Making Transformers efficient in Production
Techniques to speed up predictions and reduce the memory footprint of transformer models:-
- Knowledge distillation
- Quantization
- Pruning
- Graph Optimization
Knowledge Distillation
It is a general purpose method for training a smaller student model to mimic the behavior of a slower, larger but better-performing teacher.
For supervised tasks like fine-tuning, the main idea is to augment the ground truth labels with a distribution of “soft probabilities” from the teacher which provide complementary information for the student to learn from. For example, if our BERT-base classifier assigns high probabilities to multiple intents, then this could be a sign that these intents lie close to each other in the feature space. By training the student to mimic these probabilities, the goal is to distill some of this “dark knowledge” that the teacher has learned—that is, knowledge that is not available from the labels alone.
We “soften” the probabilities by scaling the logits with a temperature hyperparameter T before applying the softmax.
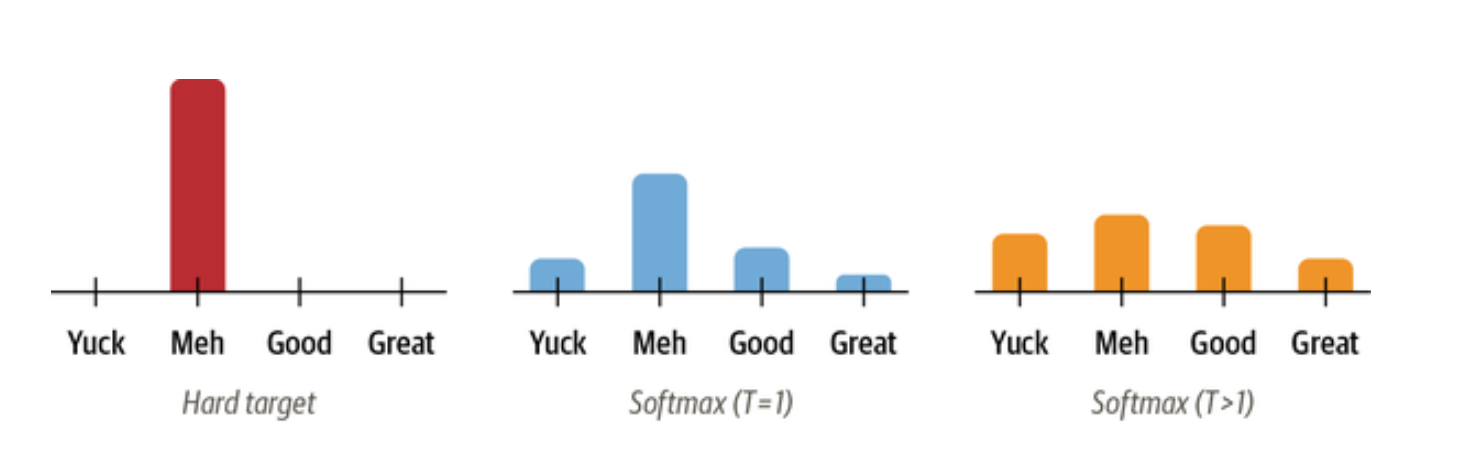
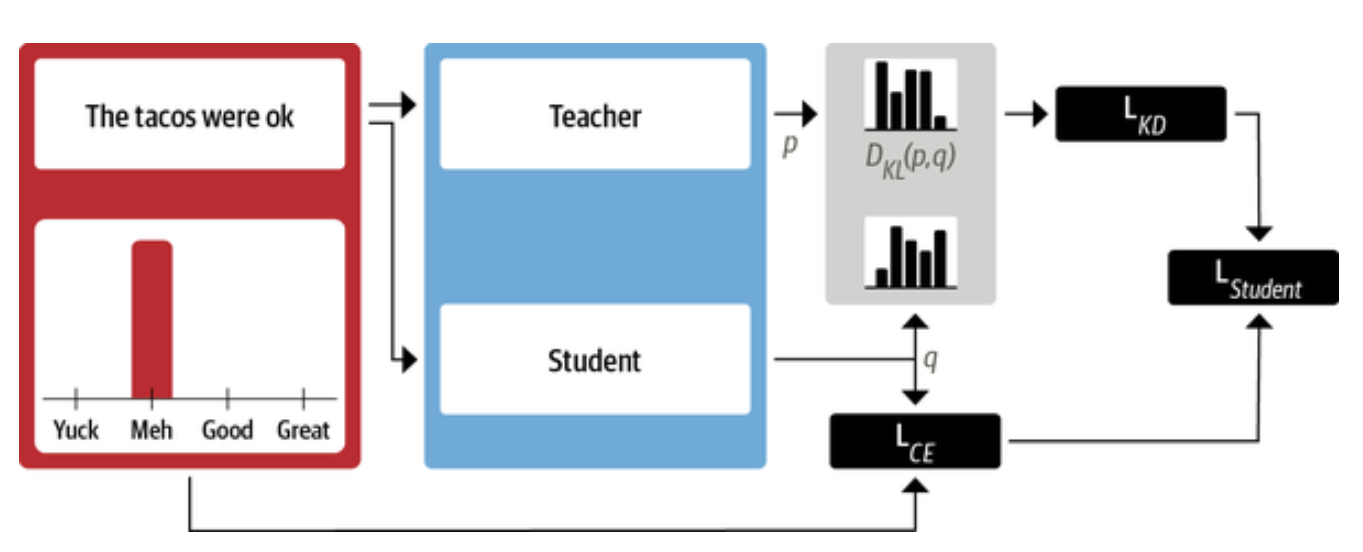
The student also produces softened probabilties of its own. We then measure the Kullback-Leibler (KL) divergence to measure the difference between two probability distributions. Using this we can define knowledge distillation loss.
For classification tasks the student loss is a weighted average of the distillation loss with the usual cross-entropy loss of the ground truth labels.
Rules to select student model
- Select model with fewer parameters and size
- Select model from the same family type as the teacher
Quantization
This makes computation more efficient by representing the weights and activations with low-precision data types.
Three different types of quantization for DNN models:
Dynamic quantization - Quantization happens only during inference. Weights and model’s activation are quantized. Conversion between FP32 and INT8 is a performance bottleneck.
Static quantization - Quantization scheme is decided ahead of inference by taking a sample, calculating the quantization and saving. Challenge of discrepancy between precision during training and inference.
Quantization aware training - The effect of the quantization can be effectively simulated during trainig by “fake” qunatization of the FP32 values. Instead of using INT8 values during training, the FP32 values are rounded to mimic the effect of quantization. This is done during both the forward and the backward pass and improves performance in terms of model metrics over static and dynamic quantization.
The main bottleneck for running inference with transformers is the compute and memory bandwidth associated with the enormous numbers of weights in these models. For this reason, dynamic quantization is currently the best approach for transformer-based models in NLP.
