Transformers from Scratch
Concepts for understanding Transformers
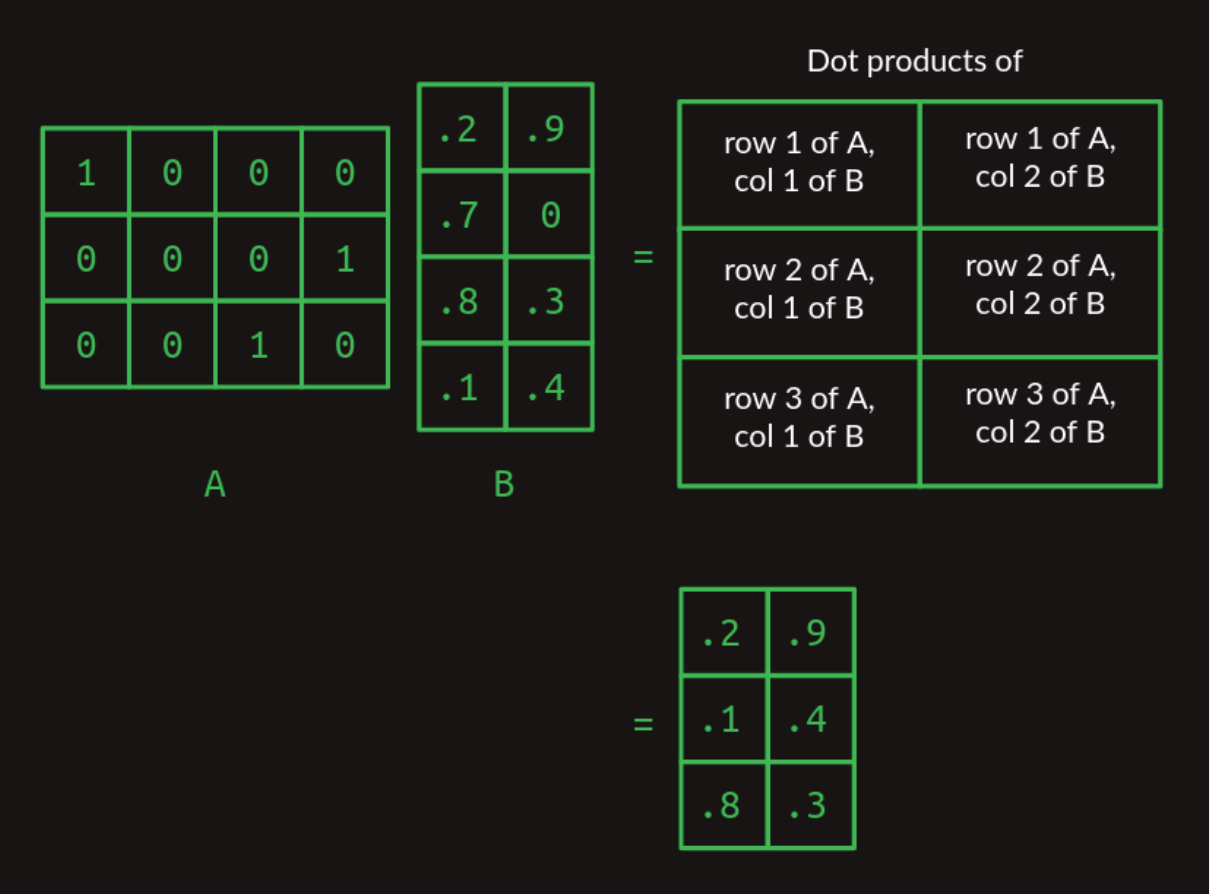
Matrix multiplication as a table lookup
The trick to use one-hot vectors to pull out a particular row of a matrix is at the core of how transformers work.
