CNN Architectures
AlexNet
- It had 5 convolutional layers
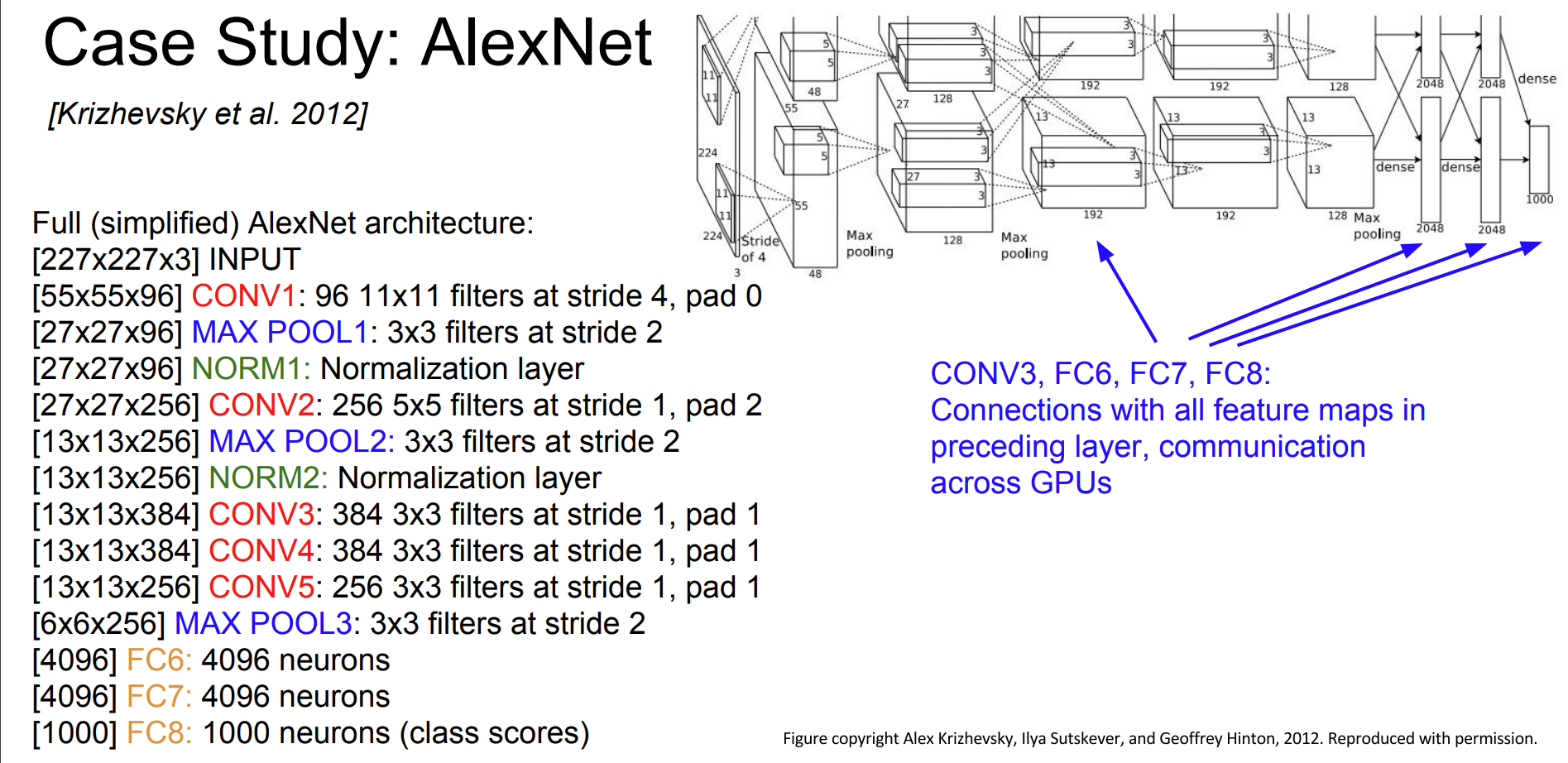
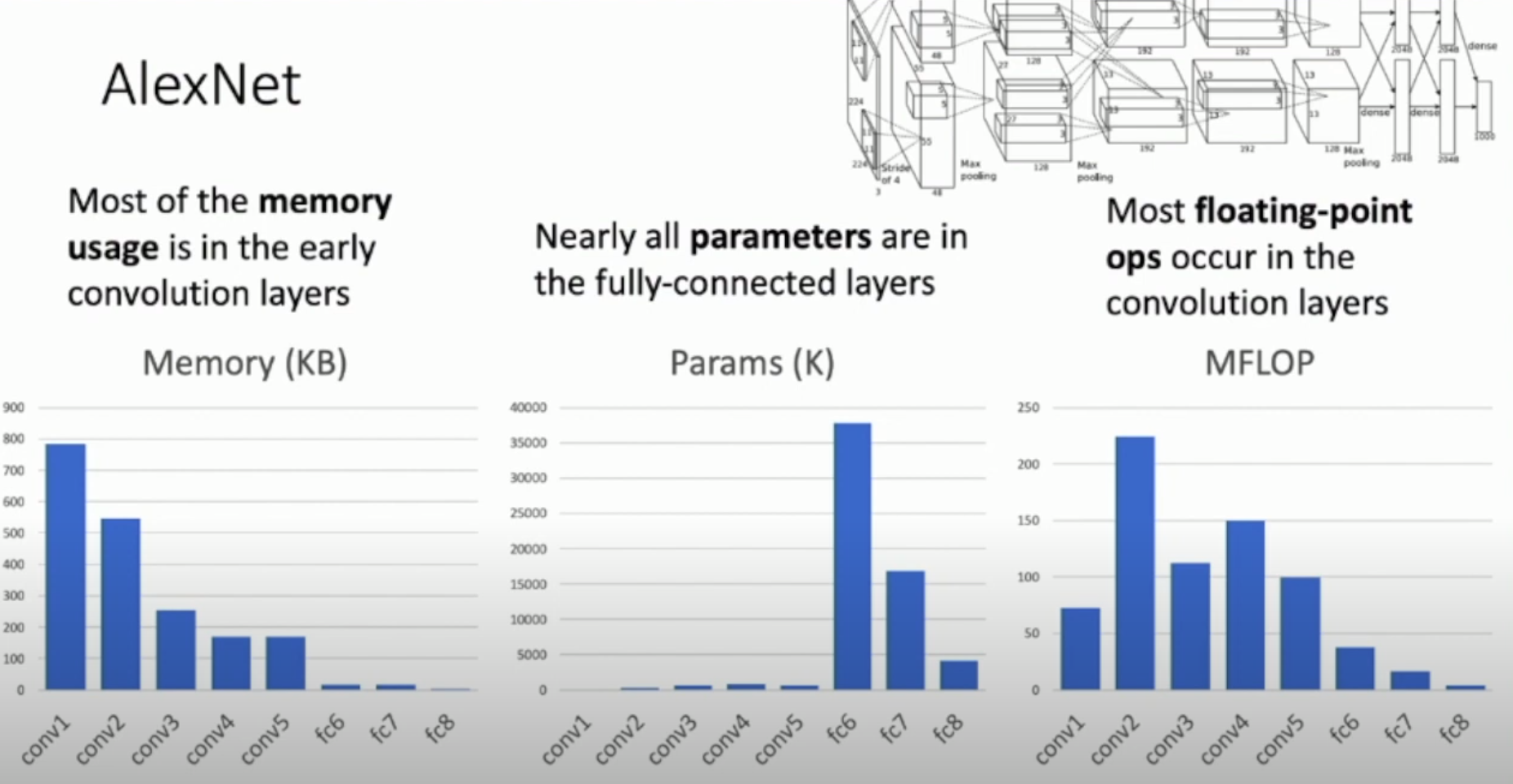
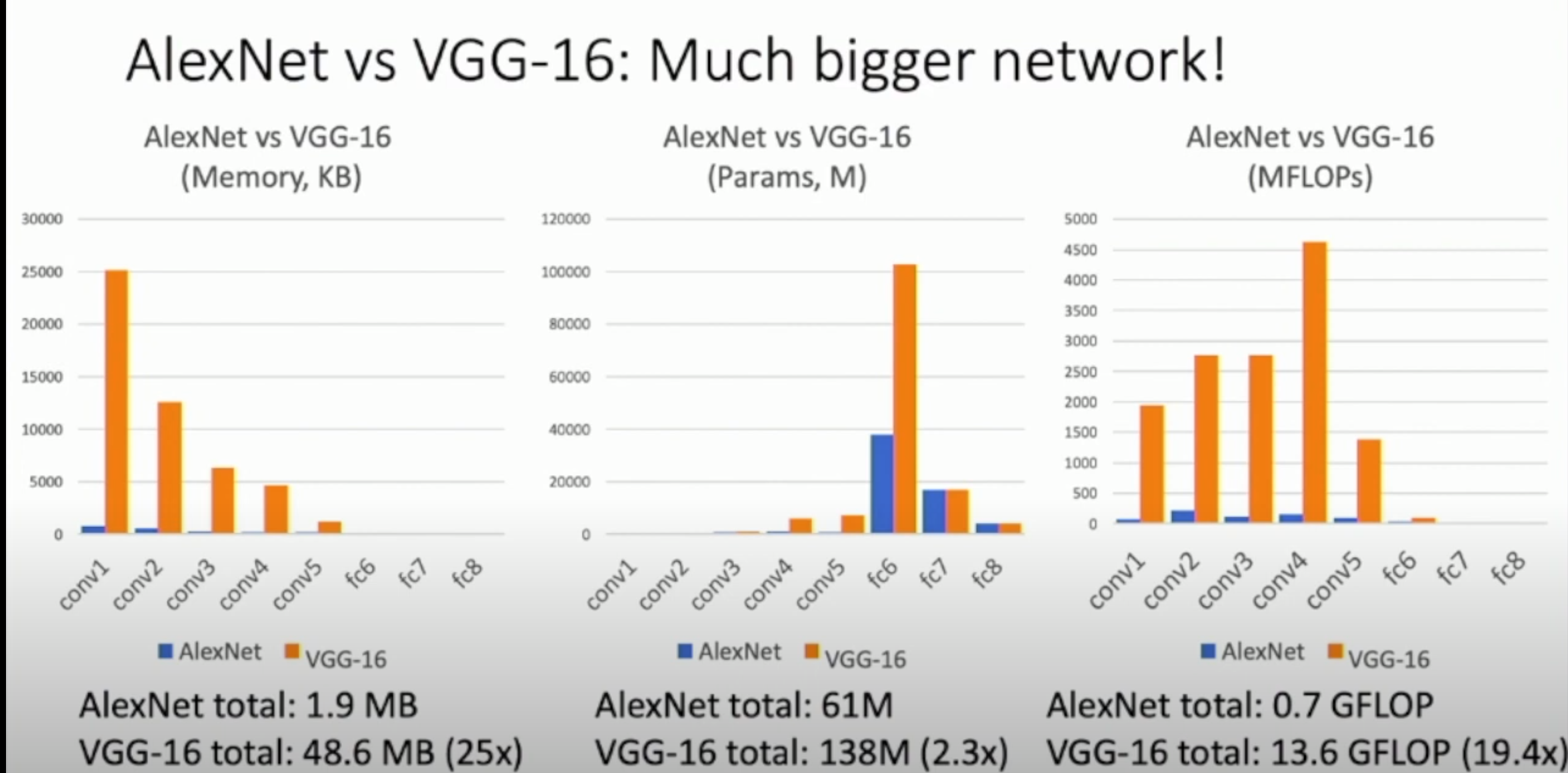
Memory, Parameters and FLOPS of Alexnet
VGG Architecture
One of the first architecture with Design rules
All convultional layers are 3x3 with stride 1 and pad 1
All max pool are 2x2 with stride 2
After pooling the number of channels are doubled
It came with 16 and 19 layer models
