from pyspark.sql.functions import broadcast
from pyspark.sql import SparkSessionSpark Joins
Spark has five distinct join strategies
* Broadcast hash join * Shuffle hash join * Shuffle sort merge join * Broadcast nested loop join * shuffle and replicated nested loop join or cartesian product join
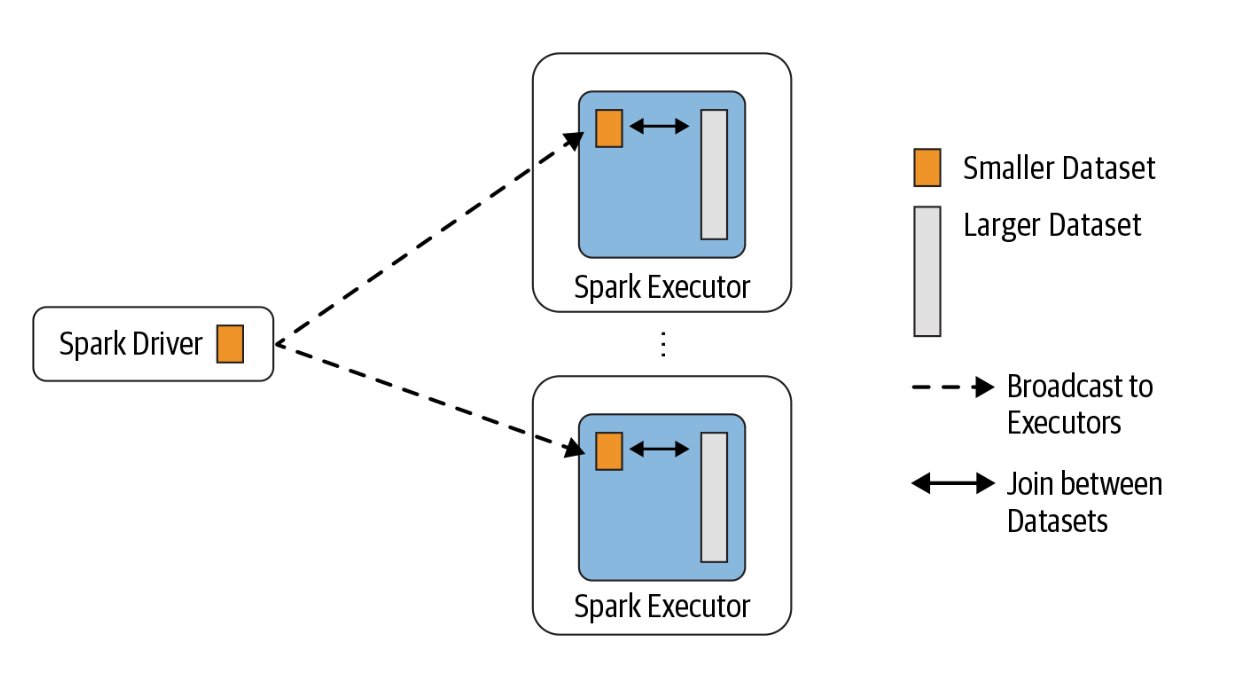
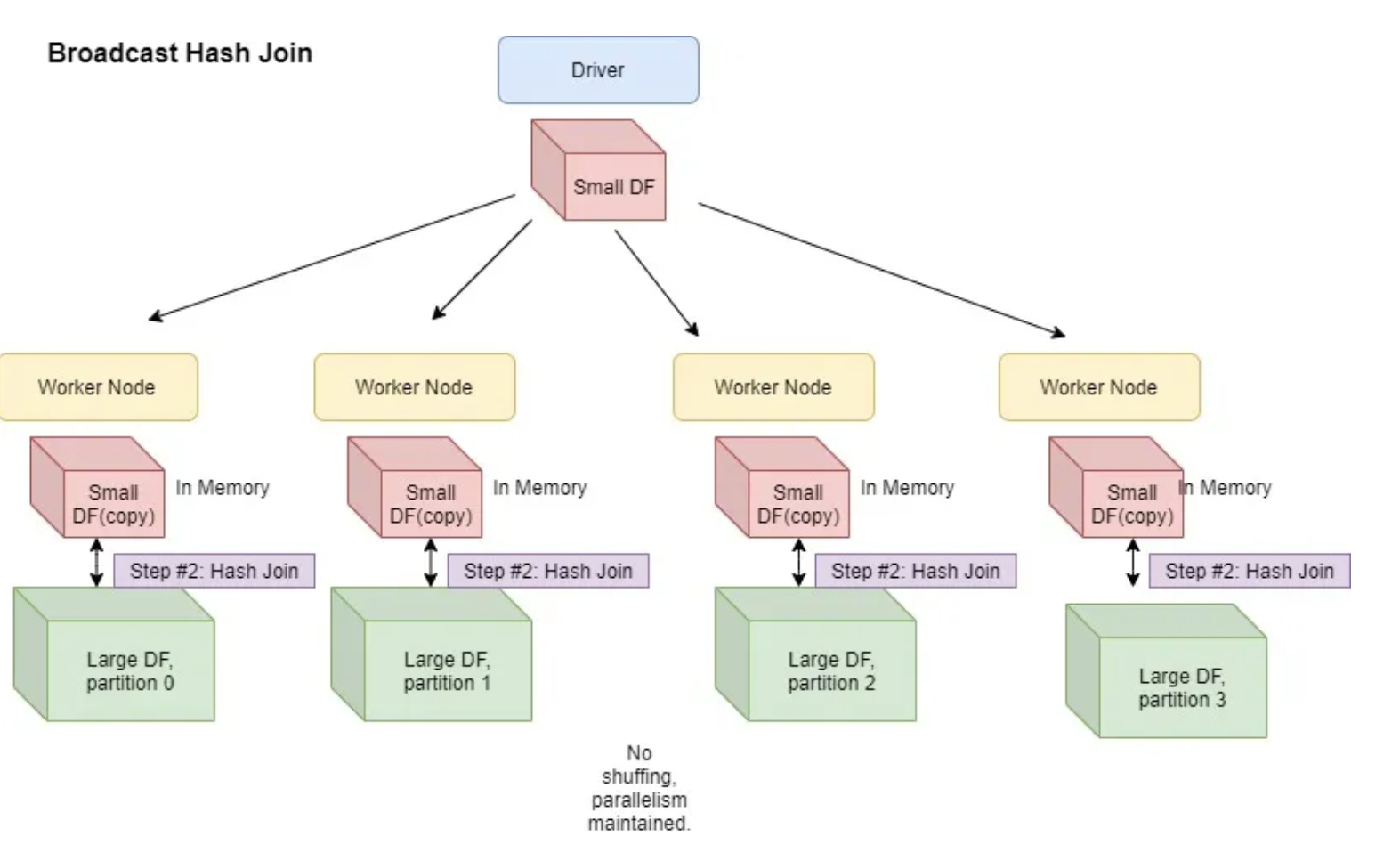
Broadcast Hash Join
- It is employed when we want to join a small dataset with a large dataset
- The smaller dataset is broadcasted by driver to all executors
- Moving the larger dataset is avoided
- By default spark will use broadcast join if the smaller dataset is less than 10 MB
- configuration for broadcast join
spark.sql.autoBroadcastJoinThreshold - We can either increase or decrease the threshold as required
spark = SparkSession.builder.appName('joins').getOrCreate()23/05/06 17:39:52 WARN Utils: Your hostname, thulasiram resolves to a loopback address: 127.0.1.1; using 192.168.0.105 instead (on interface wlp0s20f3)
23/05/06 17:39:52 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another addressSetting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).23/05/06 17:39:53 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicablelargeDF = spark.range(1, 10000)
smallDF = spark.range(1, 100)joinedDF = largeDF.join(smallDF,"id")joinedDF.explain(mode='simple')== Physical Plan ==
AdaptiveSparkPlan isFinalPlan=false
