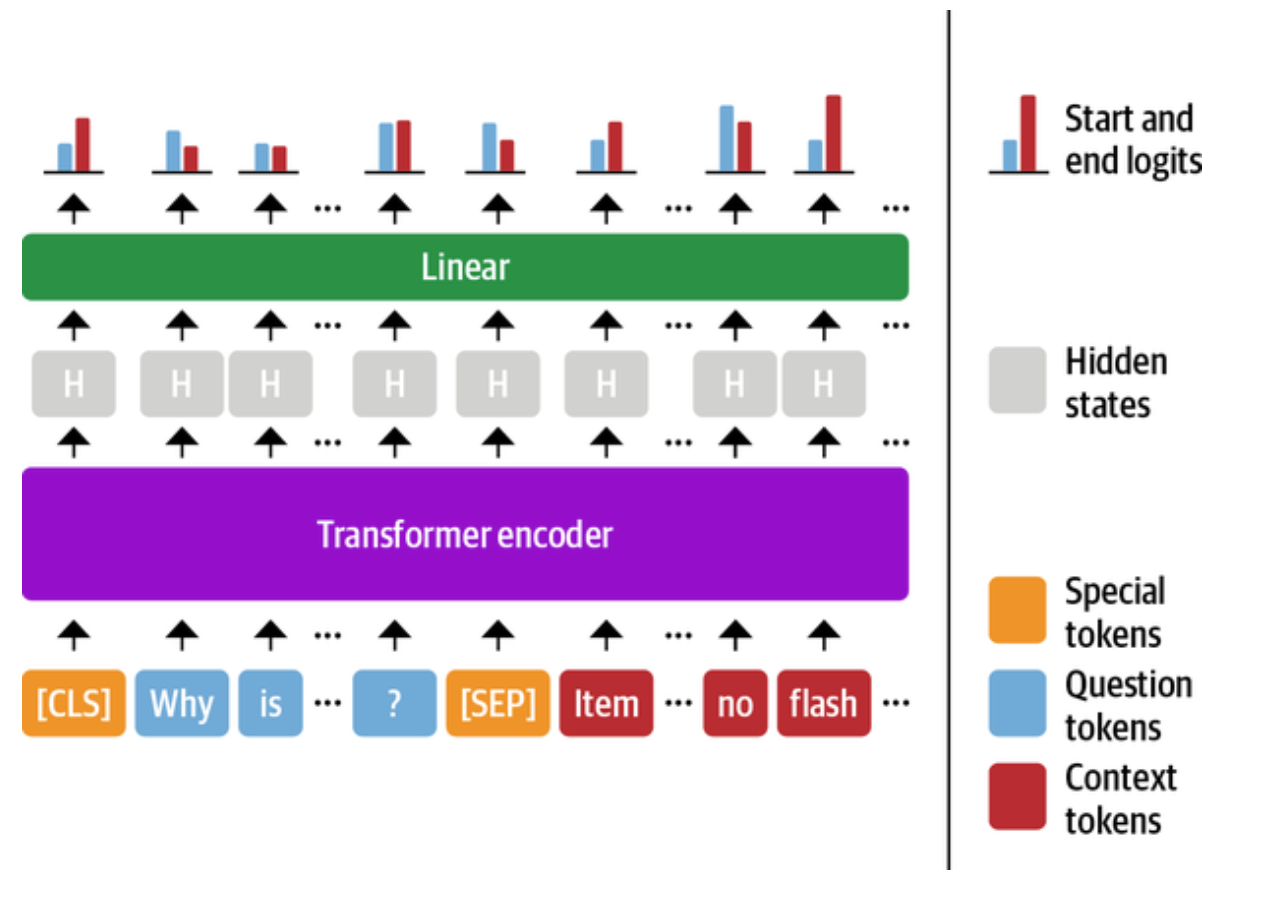
Span Classification
The supervised model should predict the starting and ending position of the answer tokens.