We have lot of parameters in the early convolutional layer and the fully connected layers at the end of the network
Future architectures will remove the fully connected layers to reduce the number of parameters

VGG Architecture with number of parameters 
Different VGG Models with 16 and 19 layers
why 3x3 convolutional layers are used in VGG
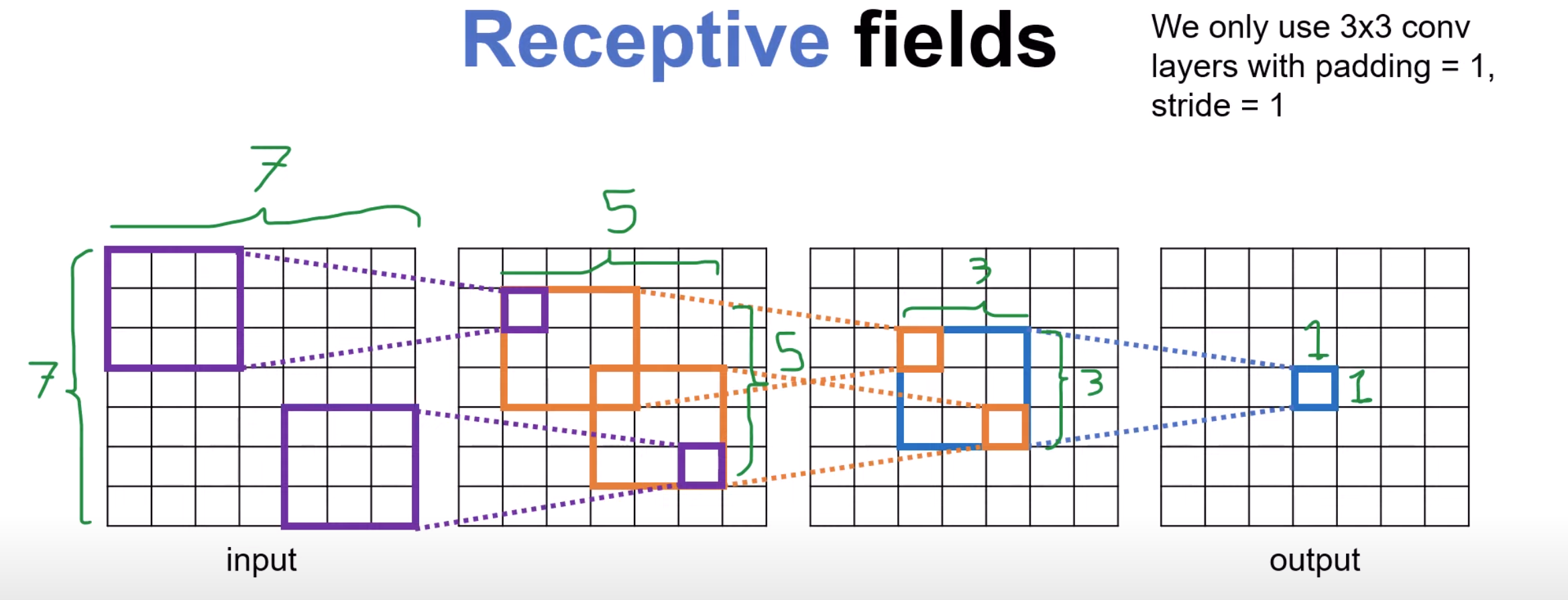
Three 3x3 convolutional layers stacked together (with non-linearities and a stride of 1) will have a receptive field equivalent to one 7x7 layer 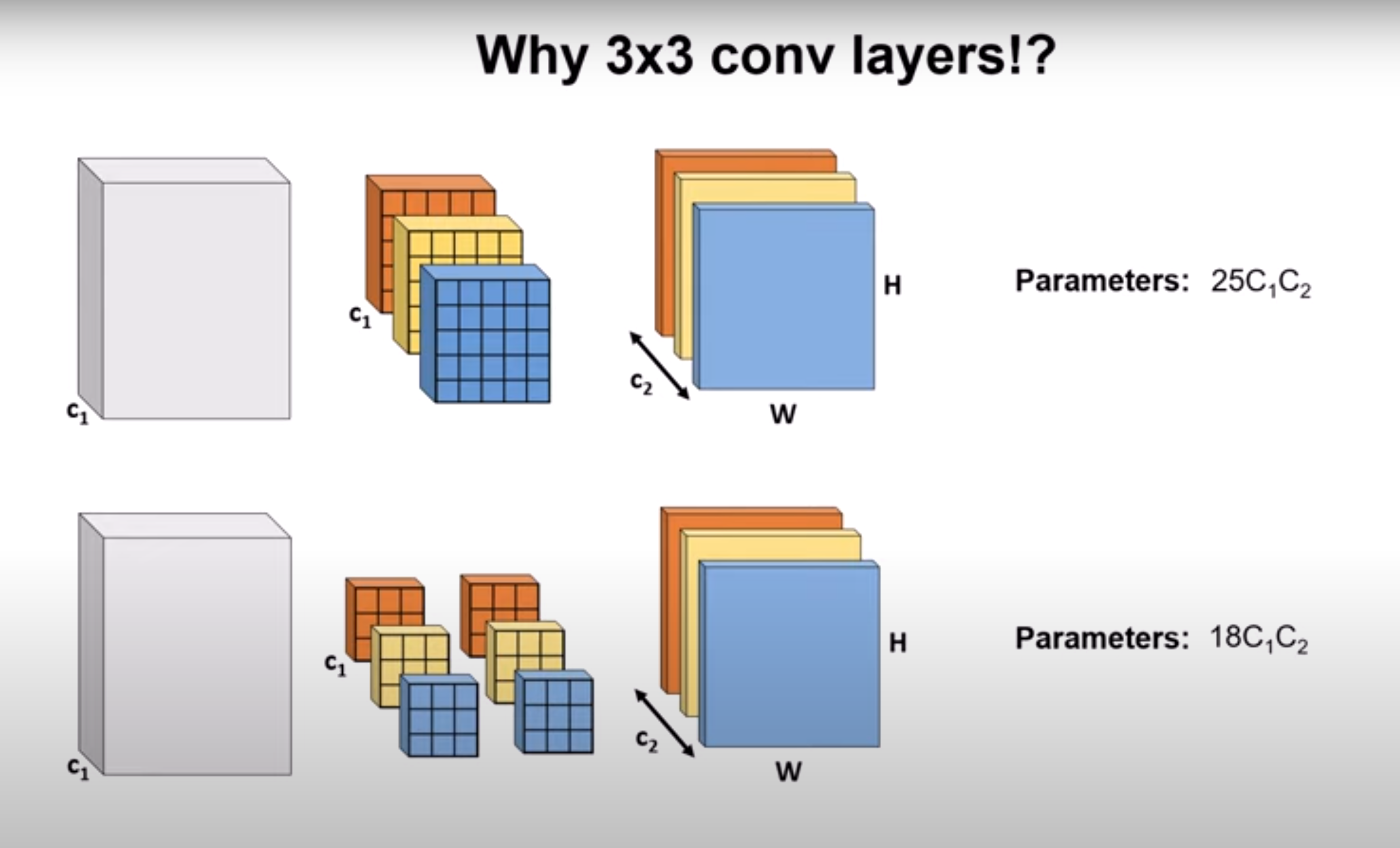