+- Project [id#0L]
+- BroadcastHashJoin [id#0L], [id#2L], Inner, BuildRight, false
:- Range (1, 10000, step=1, splits=16)
+- BroadcastExchange HashedRelationBroadcastMode(List(input[0, bigint, false]),false), [plan_id=16]
+- Range (1, 100, step=1, splits=16)
joinedDF.explain(mode='formatted')== Physical Plan ==
AdaptiveSparkPlan (6)
+- Project (5)
+- BroadcastHashJoin Inner BuildRight (4)
:- Range (1)
+- BroadcastExchange (3)
+- Range (2)
(1) Range
Output [1]: [id#0L]
Arguments: Range (1, 10000, step=1, splits=Some(16))
(2) Range
Output [1]: [id#2L]
Arguments: Range (1, 100, step=1, splits=Some(16))
(3) BroadcastExchange
Input [1]: [id#2L]
Arguments: HashedRelationBroadcastMode(List(input[0, bigint, false]),false), [plan_id=16]
(4) BroadcastHashJoin
Left keys [1]: [id#0L]
Right keys [1]: [id#2L]
Join condition: None
(5) Project
Output [1]: [id#0L]
Input [2]: [id#0L, id#2L]
(6) AdaptiveSparkPlan
Output [1]: [id#0L]
Arguments: isFinalPlan=false
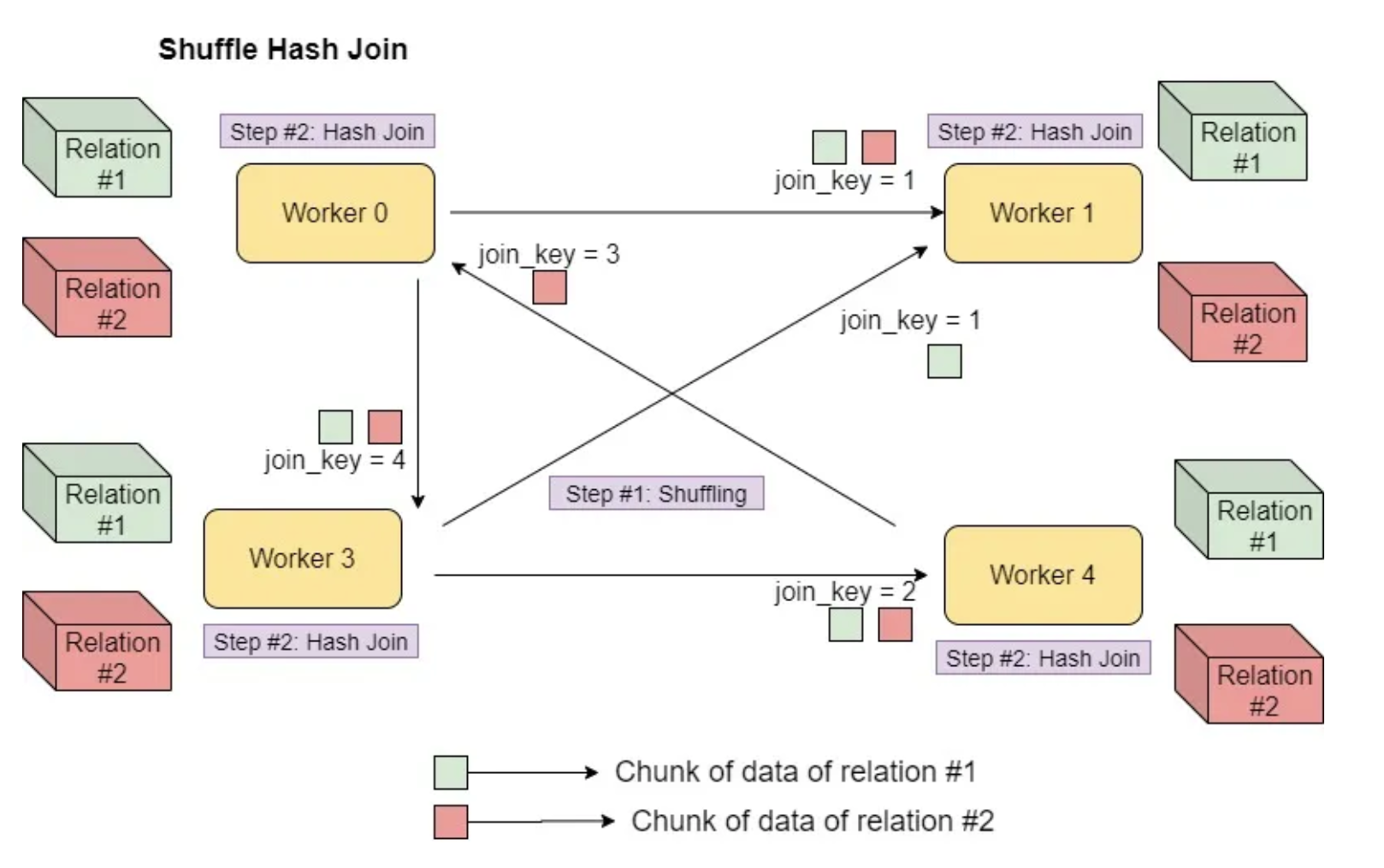
Shuffle Hash Join
- Moving the data with the same value of join key in the same executor node
- Followed by hash join
- Join key does not need to be sortable
- Expensive join that involves both shuffling and Hashing
Shuffle Sort Merge Join
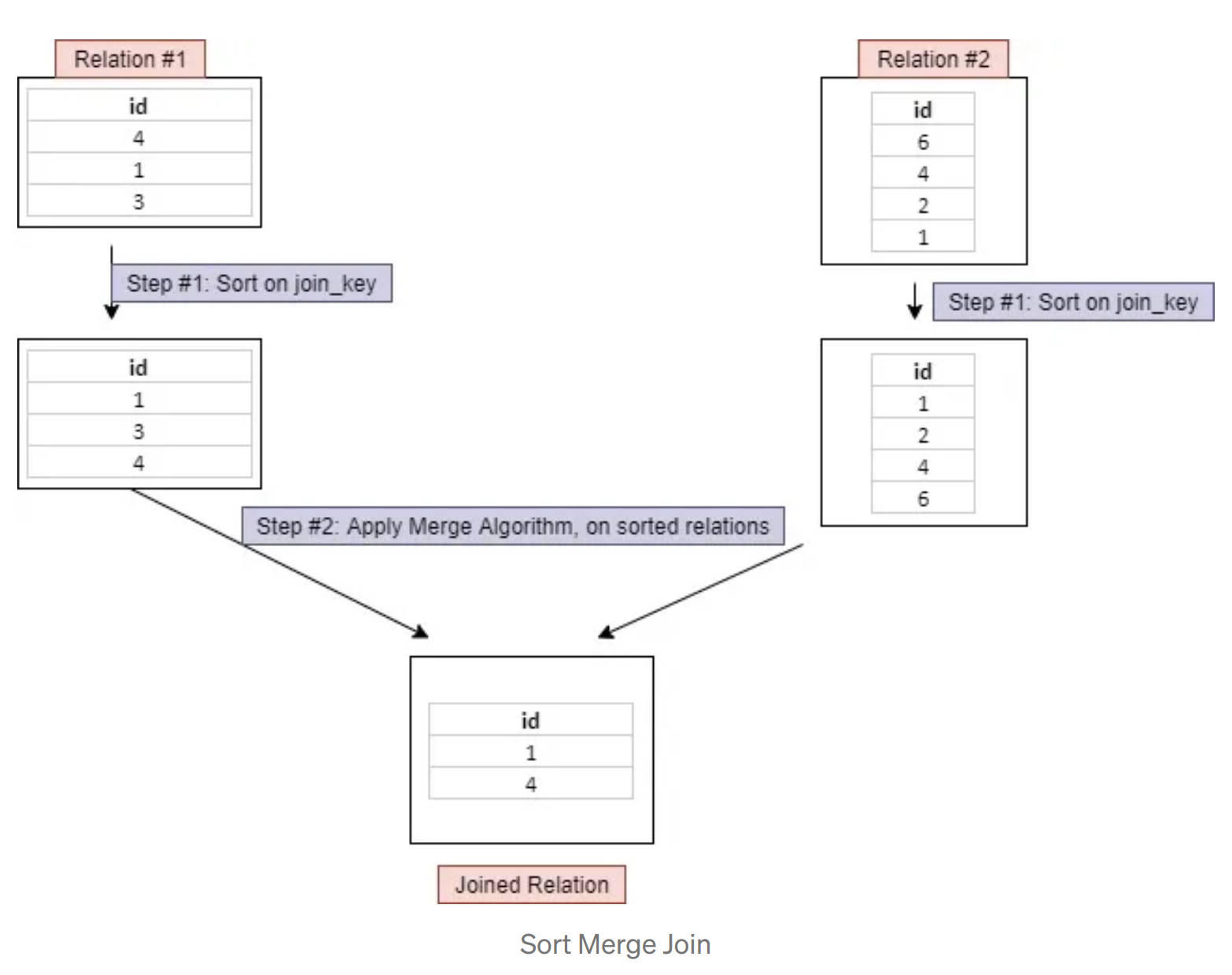
- Shuffle sort-merge join involves shuffling of data to get the same join_key with the same worker