Models which can be used for QA
- MiniLM
- RoBERTa-base
- ALBERT-XXL
- XLM-RoBERTa-large
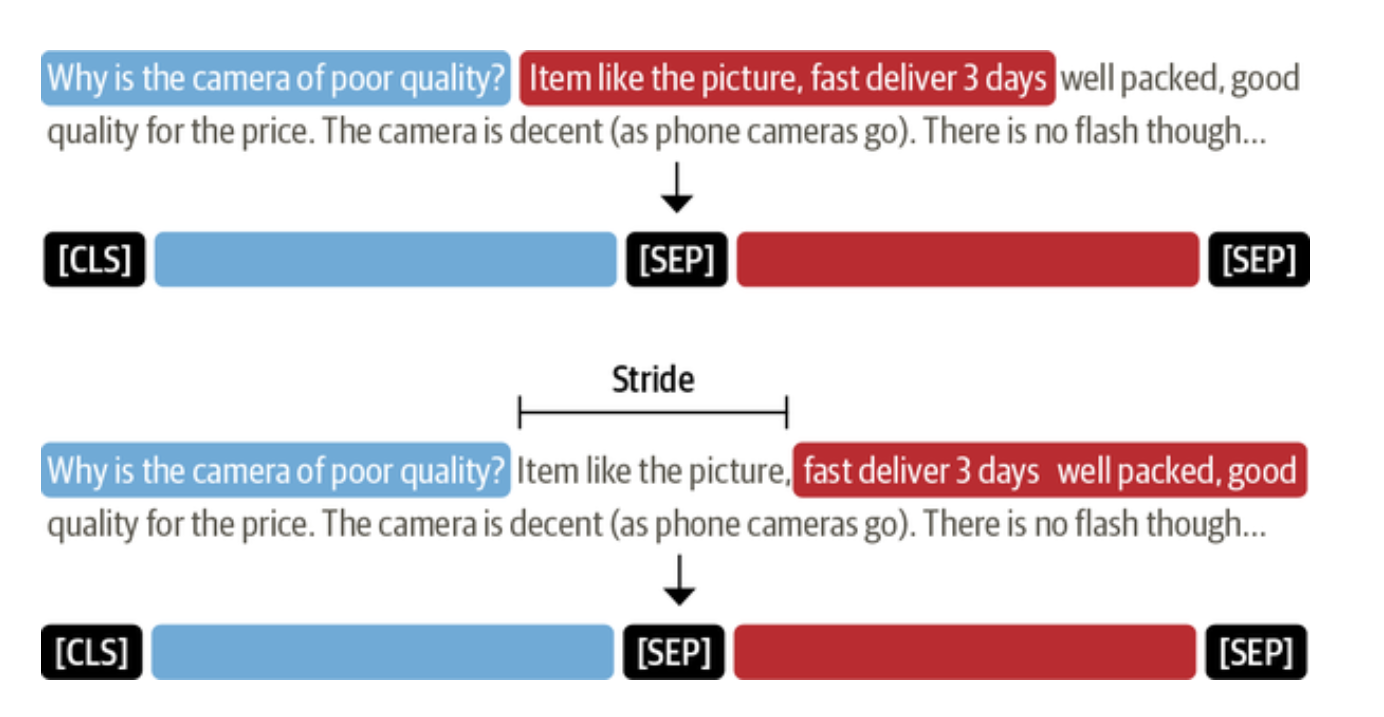
Dealing with long passages
Using sliding windows to deal with long passages
Selecting relevant documents from the database
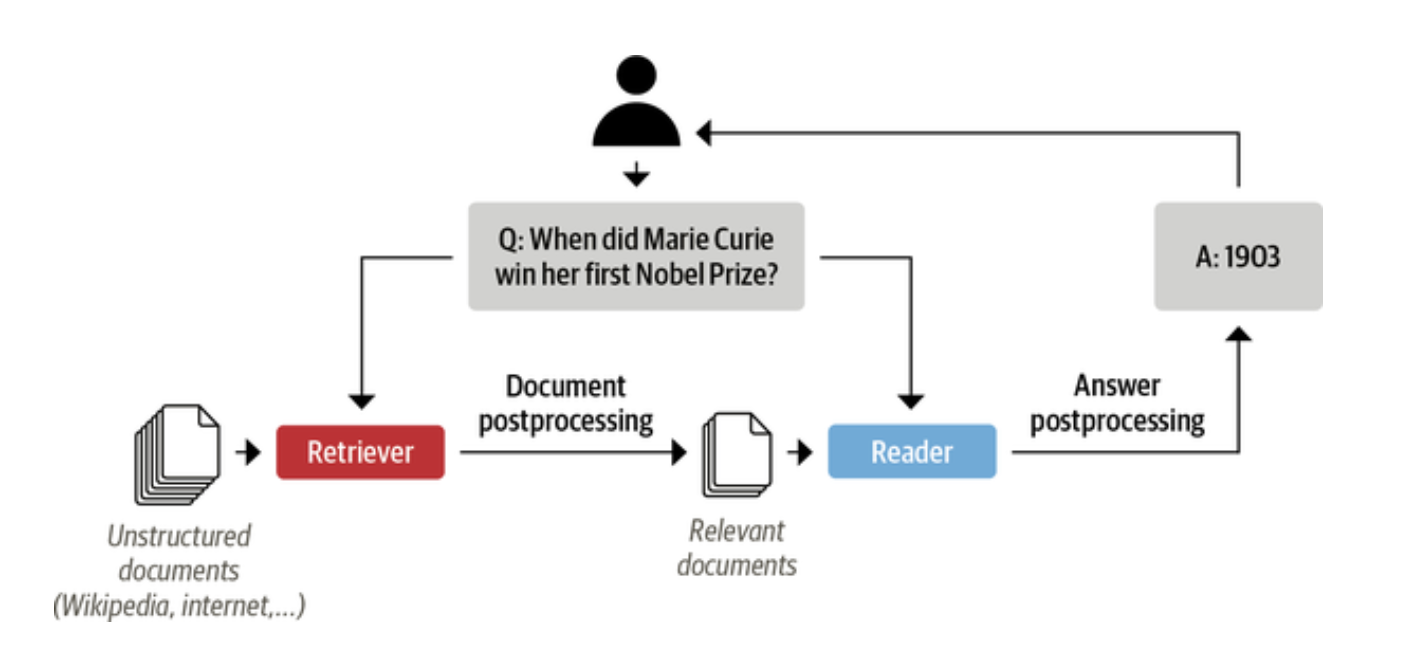
Modern QA systems are based on retriever-reader architecture. Retriever gets the relevant documents for a given query. Retrievers are categorized as sparse or dense. Spare retrievers use word frequencies and dense retrievers use encoders to get contextualized embeddings.