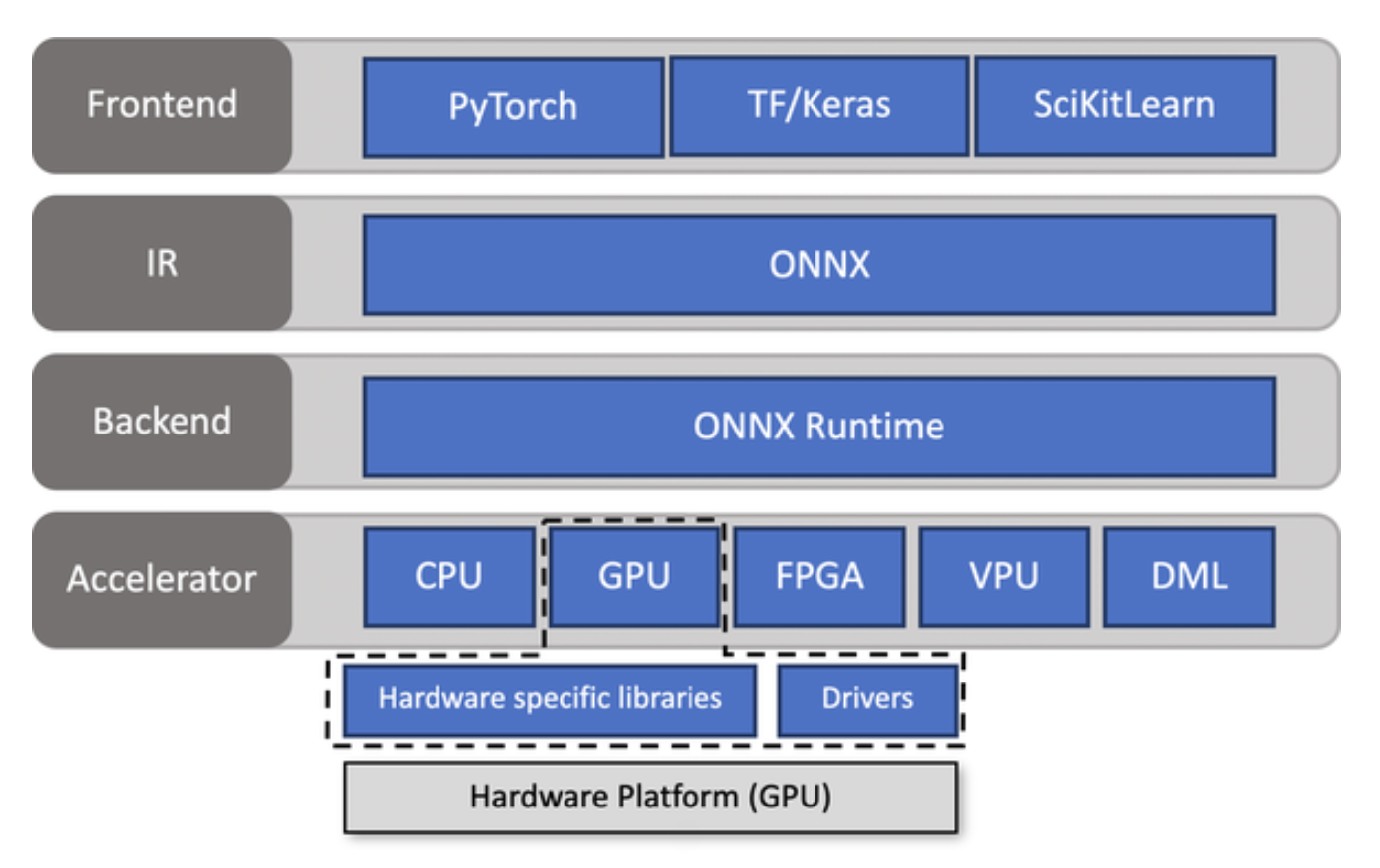
Optimizing inference with ONNX
When a model is exported to the ONNX format, a common set of operators is used to construct a computational graph that represents the flow of data through the neural network. This graph makes it easy to switch between frameworks.
ONNX can be coupled with accelerator like ONNX Runtime (ORT). ORT provides tools to optimize the ONNX graph through techniques like operator fusion and constant folding, and defines an interface to execution providers that allow you to run the model on different types of hardware.
