You Only Look Once (YOLO)
Different Object Detection Algorithms
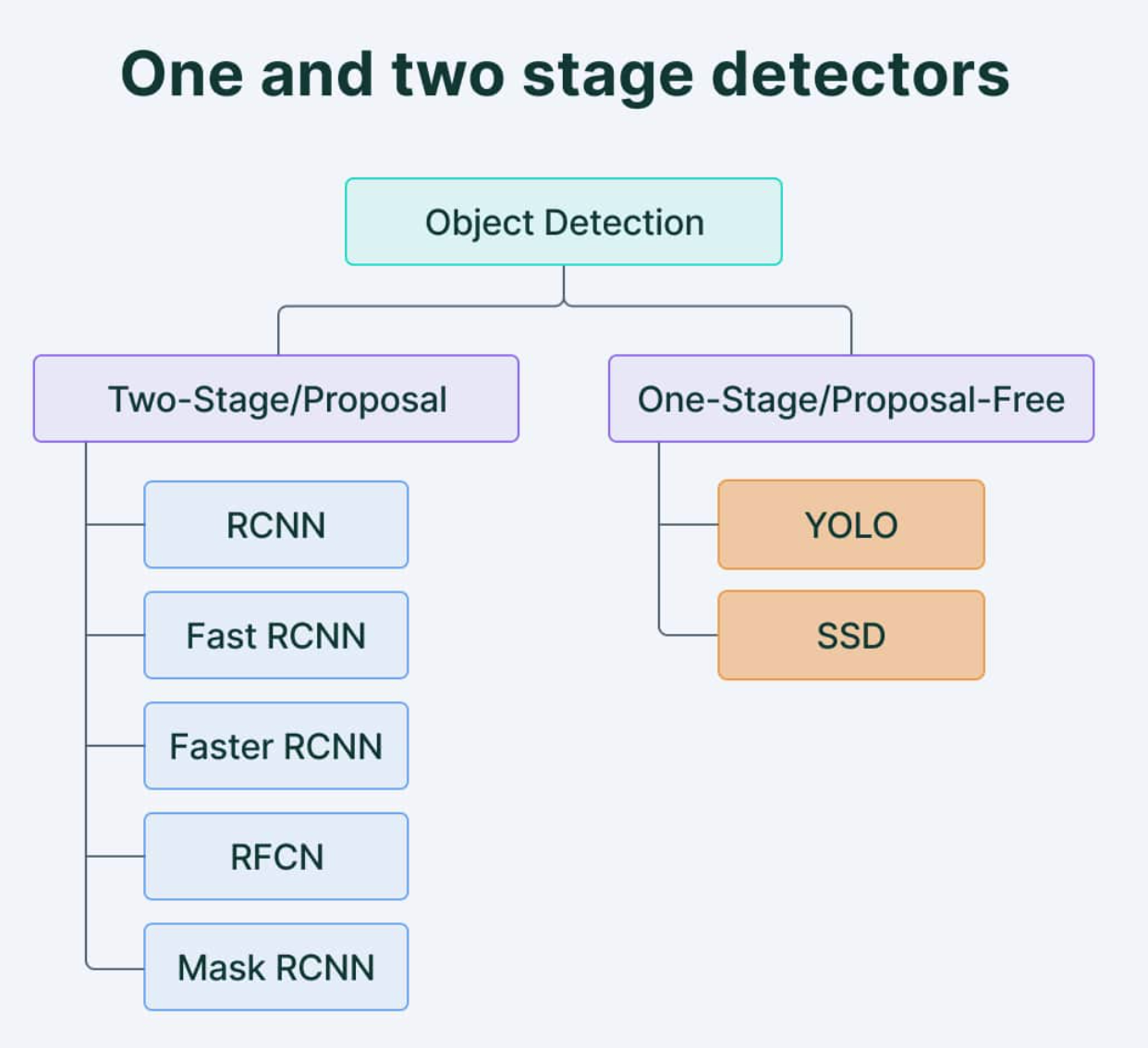
Single shot detectors
Less accurate than other methods
Less effective in detecting small objects