Using two 3x3 convolutional layers which is equivalent to using one 5x5 layer will have fewer number of parameters 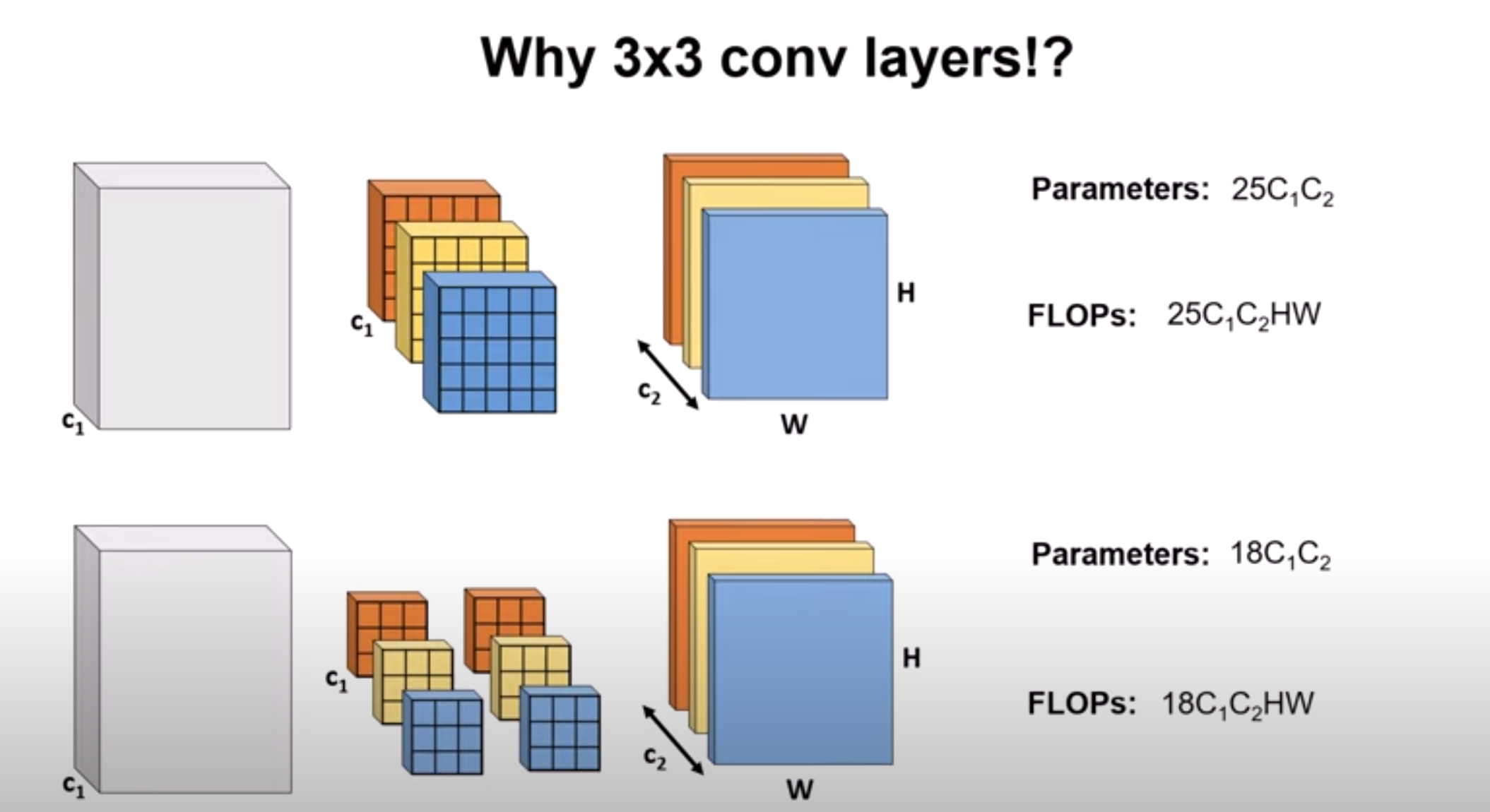
Using 3x3 conv layers will also reduce the number of Floating Point Operations We can use activation functions between the two 3x3 convolutional layers which will provide more non-linearity
AlexNet VS VGG - Memory, Parameters and FLOPS
GoogleNet
- 22 layers with only 5 million parameters