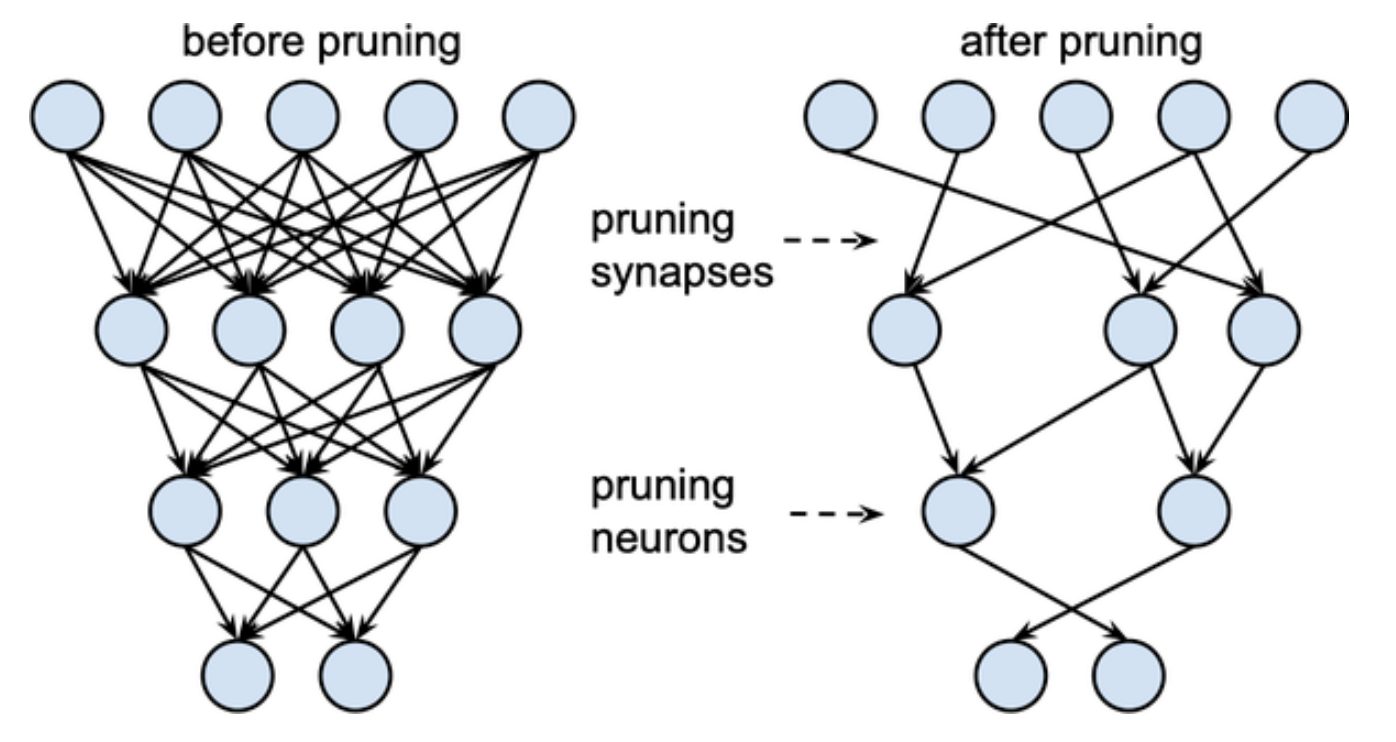
Weight Pruning
In case if the model is required to be deployed on mobile, we may need to shrink the number of parameters in our model by identifying and removing the least important weigths in the network.
The main idea behind pruning is to gradually remove weight connections during training such that the model becomes progressively sparser. The non-zero parameters are stored in a compact sparse matrix format. Pruning can be combined with quantization to obtain further compression.