First order sequence model and one hot vectors
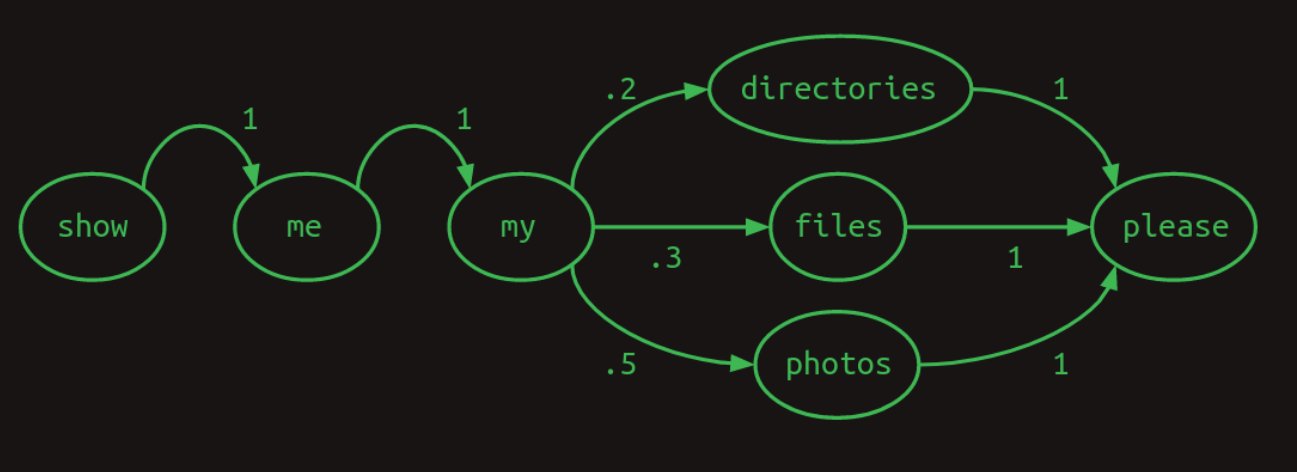
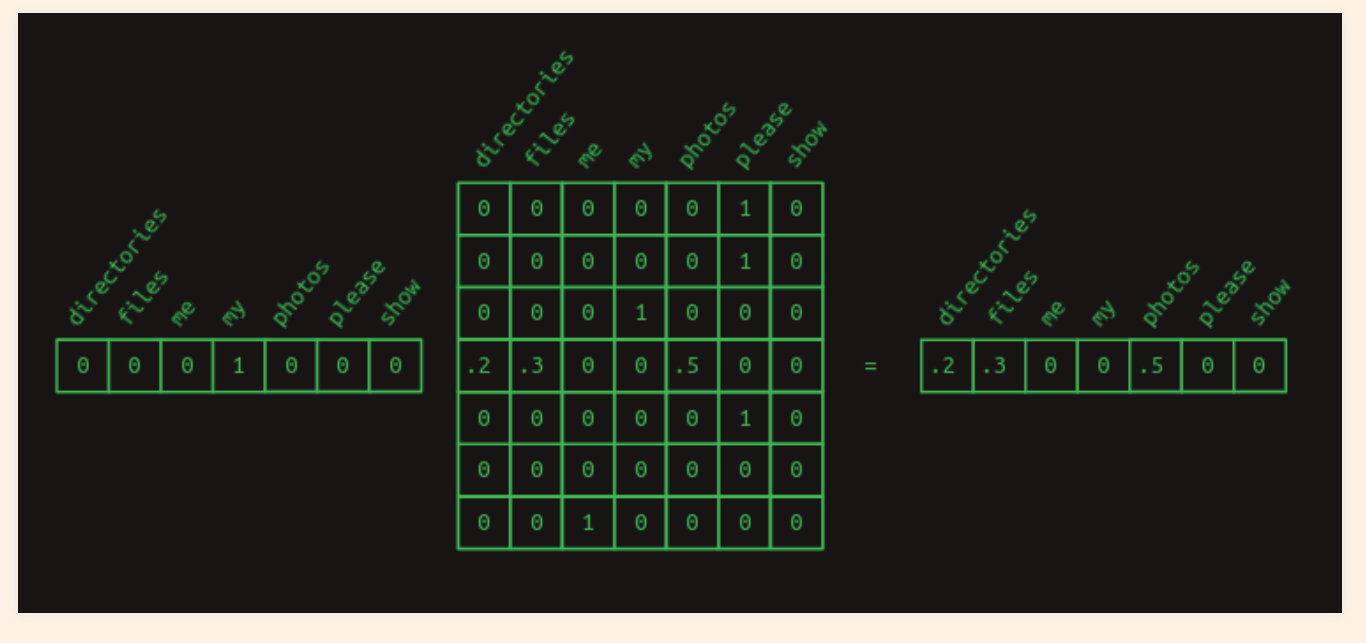
Markov chains can be expressed conveniently in matrix form.

Using one-hot vector to pull out the relevant row and shows the probability distribution of what the next word will be.