- 12x less parameters than Alexnet
- Inception modules are used in the network
- No fully connected layers
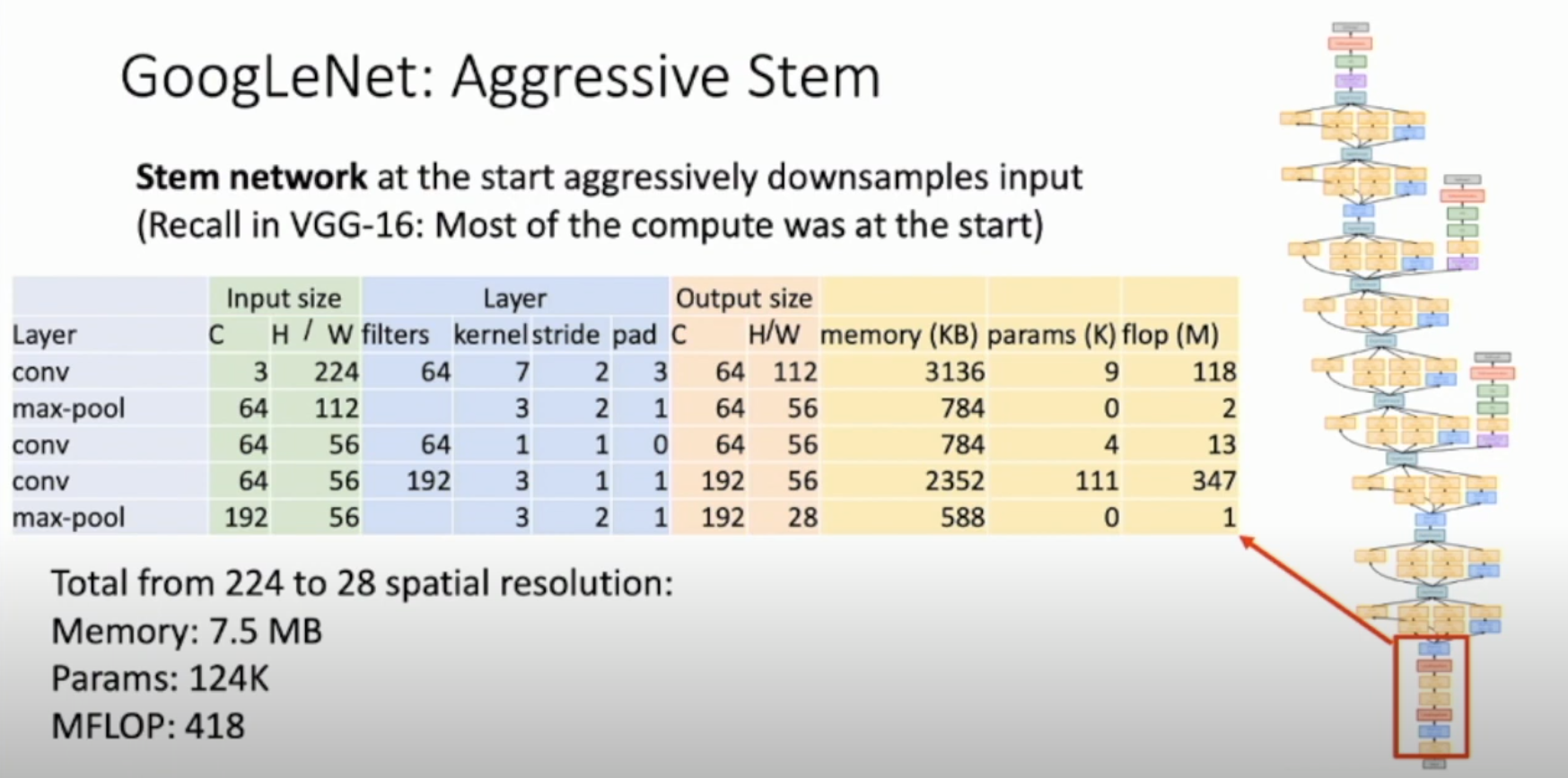
- Stem network at the start aggressively downsample input (for VGG-16 most of the compute was at the start due to large spatial dimensions)
- No large Fully connected layers at the end. Instead uses
global average poolingto collapse spatial dimensions and one linear layer to produce class scores (VGG-16 most parameters were in the FC layers) - They