- sort-merge join operation at the partition level in the worker nodes
- The join keys need to be sortable
- sortMergeJoin is enabled via
spark.sql.join.preferSortMergeJoin - Default Join in spark
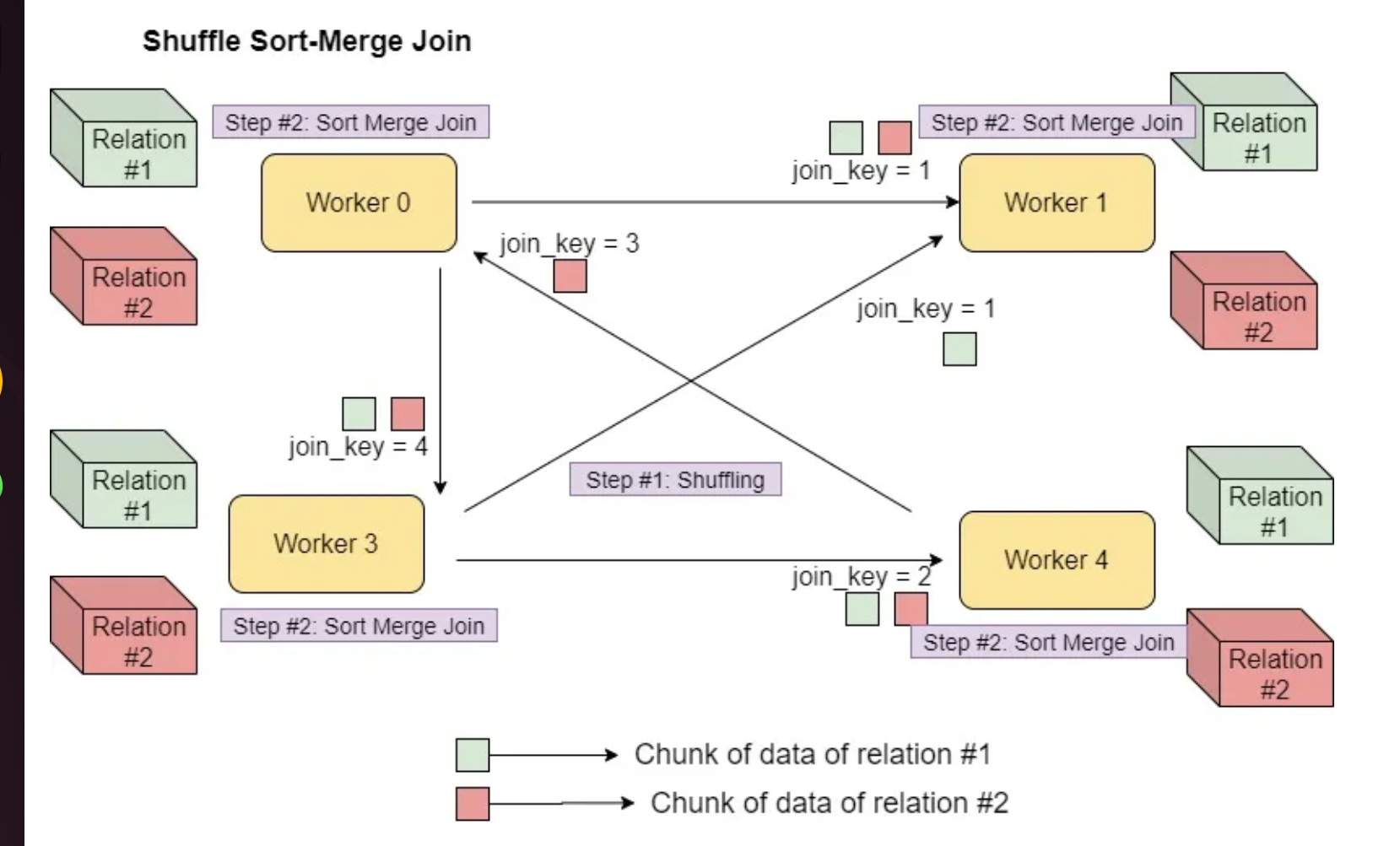
Optimizing Shuffle Sort Merge Join
- Bucketing is an optimization technqiue
- Using Bucketing to determine data partitioning and avoid data shuffle
- use
bucketBymethod on the datasets so that keys are co-located - The number of buckets and the bucketing columns have to be the same across DataFrames participating in join
largeDF =spark.range(1, 100000)
smallDF = spark.range(1, 1000)# Bucket the dataframe
(largeDF.write.bucketBy(12, "id")
.sortBy("id")
.saveAsTable("largeTable")
)
(smallDF.write.bucketBy(12, "id")
.sortBy("id")
.saveAsTable("smallTable"))[Stage 0:> (0 + 16) / 16]23/05/06 18:39:05 WARN MemoryManager: Total allocation exceeds 95.00% (1,020,054,720 bytes) of heap memory
Scaling row group sizes to 95.00% for 8 writers
23/05/06 18:39:05 WARN MemoryManager: Total allocation exceeds 95.00% (1,020,054,720 bytes) of heap memory
Scaling row group sizes to 84.44% for 9 writers
23/05/06 18:39:05 WARN MemoryManager: Total allocation exceeds 95.00% (1,020,054,720 bytes) of heap memory
Scaling row group sizes to 76.00% for 10 writers
23/05/06 18:39:05 WARN MemoryManager: Total allocation exceeds 95.00% (1,020,054,720 bytes) of heap memory
Scaling row group sizes to 69.09% for 11 writers