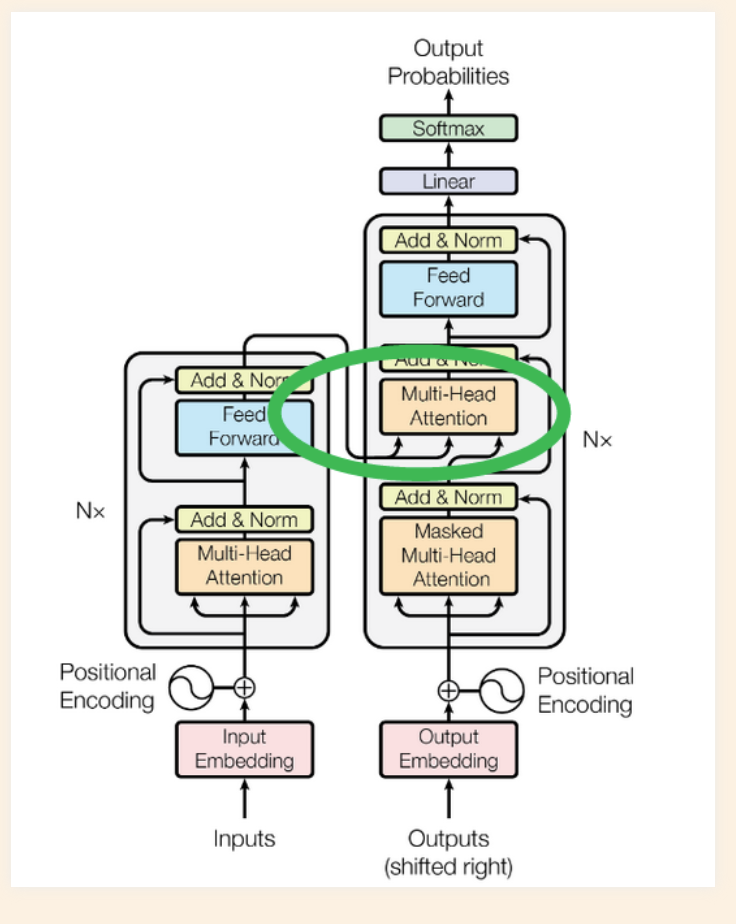
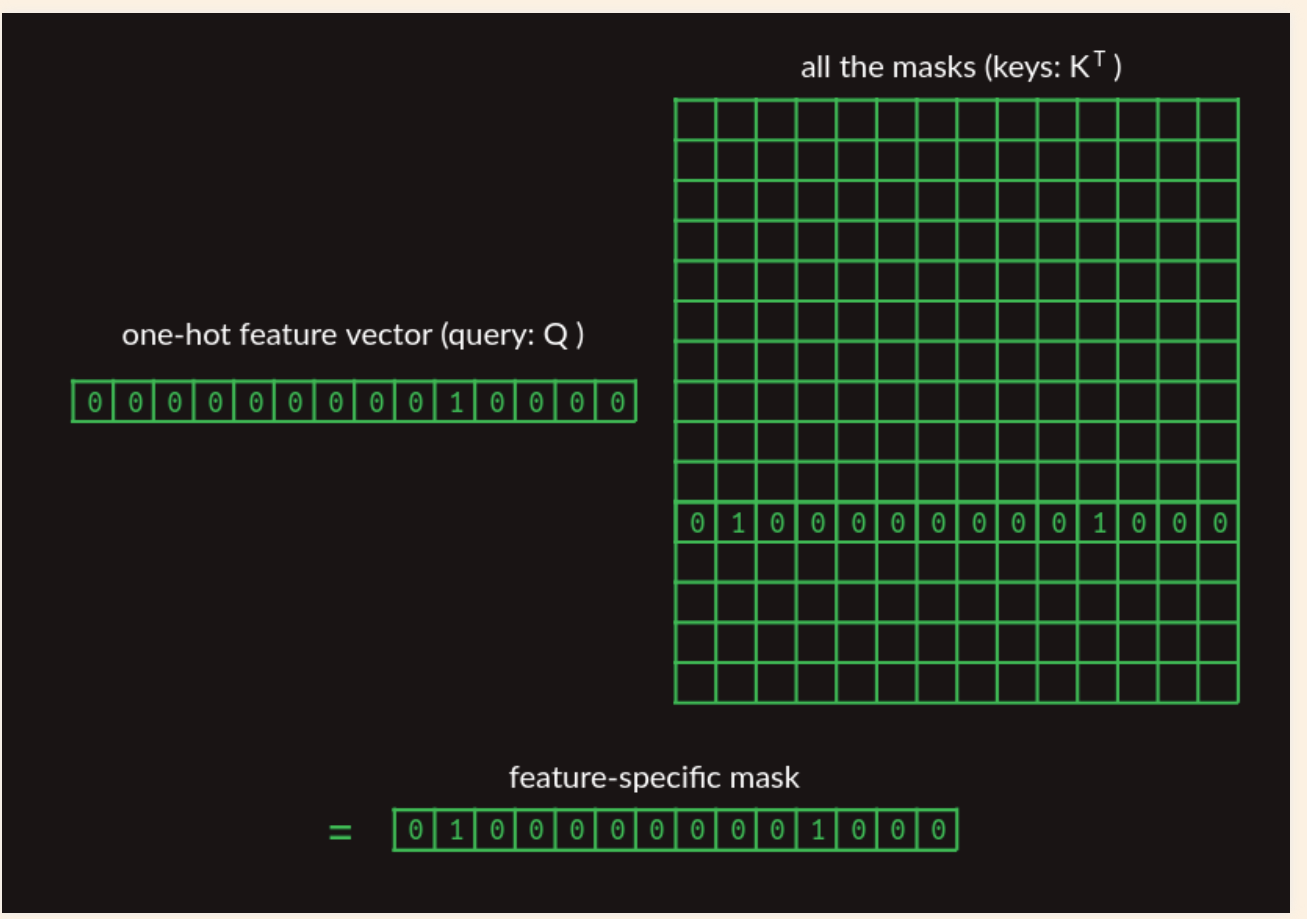
Masking
The mask has the effect of hiding a lot of the transition matrix (which is not relevant for the word combinations)


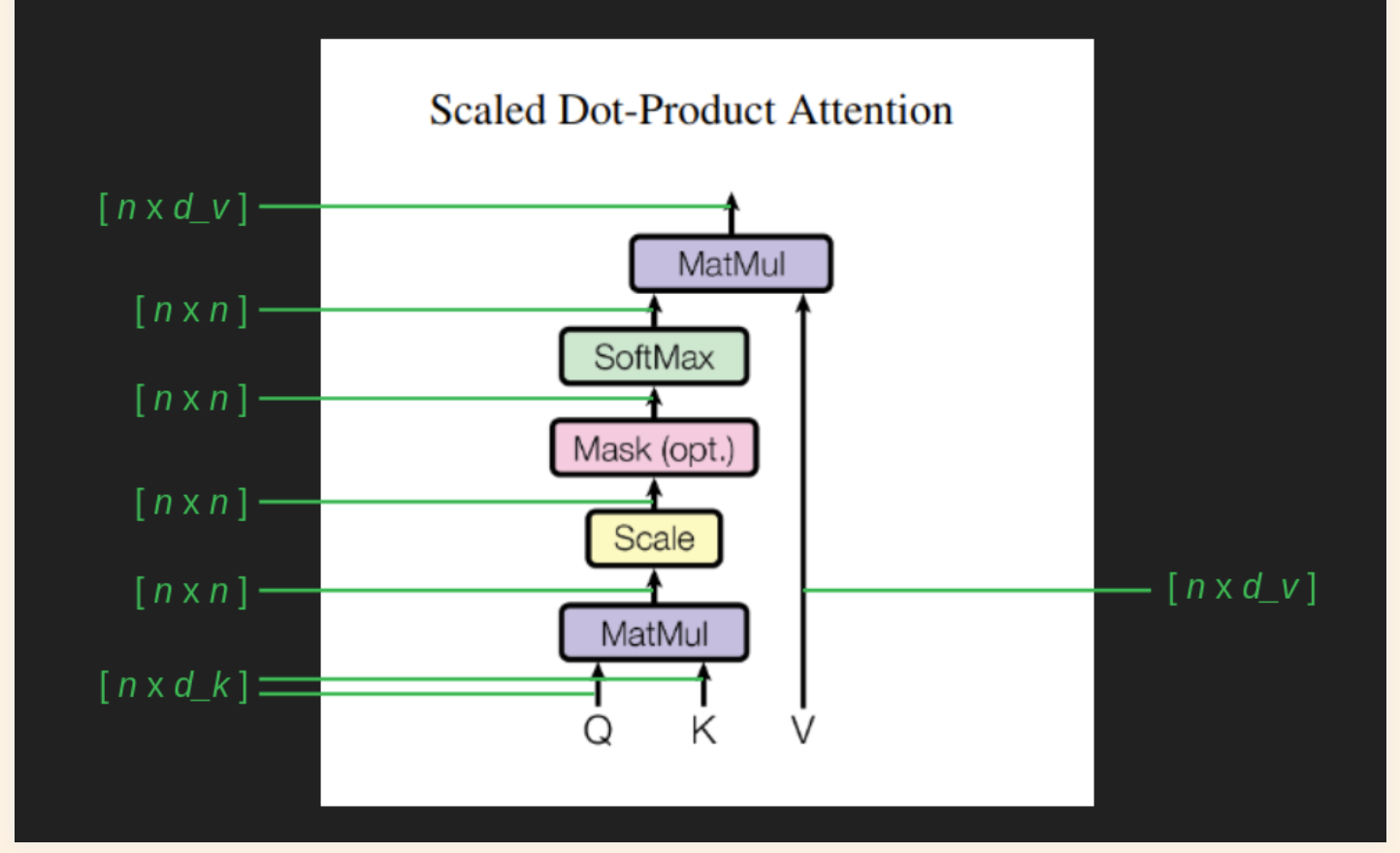
Attention as Matrix Multiplication
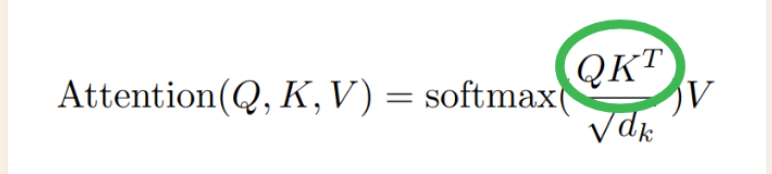
The highlighted piece in the above formula Q represents the feature of interest nad the matrix K represents