have auxiliary classifiers. Training using loss at the end of the network din’t work well. Network is too deep and gradients don’t propagate cleanly. As a hack, they attached
auxiliary classifiersat intermediate points in the network that also try to classify the image and receive loss. (GooGleNet was before batch normalization, with BatchNorm no need to use this trick) 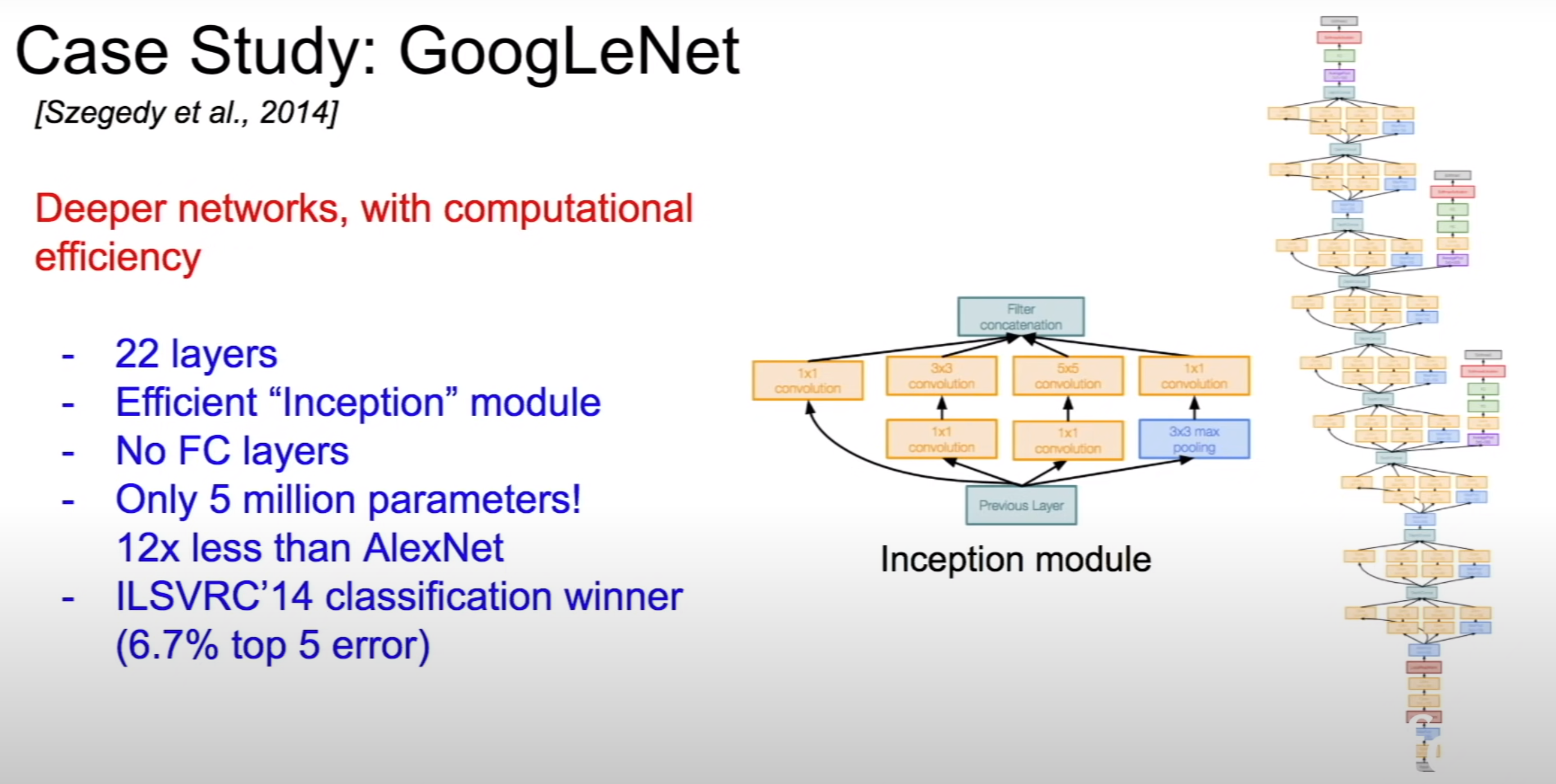

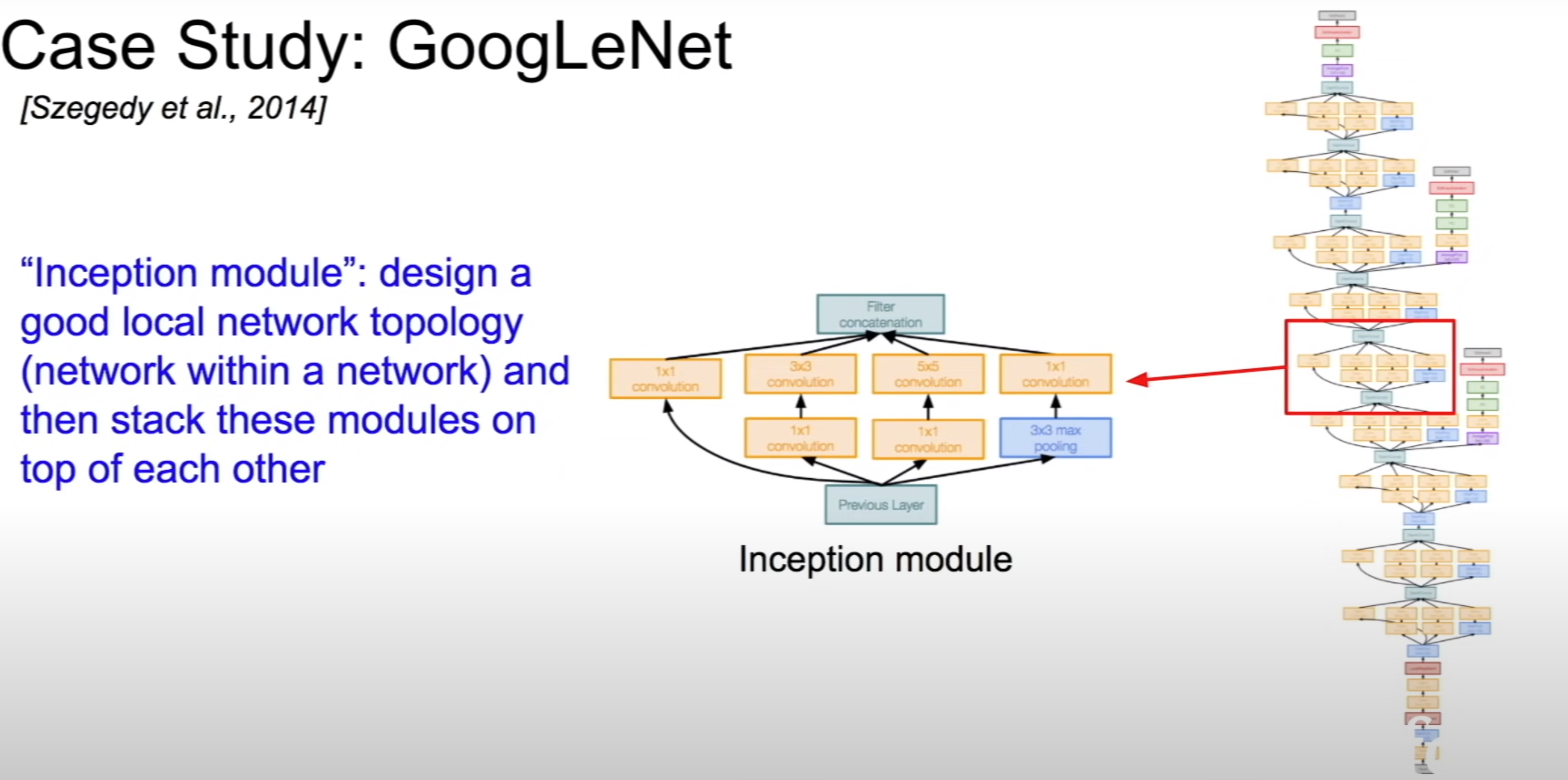
Inception Module
Design of a