23/05/06 18:39:05 WARN MemoryManager: Total allocation exceeds 95.00% (1,020,054,720 bytes) of heap memory
Scaling row group sizes to 63.33% for 12 writers
23/05/06 18:39:05 WARN MemoryManager: Total allocation exceeds 95.00% (1,020,054,720 bytes) of heap memory
Scaling row group sizes to 58.46% for 13 writers
23/05/06 18:39:05 WARN MemoryManager: Total allocation exceeds 95.00% (1,020,054,720 bytes) of heap memory
Scaling row group sizes to 54.29% for 14 writers
23/05/06 18:39:05 WARN MemoryManager: Total allocation exceeds 95.00% (1,020,054,720 bytes) of heap memory
Scaling row group sizes to 50.67% for 15 writers
23/05/06 18:39:05 WARN MemoryManager: Total allocation exceeds 95.00% (1,020,054,720 bytes) of heap memory
Scaling row group sizes to 47.50% for 16 writers
23/05/06 18:39:05 WARN MemoryManager: Total allocation exceeds 95.00% (1,020,054,720 bytes) of heap memory
Scaling row group sizes to 50.67% for 15 writers
23/05/06 18:39:05 WARN MemoryManager: Total allocation exceeds 95.00% (1,020,054,720 bytes) of heap memory
Scaling row group sizes to 54.29% for 14 writers
23/05/06 18:39:05 WARN MemoryManager: Total allocation exceeds 95.00% (1,020,054,720 bytes) of heap memory
Scaling row group sizes to 58.46% for 13 writers
23/05/06 18:39:05 WARN MemoryManager: Total allocation exceeds 95.00% (1,020,054,720 bytes) of heap memory
Scaling row group sizes to 63.33% for 12 writers