the collection of masks (which words are important for the given query of interest)
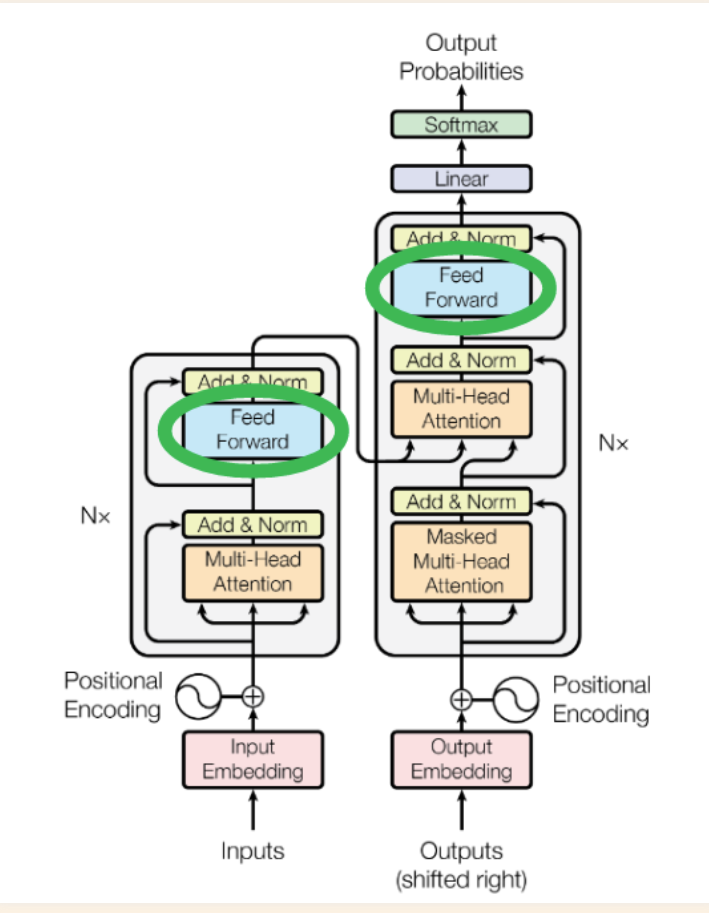
Feed Forward Network
The following happens in Feed Forward Network * Feature creation matrix multiplication * Transition matrix multiplication * ReLU nonlinearity
![]()
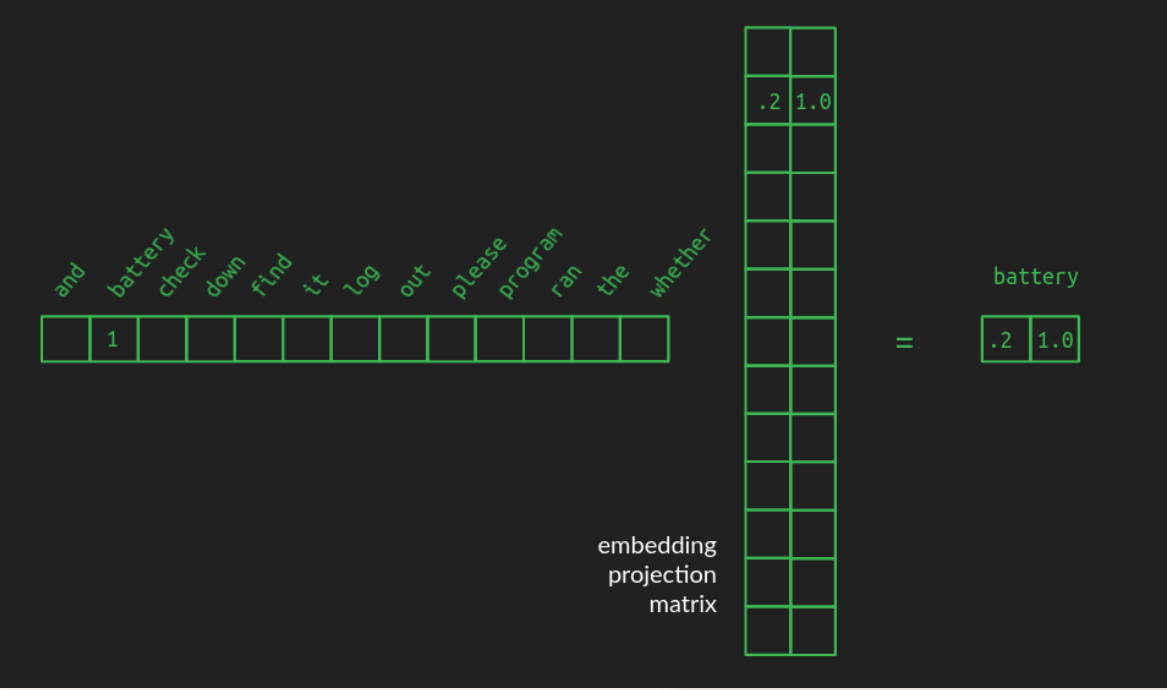
Input Embedding
Embedding can be learned during training
Positional Embedding