network within a network(local network topology)Inception modules are stacked on top of each other
The presence of multiple convolutional filters in the Inception module will blow the number of parameters and computation required. Bottleneck layers that use 1x1 convolutionals to reduce the depth while preserving spatial dimensions
Inception Module 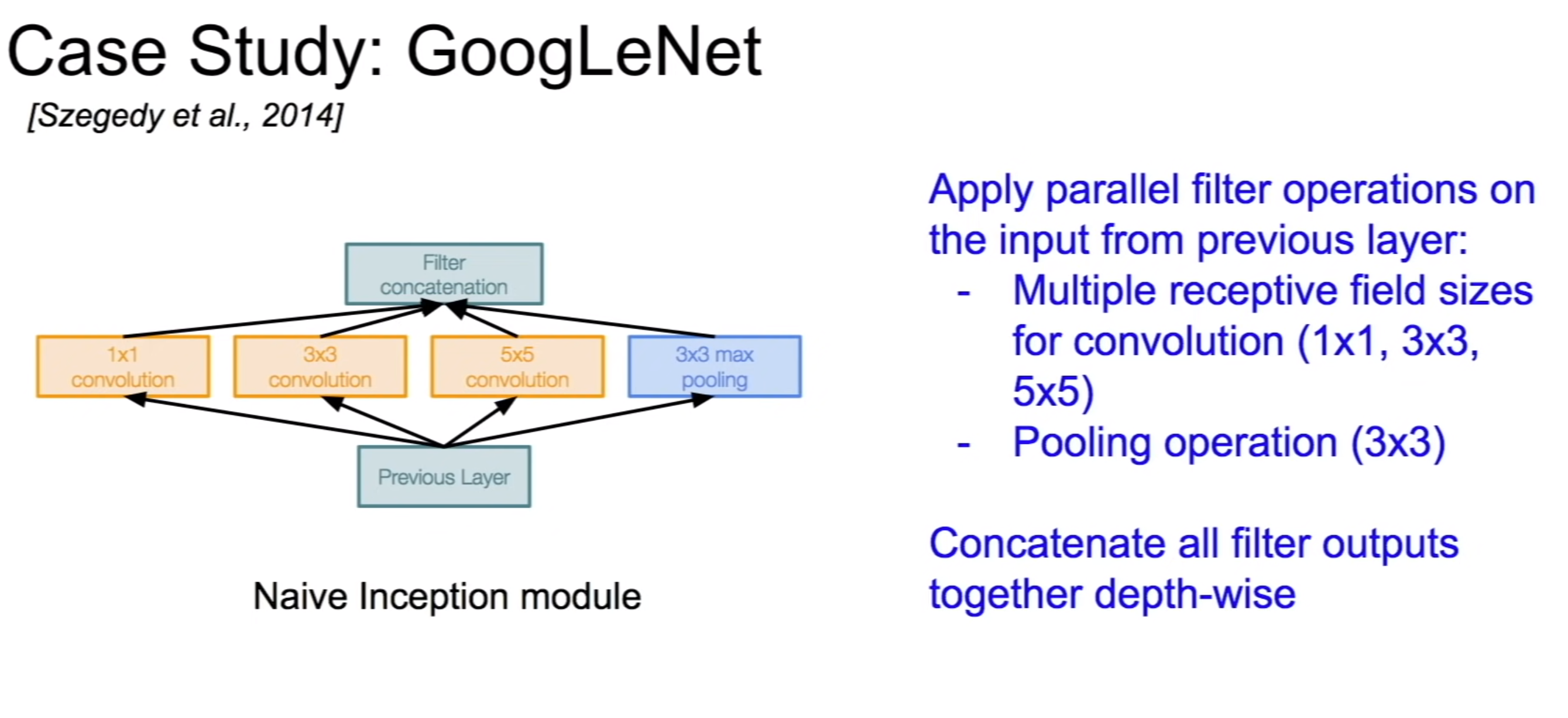
Applying different filter operations on the input 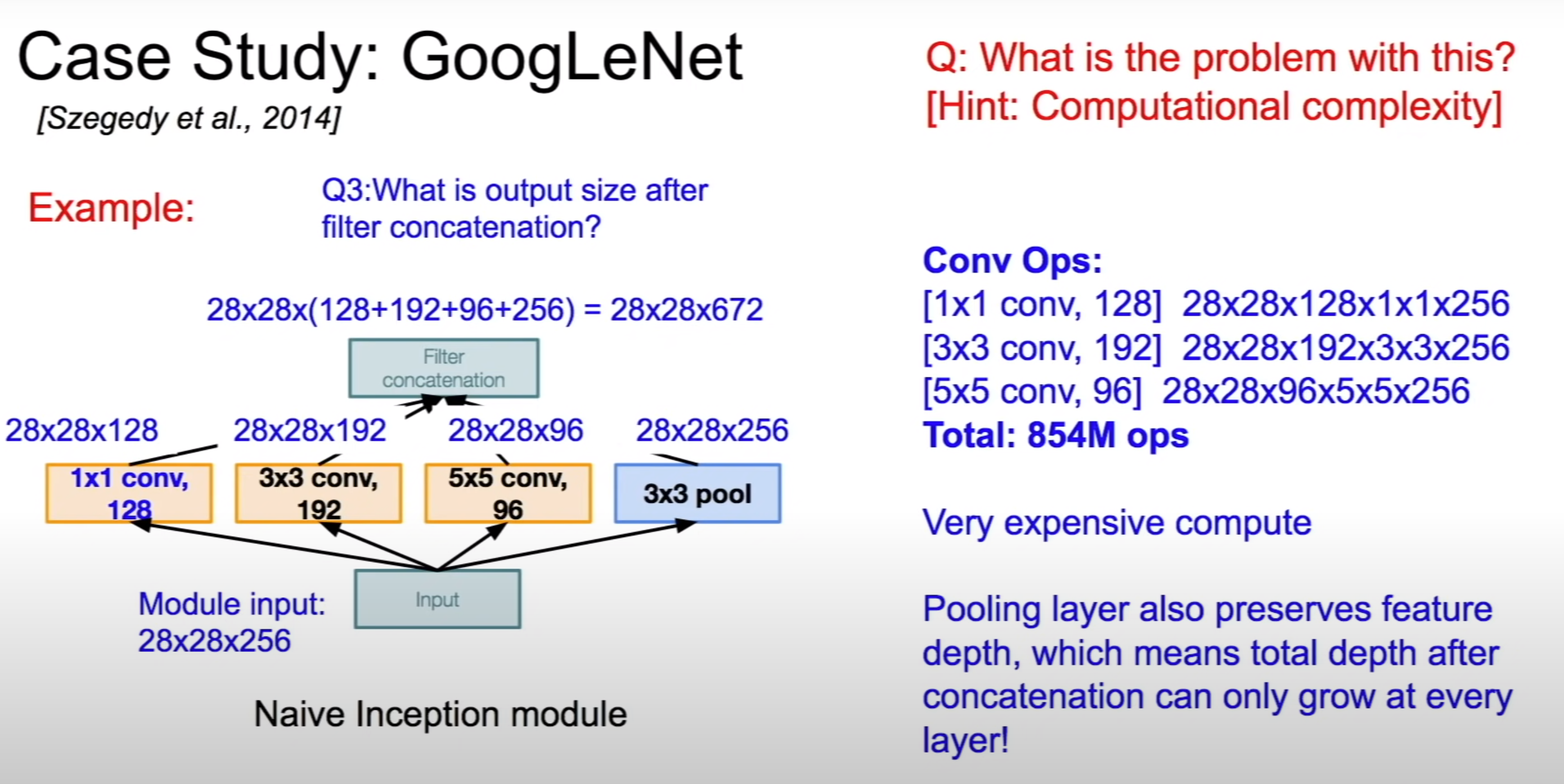