- Weight Pruning methods
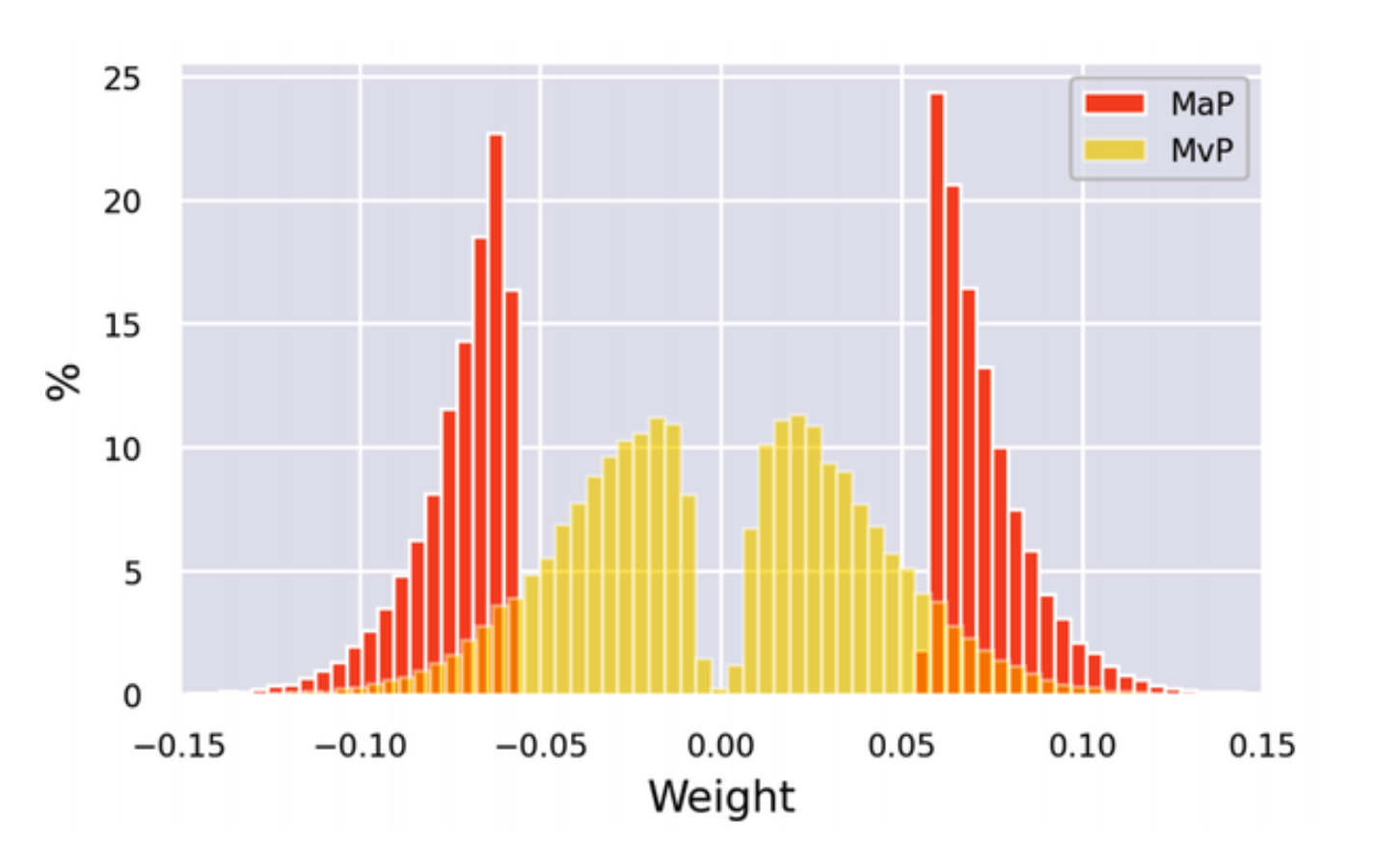
- Magnitude Pruning
Weight Pruning
It calculates the scores according to the magnitude of the weights. In this method sparsity is increased from an initial value to the final value after a number of steps.
The masks (where weigts are zero) are reactivated during training and recover from any potential loss in accuracy that is induced by the pruning process. The pruning is highest in the early process and gradually tapers off.
This method is designed for supervised learning and may not work for transfer learning.
Movement pruning
The basic idea behind movement pruning is to gradually remove weights during fine-tuning such that the model becomes progressively sparser. The key novelty is that both the weights and the scores are learned during fine-tuning. So, instead of being derived directly from the weights (like with magnitude pruning), the scores in movement pruning are arbitrary and are learned through gradient descent like any other neural network parameter. This implies that in the backward pass, we also track the gradient of the loss with respect to the scores.
Neural Networks Block Movement Pruning package can be used for pruning.