Reader extracts the answer from the documents provided by the retriever. Reader is usually a reading comprehension model
Elasticsearch can be used as a document store. FAISS can also be used as a document store.
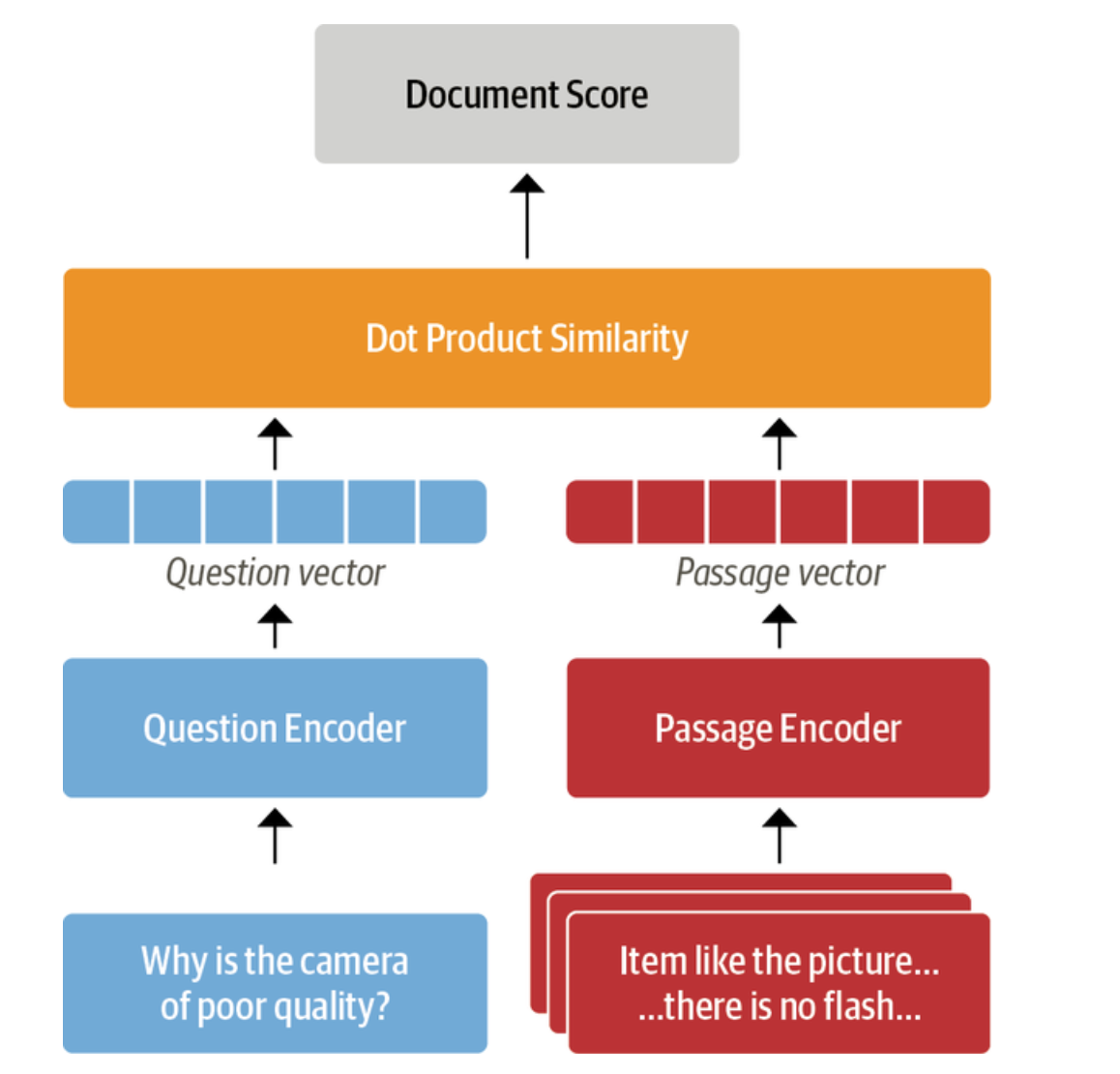
Dense passage retrieval(DPR) uses bi-encoder architecture for computing the relevance of a document and query
Evaluating a retriever
- Recall - The fraction of all relevant documents that are retrieved.