Can be used to detect objects in real time in resource constrained environments
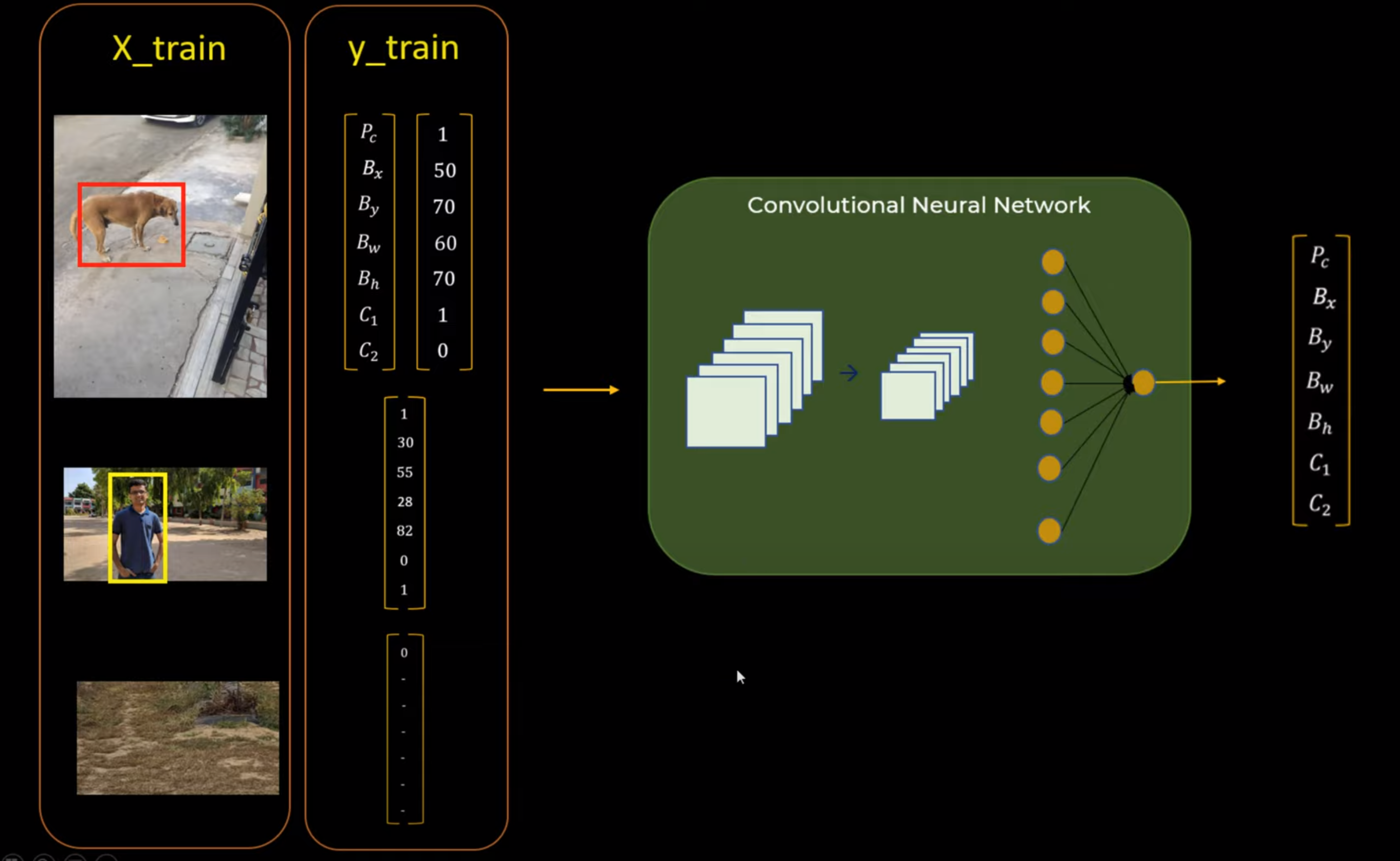
How neural networks are trained for object detection
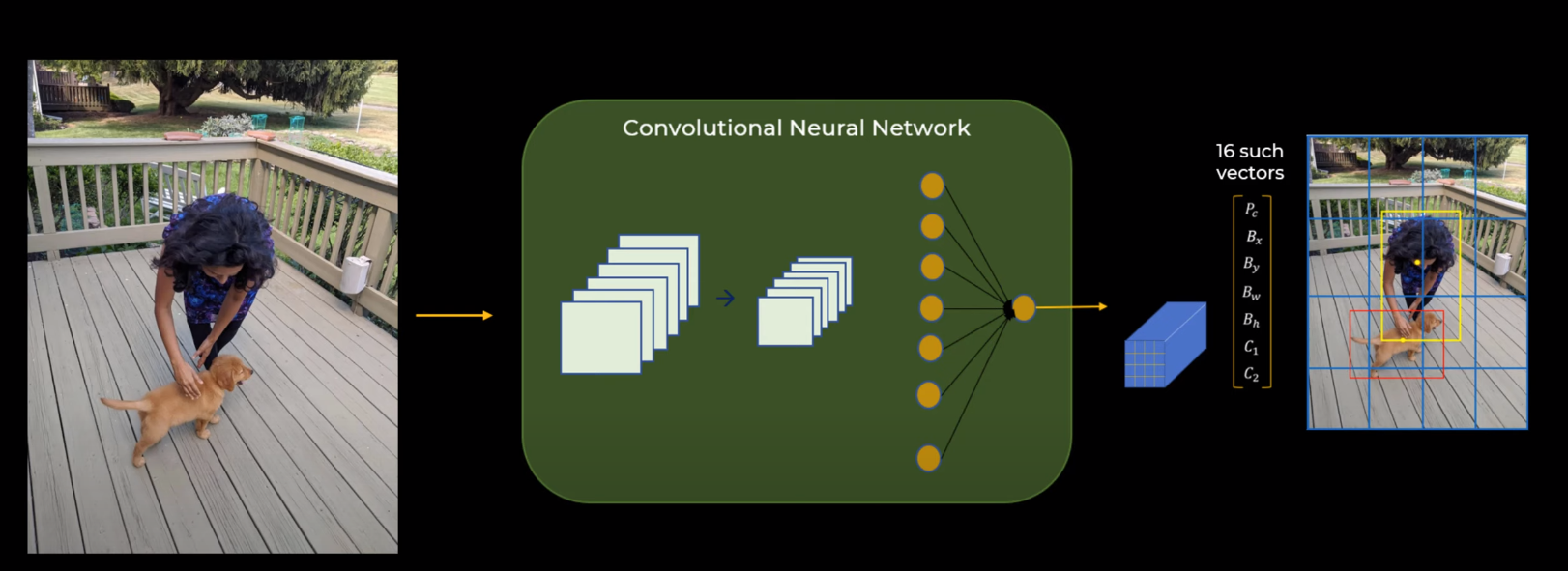
How YOLO Works