23/05/06 18:39:05 WARN MemoryManager: Total allocation exceeds 95.00% (1,020,054,720 bytes) of heap memory
Scaling row group sizes to 69.09% for 11 writers
23/05/06 18:39:05 WARN MemoryManager: Total allocation exceeds 95.00% (1,020,054,720 bytes) of heap memory
Scaling row group sizes to 76.00% for 10 writers
23/05/06 18:39:05 WARN MemoryManager: Total allocation exceeds 95.00% (1,020,054,720 bytes) of heap memory
Scaling row group sizes to 84.44% for 9 writers
23/05/06 18:39:05 WARN MemoryManager: Total allocation exceeds 95.00% (1,020,054,720 bytes) of heap memory
Scaling row group sizes to 95.00% for 8 writers
23/05/06 18:39:05 WARN MemoryManager: Total allocation exceeds 95.00% (1,020,054,720 bytes) of heap memory
Scaling row group sizes to 95.00% for 8 writers
23/05/06 18:39:05 WARN MemoryManager: Total allocation exceeds 95.00% (1,020,054,720 bytes) of heap memory
Scaling row group sizes to 84.44% for 9 writers
23/05/06 18:39:05 WARN MemoryManager: Total allocation exceeds 95.00% (1,020,054,720 bytes) of heap memory
Scaling row group sizes to 95.00% for 8 writers
23/05/06 18:39:05 WARN MemoryManager: Total allocation exceeds 95.00% (1,020,054,720 bytes) of heap memory
Scaling row group sizes to 84.44% for 9 writers
23/05/06 18:39:05 WARN MemoryManager: Total allocation exceeds 95.00% (1,020,054,720 bytes) of heap memory
Scaling row group sizes to 76.00% for 10 writers
