BERT
Bidirectional Encoder Representations from Transformer (BERT)
Pre-trained language model
Can be fine tuned with a simple additional output layer and reasonably sized dataset for a broad range of NLP tasks
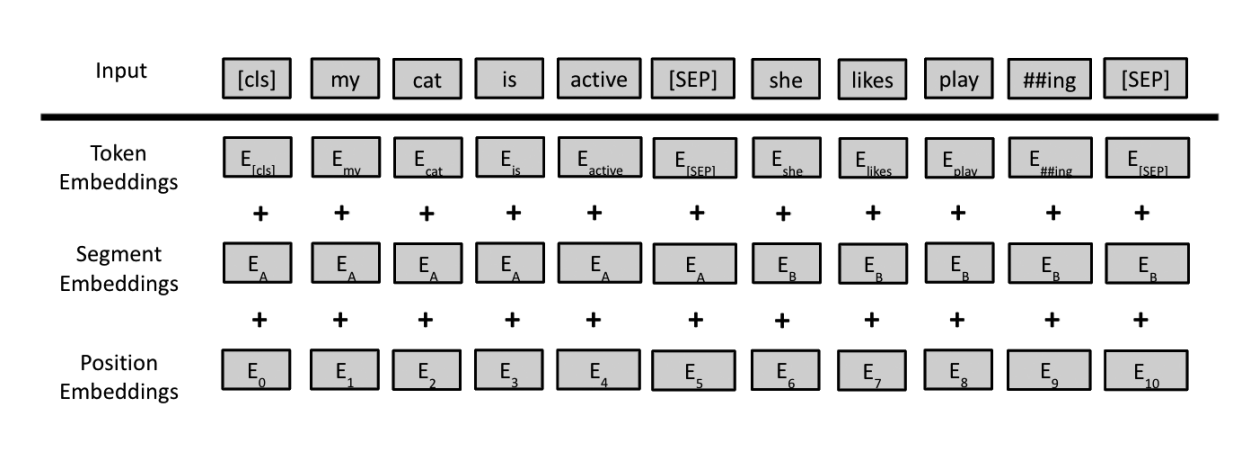
BERT Inputs 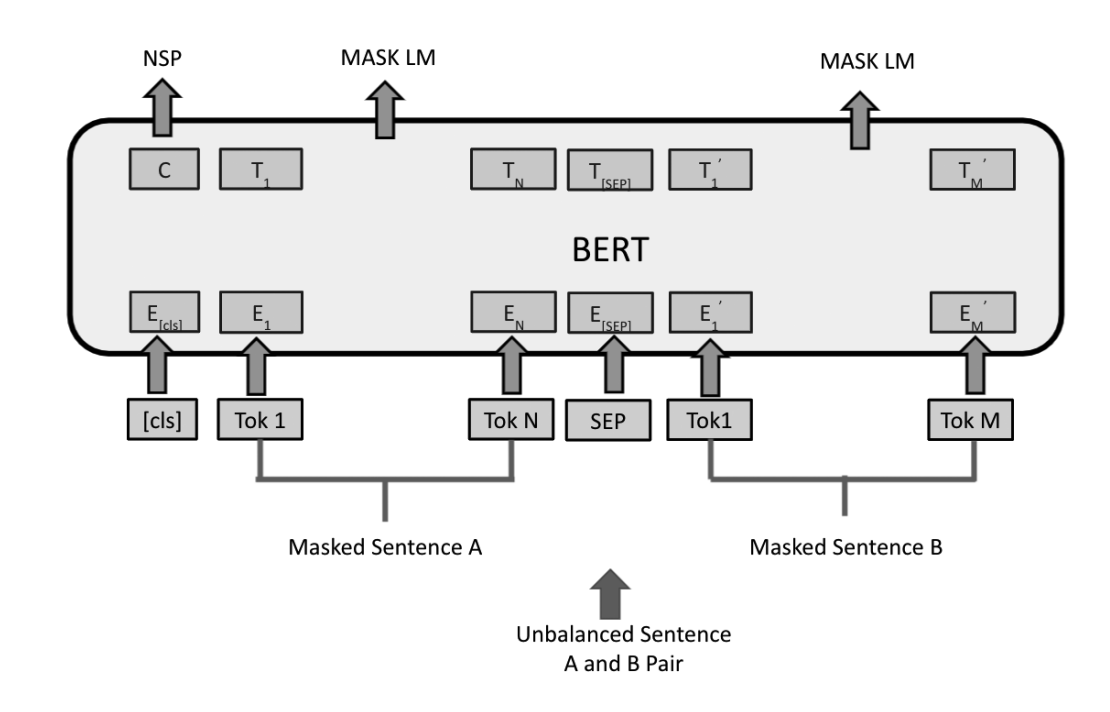
BERT Pretrained on NSP and MLM 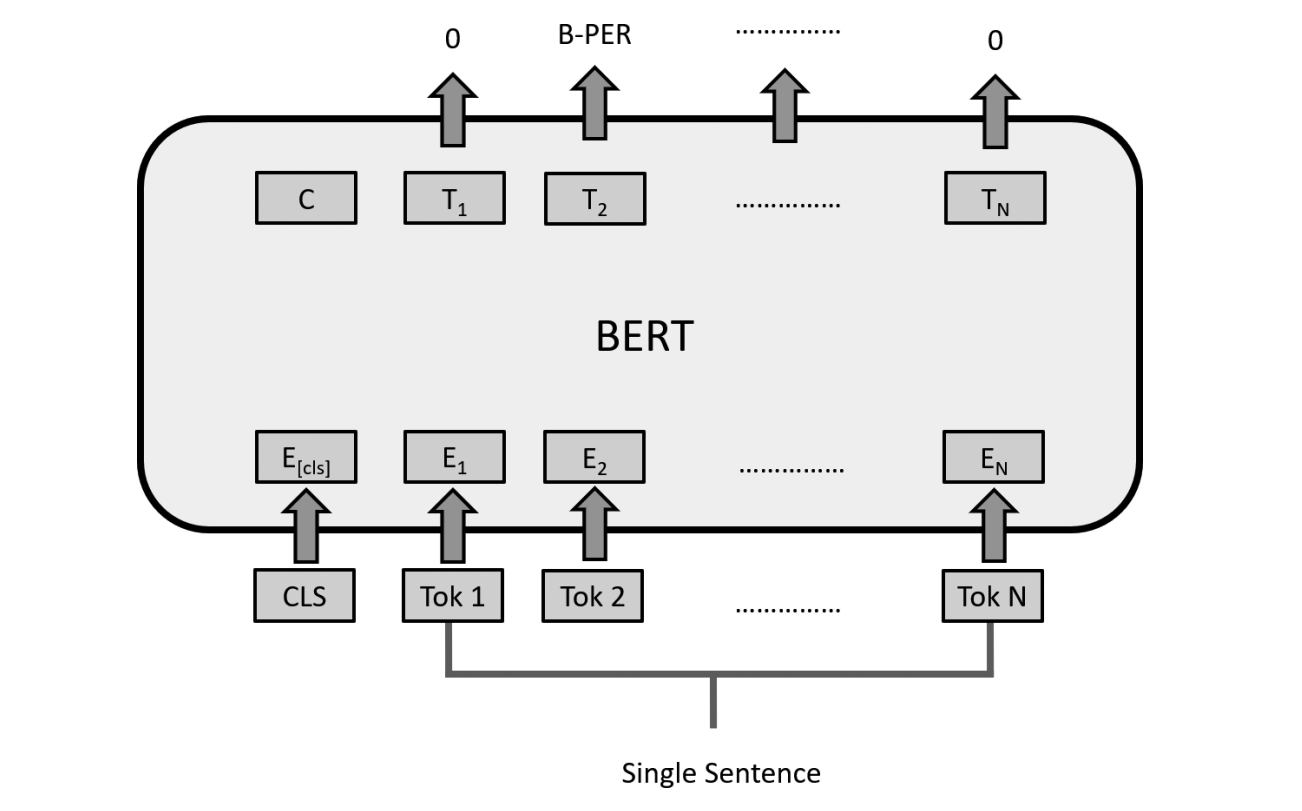
BERT fine-tuning architecture for token tagging tasks like POS, NER, QA
Training
- Masked Language Modelling
- Next Sentence Prediction
BERT Variants
Robustly Optimized BERT pre-training approach (RoBERTa)
- Same architecture as BERT with difference in the amount of training data, training tasks, methods and hyperparameter tuning
The Important differences are:- * Pre-training the model for longer time * Using bigger batches * Using more training data * Removing the Next sentence Prediction (NSP) task * Training on longer sequences * Dynamically changing the masking pattern applied to the training data for each epoch. (For BERT the masked token were static for all epochs)
BERT Applications
TaBERT
- The first model to have been pre-trained on both natural language sentences and tabular data formats.
- TaBERT is built on top of the BERT model that accepts natural language queries and tables as input.
- It acquires contextual representations for sentences as well as the consitituents of the DB table
- These representations may be further fine-tuned using the training data for that job
BERTopic
- BERT for topic modeling
- BERT models are used to create the embeddings of the documents of interest
- Preprocessing takes care of the document size by dividing to small paragraphs that are smaller than the token size for the transformer model
- Clustering is performed on the document embeddings to cluster all the documents with similar topics together
- Dimensionality reduction is used to reduce the dimensionality of the embeddings
- class-based TF-IDF in which all documents in a certain category is considered as a single document then tf-idf computed - This calculates the relative importance of a word in a class instead of documents
BERT Insights
BERTology
- It aims to answer why BERT performs well on so many NLP tasks
Read More
Teacher forcingin RNN models- Covariance shift - Gradient dependencies between each layer and speeds up the convergence as fewer iterations are needed. How Layer Normalization and Covariance shift are related?
- Different Normalizations - Batch, layer etc
- Perplexity - Evaluation metric