- Mean Average Precision (mAP) - Rewards retrievers that place correct answers higher up in the document ranking.
Evaluating the reader
- Exact Match (EM)
- F1-Score
Exact match is a very strict metric and F1 score is optimistic. Better to track both of them to get a good understanding of the reader performance
Fine-Tuning for domain adaptation
If the domain dataset is very small compared to the data used by pre-trained model, then fine-tuning using only the domain dataset may give less performance boost. Fine-tuning using both the domain and the data used by the pre-trained model is recommended.
Abstractive QA
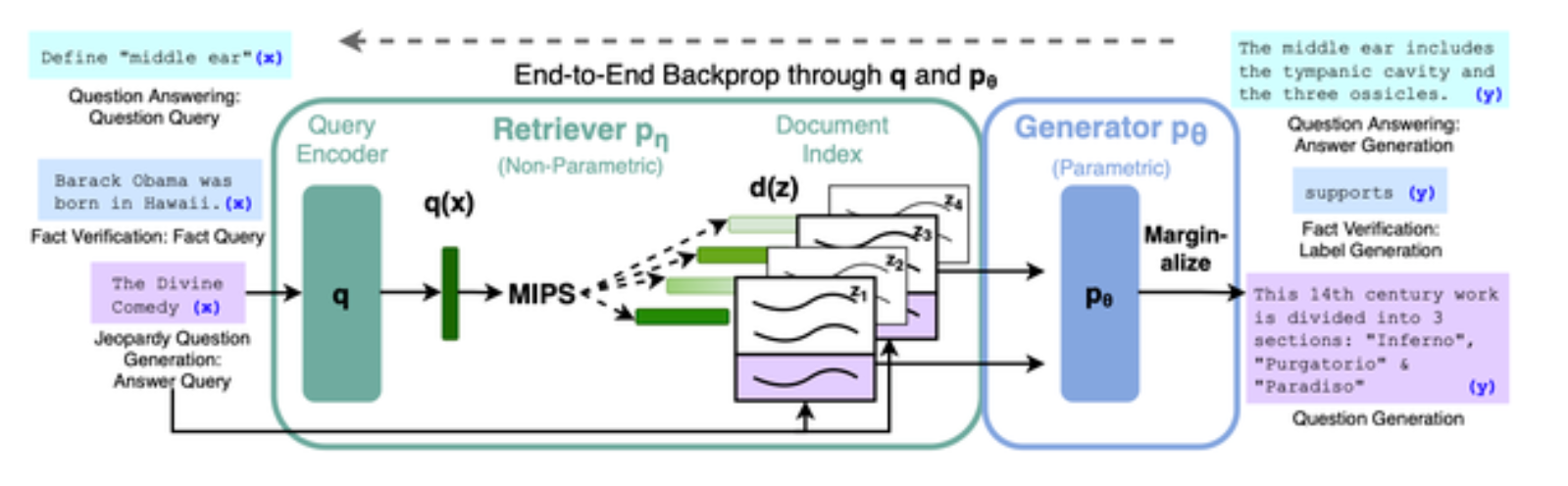
At times, the answer to a question may be distributed across documents and paragraphs. Extractive QA cannot be used in such cases. In such cases the answer can be generated with a pretrained language model. One such model is Retrieval Augmented Generation (RAG)
RAG-Token is a category of RAG model which can use a different document to generate each token in the answer. This allows the generator to synthesize evidence from multiple documents.
QA Hierarchy of needs
To implement QA sytems, we can start with providing user with good search capabilities. Then we can go for extraction based methods followed by answer generation techniques.

Research Directions
- Multimodal QA using text, images, tables etc.
- QA over a knowledge graph