23/05/06 18:39:05 WARN MemoryManager: Total allocation exceeds 95.00% (1,020,054,720 bytes) of heap memory
Scaling row group sizes to 69.09% for 11 writers
23/05/06 18:39:05 WARN MemoryManager: Total allocation exceeds 95.00% (1,020,054,720 bytes) of heap memory
Scaling row group sizes to 76.00% for 10 writers
23/05/06 18:39:05 WARN MemoryManager: Total allocation exceeds 95.00% (1,020,054,720 bytes) of heap memory
Scaling row group sizes to 84.44% for 9 writers
23/05/06 18:39:05 WARN MemoryManager: Total allocation exceeds 95.00% (1,020,054,720 bytes) of heap memory
Scaling row group sizes to 76.00% for 10 writers
23/05/06 18:39:05 WARN MemoryManager: Total allocation exceeds 95.00% (1,020,054,720 bytes) of heap memory
Scaling row group sizes to 84.44% for 9 writers
23/05/06 18:39:05 WARN MemoryManager: Total allocation exceeds 95.00% (1,020,054,720 bytes) of heap memory
Scaling row group sizes to 95.00% for 8 writers
23/05/06 18:39:05 WARN MemoryManager: Total allocation exceeds 95.00% (1,020,054,720 bytes) of heap memory
Scaling row group sizes to 95.00% for 8 writers 23/05/06 18:39:06 WARN MemoryManager: Total allocation exceeds 95.00% (1,020,054,720 bytes) of heap memory
Scaling row group sizes to 95.00% for 8 writers
23/05/06 18:39:06 WARN MemoryManager: Total allocation exceeds 95.00% (1,020,054,720 bytes) of heap memory
Scaling row group sizes to 95.00% for 8 writers