Training Data
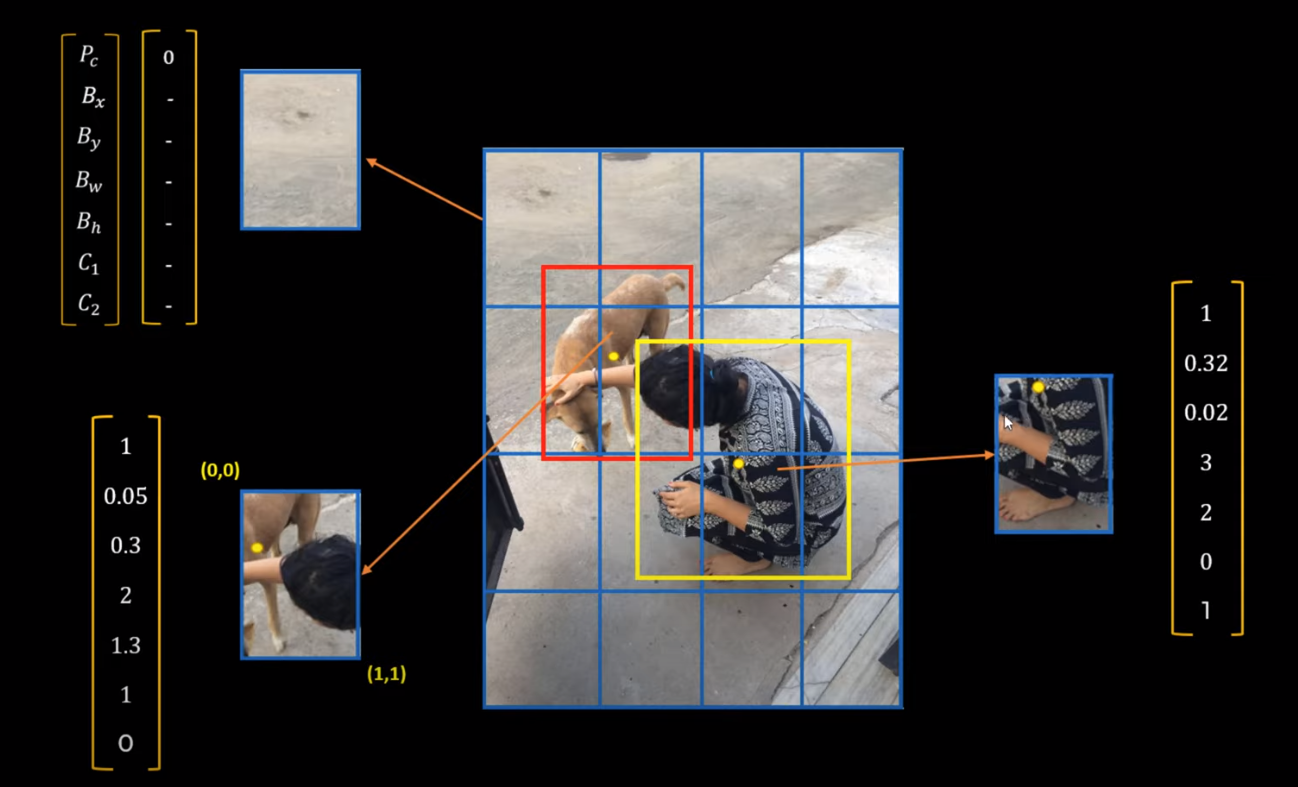
It divides the images into different grids

If an object belongs to multiple grid,the object belongs to the grid where the centre of the object is located.
