An Image is worth 16X16 Words
Split an image into patches and provide the sequence of linear embeddings of these patches as an input to Transformer.
Image patches are treated the same way as tokens (words) in an NLP application. We train the model on image classification in supervised fashion.
Transformers lack some of the inductive biases inherent to CNNs such as translation equivariance and locality and therefore do not generalize well when trained on insufficient amounts of data
It is often beneficial to fine-tune at higher resolution than pre-trainingViT performs better when trained on large scale data and transferred to tasks with fewer datapoints
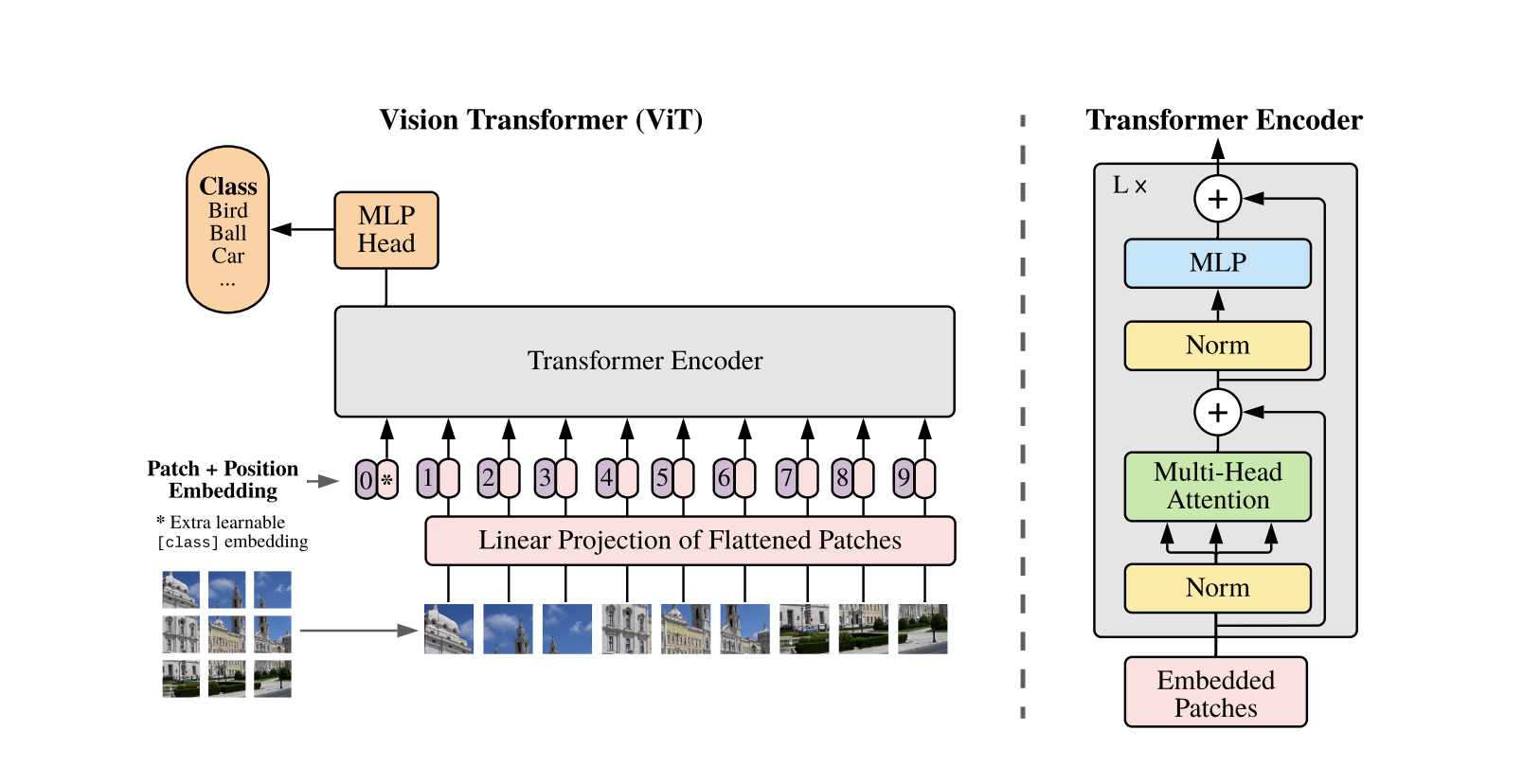
The image patches are flattened and mapped to D dimensions with a trainable linear projection.These are called patch embeddings
Learnable embedding is prepended to the sequence of embedded patches, whose state at the output of the transformer encoder serves as the image representation.
Learnable 1D position embeddings are added to patch embeddings to retain positional information
MLP contains two layers with GELU (Gaussina Error Linear Units) non-linearity
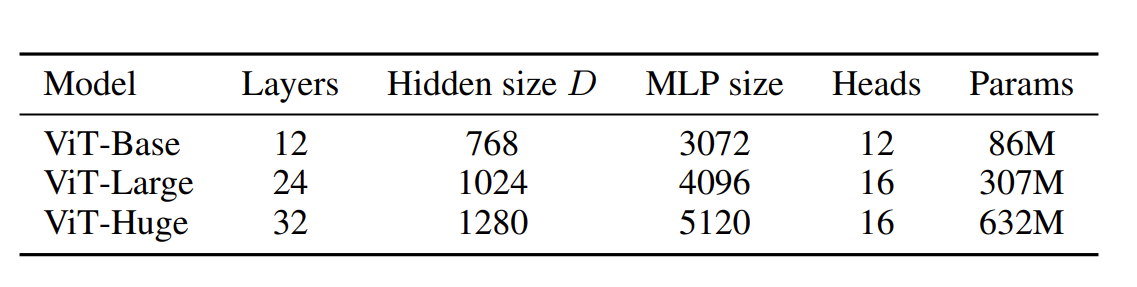
- Regularization used - weight decay, dropout and label smoothing
In the lowest layers some heads attend to most of the image, showing that the ability to integrate information globally is indeed used by the model. The attention distance increases with network depth. Globally, the model attends to image regions that are semantically relevant for classification