23/05/06 18:39:06 WARN MemoryManager: Total allocation exceeds 95.00% (1,020,054,720 bytes) of heap memory
Scaling row group sizes to 84.44% for 9 writers
23/05/06 18:39:06 WARN MemoryManager: Total allocation exceeds 95.00% (1,020,054,720 bytes) of heap memory
Scaling row group sizes to 95.00% for 8 writers
23/05/06 18:39:06 WARN MemoryManager: Total allocation exceeds 95.00% (1,020,054,720 bytes) of heap memory
Scaling row group sizes to 95.00% for 8 writers
23/05/06 18:39:06 WARN MemoryManager: Total allocation exceeds 95.00% (1,020,054,720 bytes) of heap memory
Scaling row group sizes to 95.00% for 8 writers # Read the bucketed tables
bucketedLargeDF = spark.read.table("largeTable")
bucketedSmallDF = spark.read.table("smallTable")spark.conf.set("spark.sql.autoBroadcastJoinThreshold", -1)joinedDF = bucketedLargeDF.join(bucketedSmallDF, "id")joinedDF.explain(mode='extended')== Parsed Logical Plan ==
'Join UsingJoin(Inner,Buffer(id))
:- SubqueryAlias spark_catalog.default.largetable
: +- Relation default.largetable[id#12L] parquet
+- SubqueryAlias spark_catalog.default.smalltable
+- Relation default.smalltable[id#14L] parquet
== Analyzed Logical Plan ==
id: bigint
Project [id#12L]
+- Join Inner, (id#12L = id#14L)
:- SubqueryAlias spark_catalog.default.largetable
: +- Relation default.largetable[id#12L] parquet
+- SubqueryAlias spark_catalog.default.smalltable
+- Relation default.smalltable[id#14L] parquet
== Optimized Logical Plan ==