computational complexity of Inception module 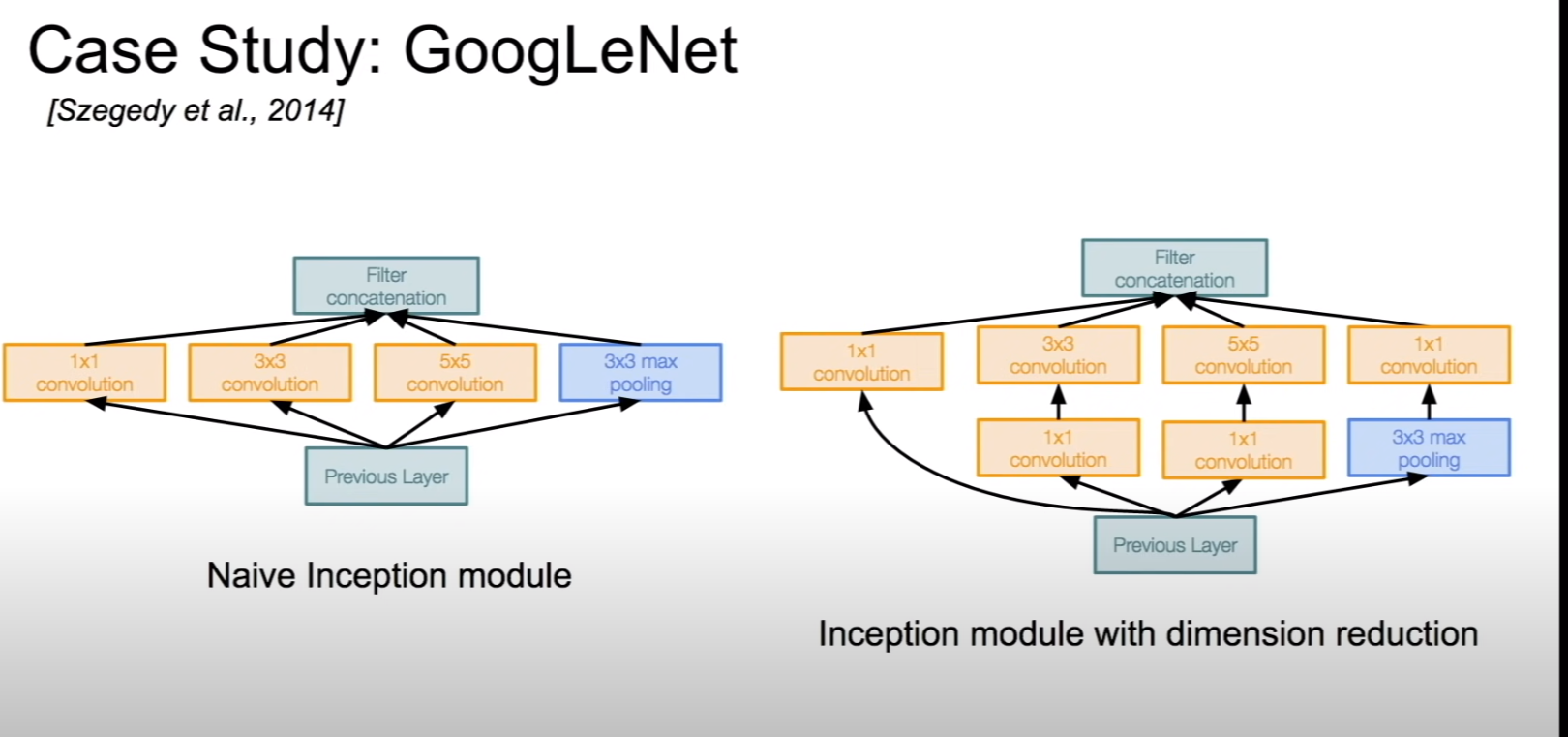
Inception layers with 1x1 convolution bottleneck layer 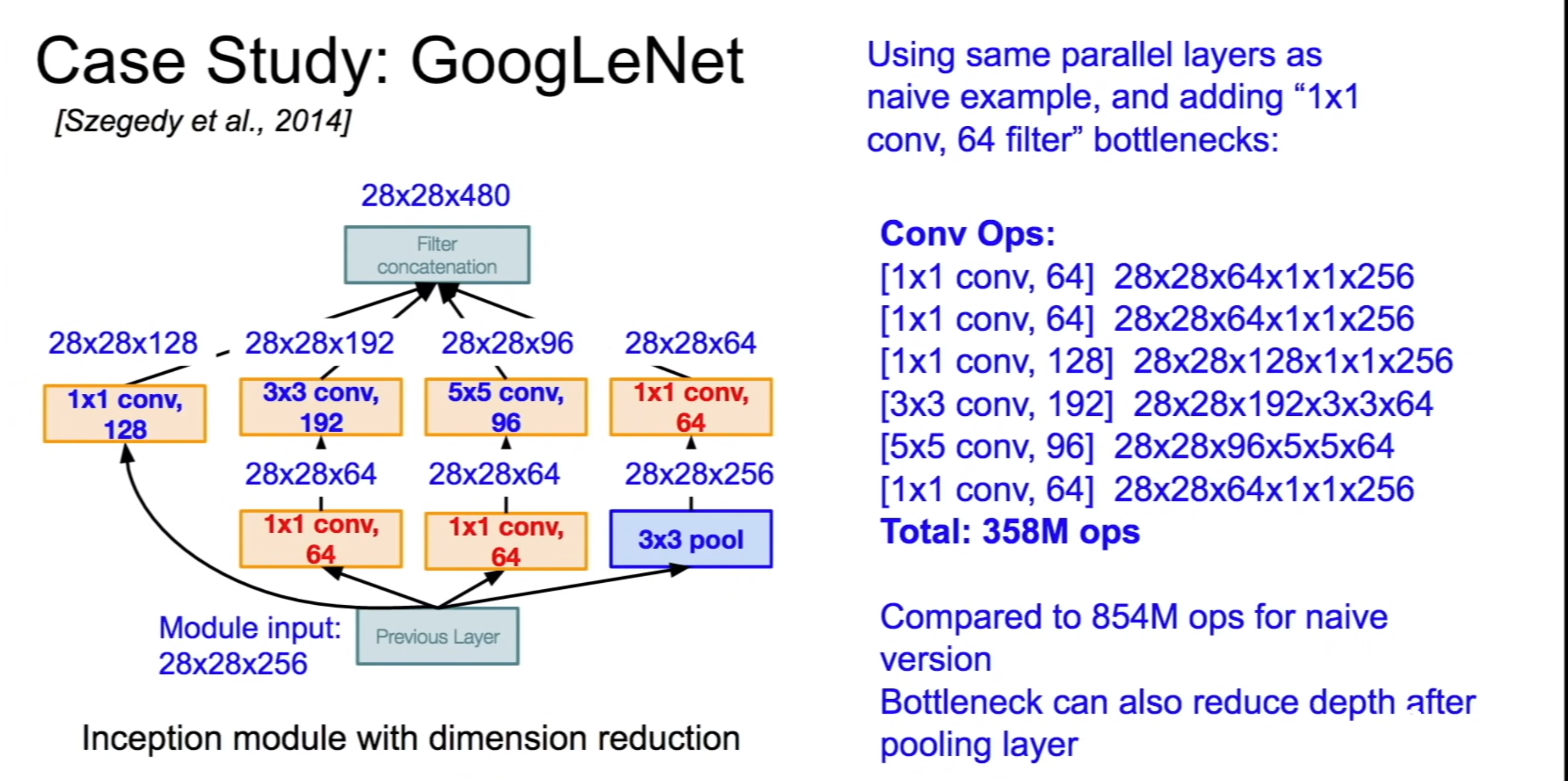
Bottleneck layer reducing the number of operations required in Inception Module
ResNet
With Batch normalization, teams are able to train networks with 10+ layers
It was found that with deeper layers the models were not performing well as shallow models and are underfitting. This was happening due to optimization problem
152 layer model