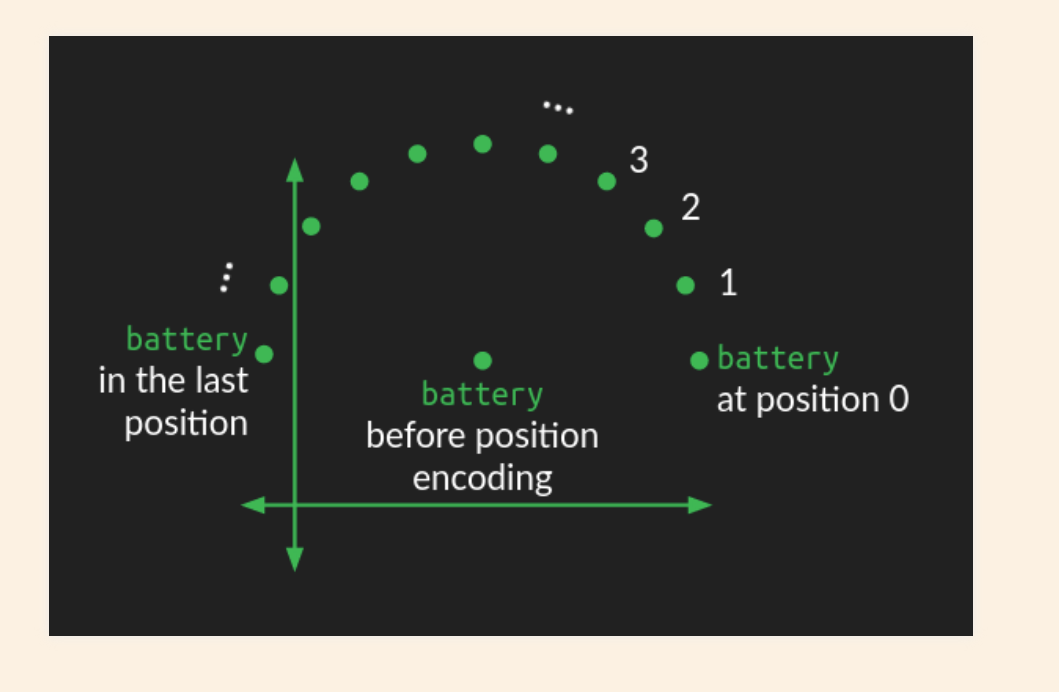
De-embeddings and softmax
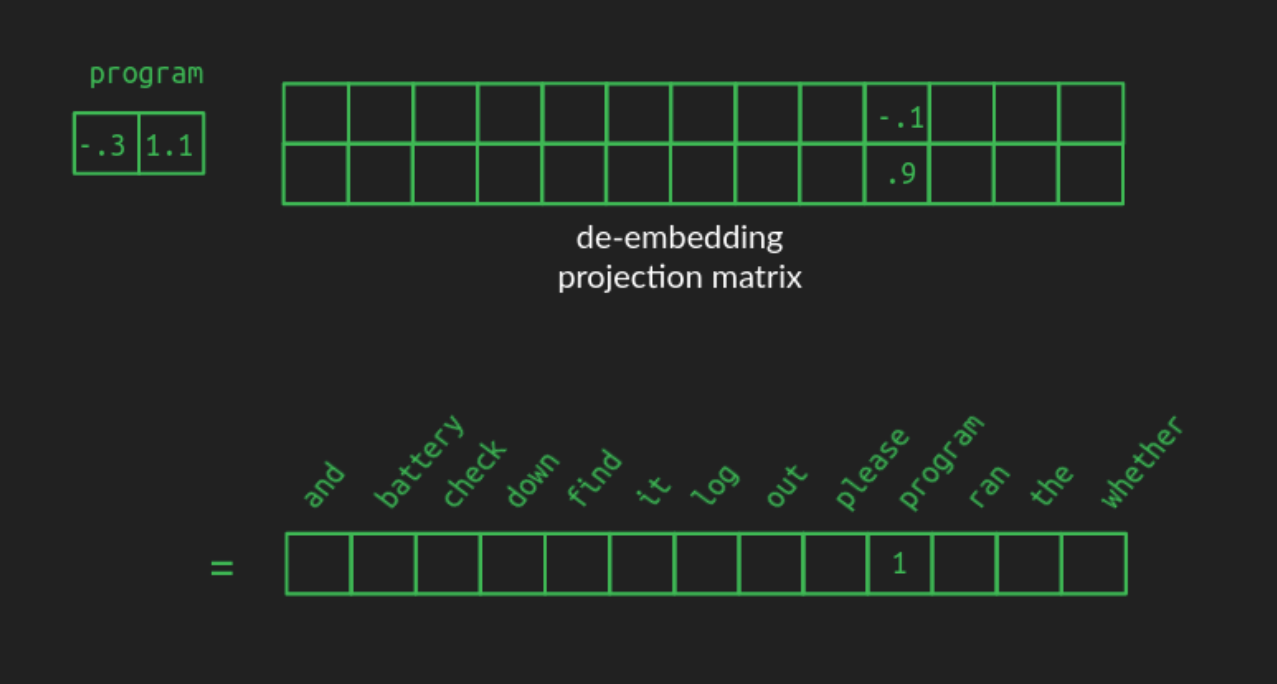
To get the softmax of the value x in a vector, divide the exponential of x, e^x, by the sum of the exponentials of all the values in the vector.
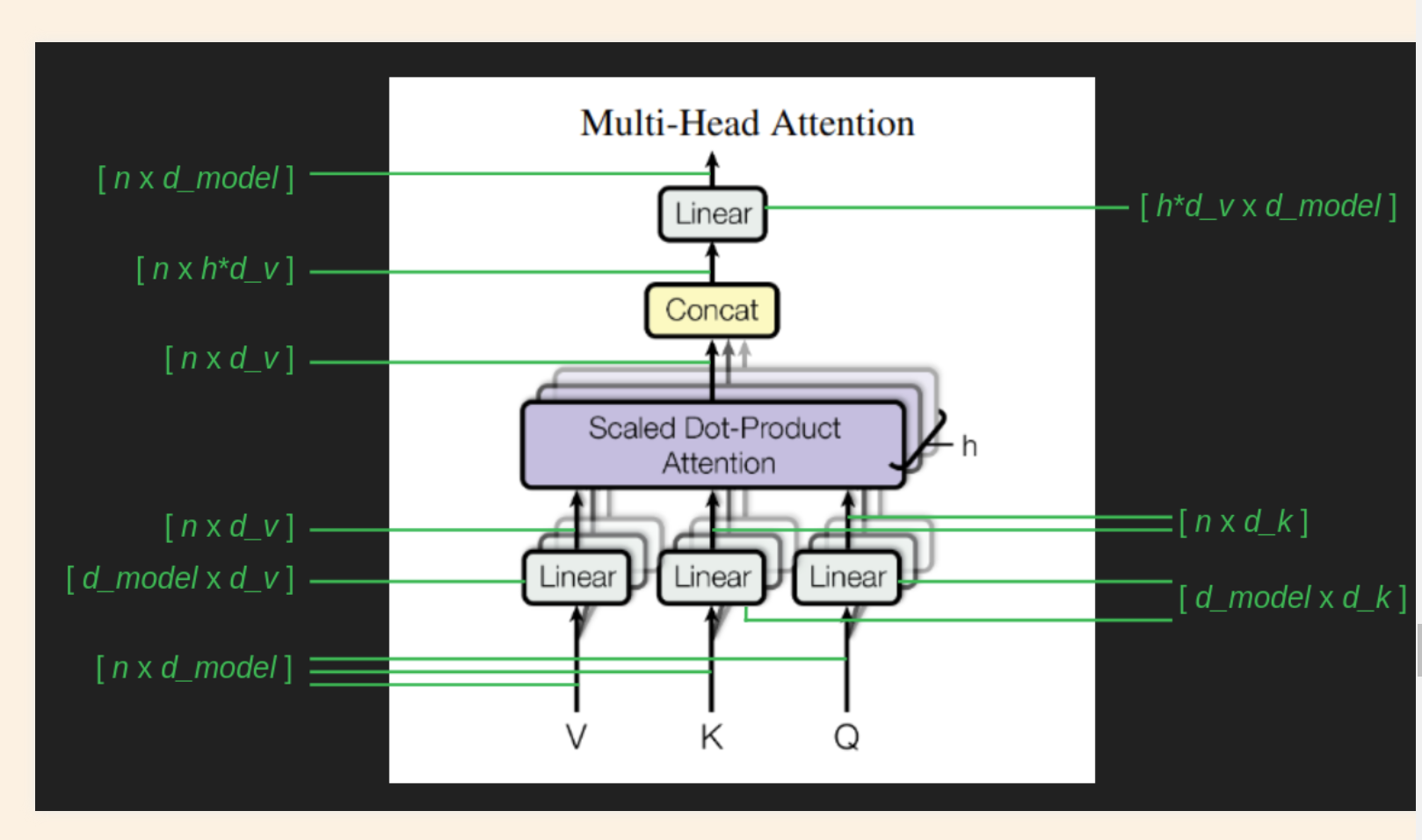
Dimensions of the Matrices
![]()
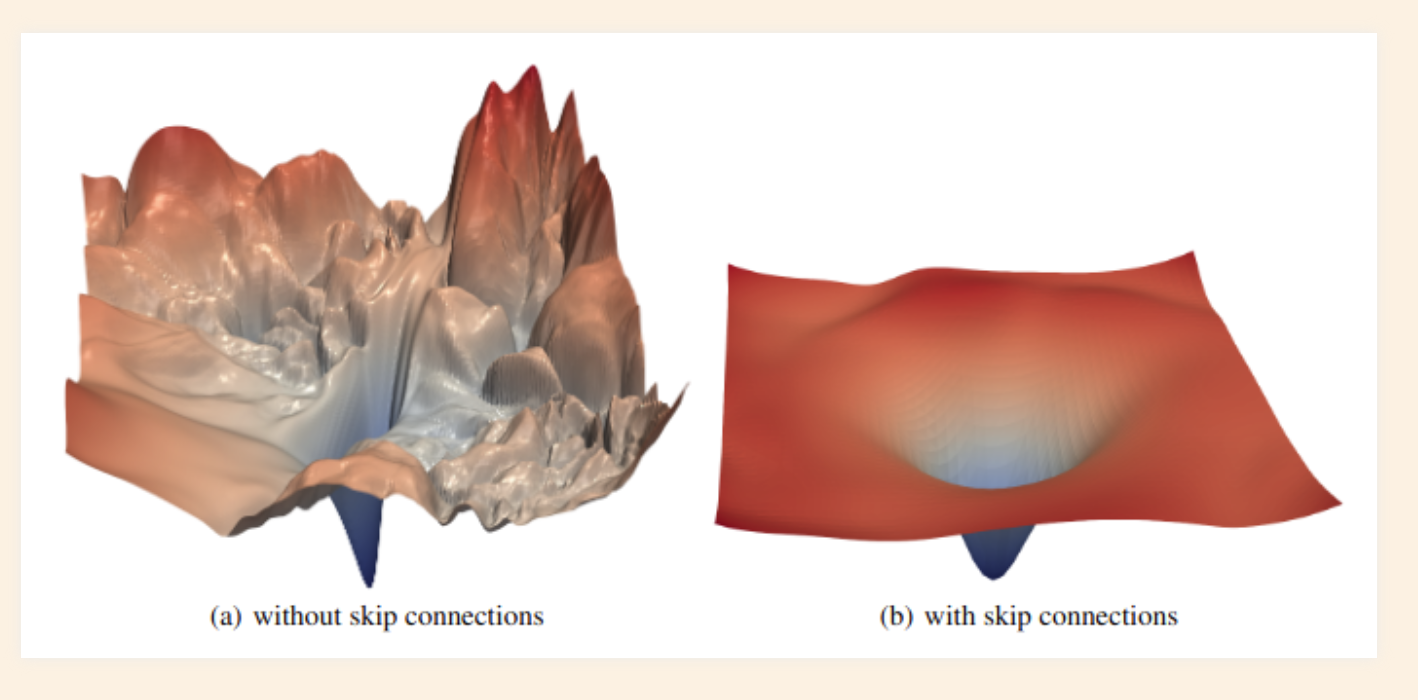
Purpose of Skip connections
- They help keep the gradient smooth
- The second purpose is specific to Transformers - Preserving the original input sequence. Even with a lot of attention heads, there’s no guarantee that a word will attend to its own position. It’s possible for the attention filter to forget entirely about the most recent word in favor of watching all of the earlier words that might be relevant. A skip connection takes the original word and manually adds it back into the signal, so that there’s no way it can be dropped or forgotten.
Layer Normalization
The values of the matrix are shifted to have a mean of zero and scaled to have standard deviation of one
Cross Attention
Cross-attention works just like self-attention with the exception that the key matrix K and value matrix V are based on the output of the final encoder layer, rather than the output of the previous decoder layer. The query matrix Q is still calculated from the results of the previous decoder layer. This is the channel by which information from the source sequence makes its way into the target sequence and steers its creation in the right direction. It’s interesting to note that the same embedded source sequence is provided to every layer of the decoder, supporting the notion that successive layers provide redundancy and are all cooperating to perform the same task.