Project [id#12L]
+- Join Inner, (id#12L = id#14L)
:- Filter isnotnull(id#12L)
: +- Relation default.largetable[id#12L] parquet
+- Filter isnotnull(id#14L)
+- Relation default.smalltable[id#14L] parquet
== Physical Plan ==
AdaptiveSparkPlan isFinalPlan=false
+- Project [id#12L]
+- SortMergeJoin [id#12L], [id#14L], Inner
:- Sort [id#12L ASC NULLS FIRST], false, 0
: +- Filter isnotnull(id#12L)
: +- FileScan parquet default.largetable[id#12L] Batched: true, Bucketed: true, DataFilters: [isnotnull(id#12L)], Format: Parquet, Location: InMemoryFileIndex(1 paths)[file:/home/thulasiram/personal/data_engineering/spark/pyspark/spark-wa..., PartitionFilters: [], PushedFilters: [IsNotNull(id)], ReadSchema: struct<id:bigint>, SelectedBucketsCount: 12 out of 12
+- Sort [id#14L ASC NULLS FIRST], false, 0
+- Filter isnotnull(id#14L)
+- FileScan parquet default.smalltable[id#14L] Batched: true, Bucketed: true, DataFilters: [isnotnull(id#14L)], Format: Parquet, Location: InMemoryFileIndex(1 paths)[file:/home/thulasiram/personal/data_engineering/spark/pyspark/spark-wa..., PartitionFilters: [], PushedFilters: [IsNotNull(id)], ReadSchema: struct<id:bigint>, SelectedBucketsCount: 12 out of 12
Cartesian Join
- The cartesian product of the two relations is calculated
Broadcast nested loop Join
- supports non-equi joins
Slow operation
for record_1 in relation_1: for record_2 in relation_2: # join condition is executed