Very deep networks using residual connections
Deeper models does not perform better by adding more layers. Deeper layers are hard to optimize
ResNet with very large number of layers uses bottleneck blocks with 1x1 conv to reduce the number of channels, do convolutions with 3x3 filter and increase the number of channels with 1x1 filter
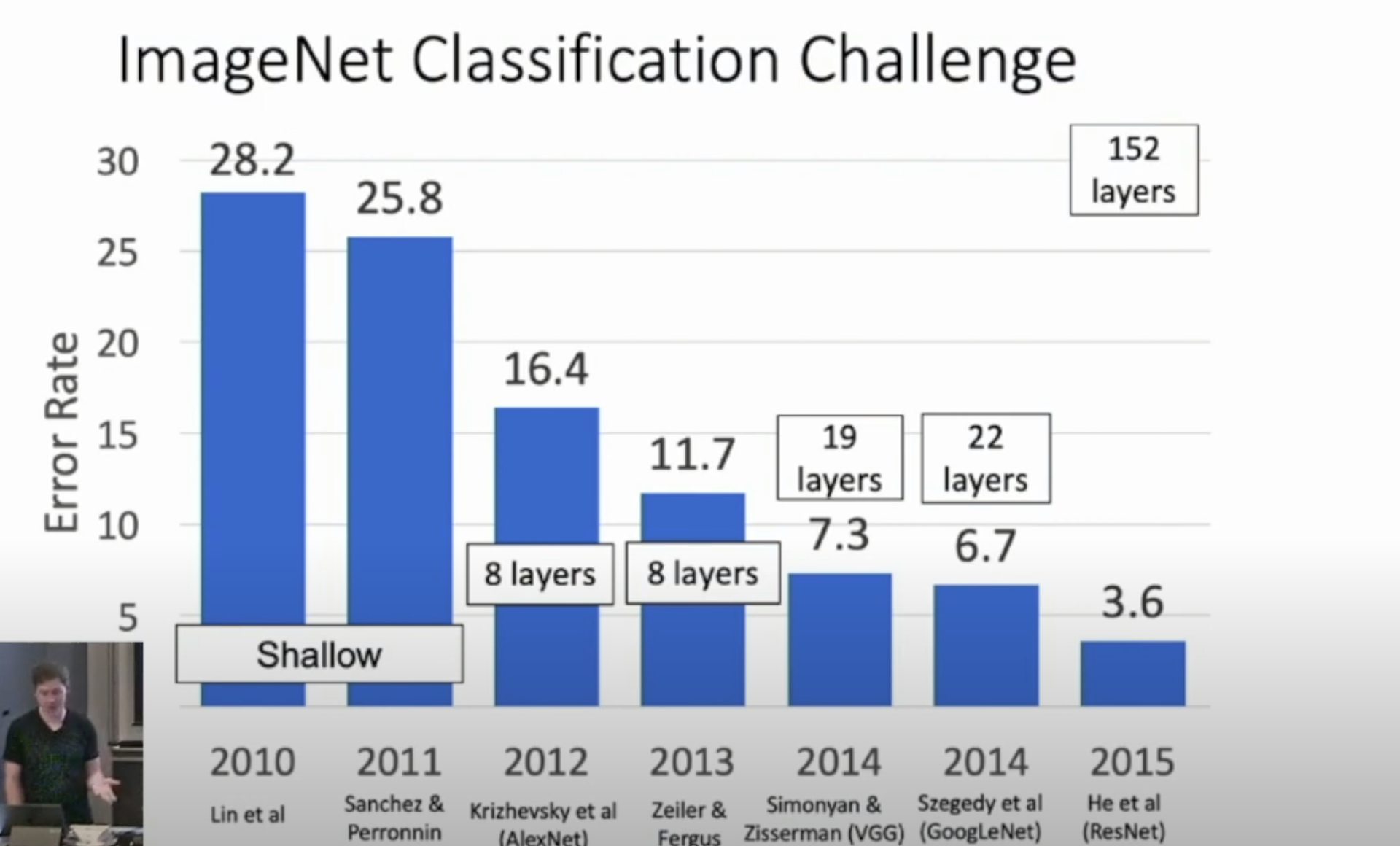
Increase in Number of layers 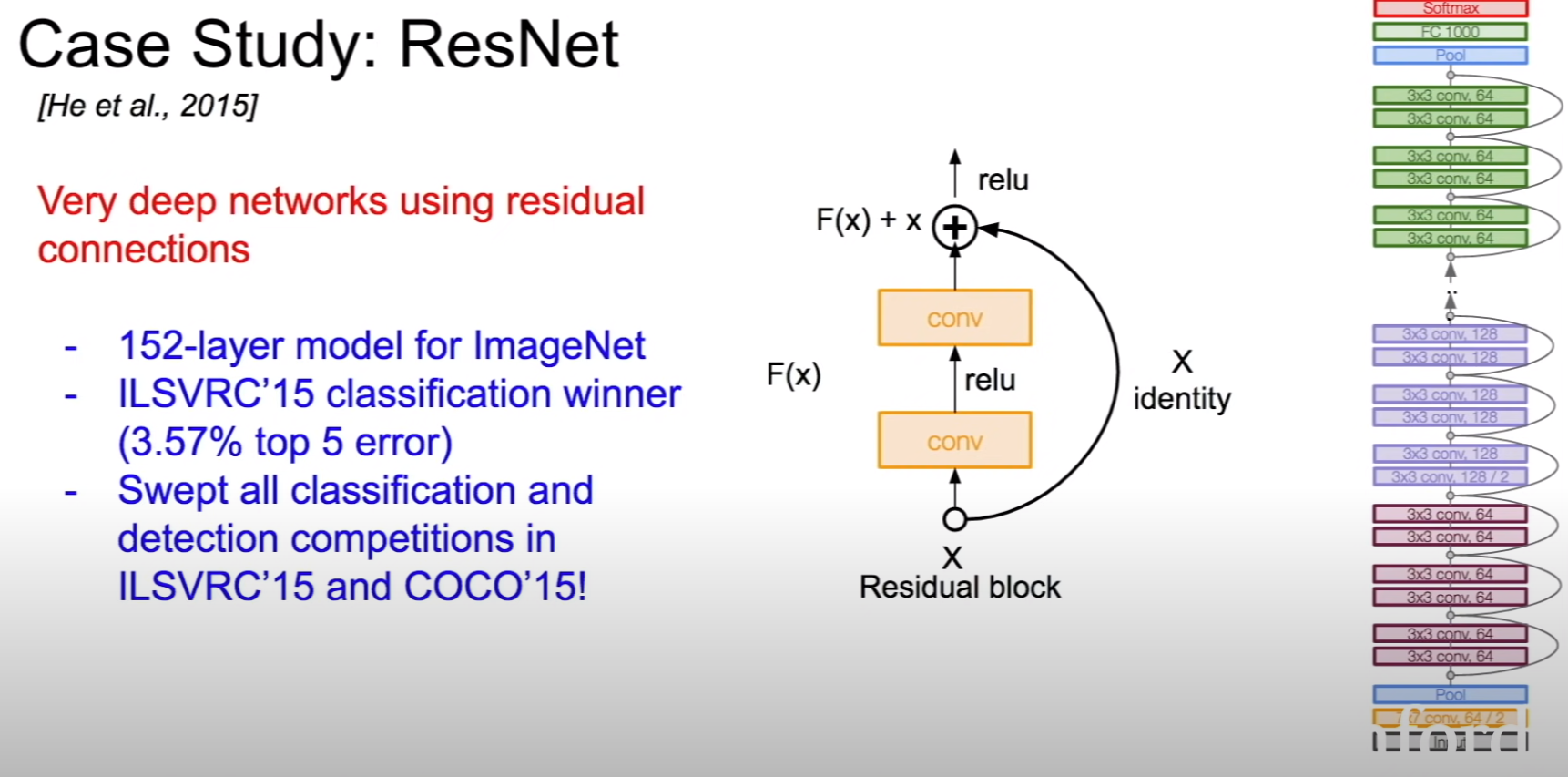
Residual blocks used to increase network depth