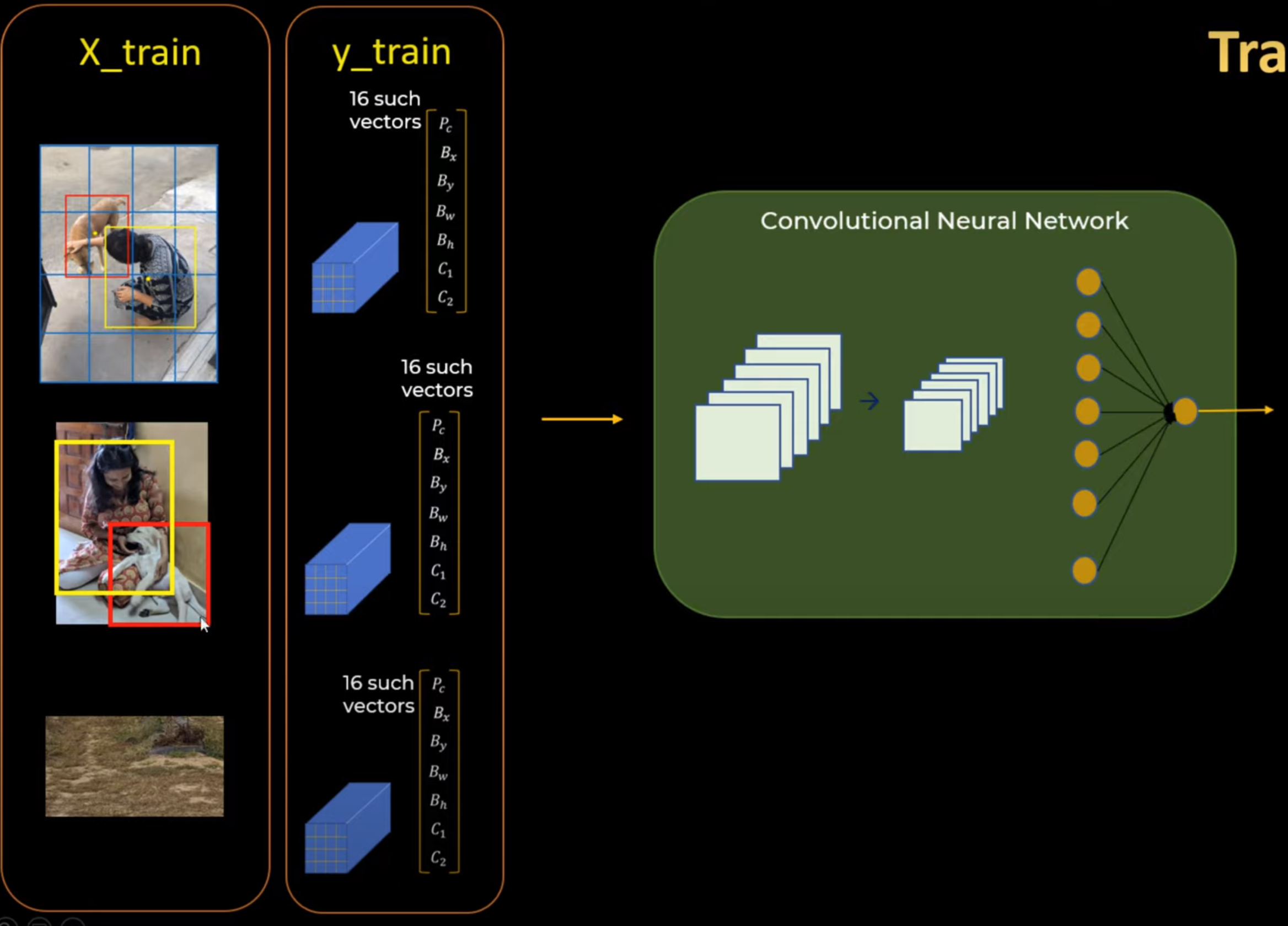
Training
Prediction
NMS
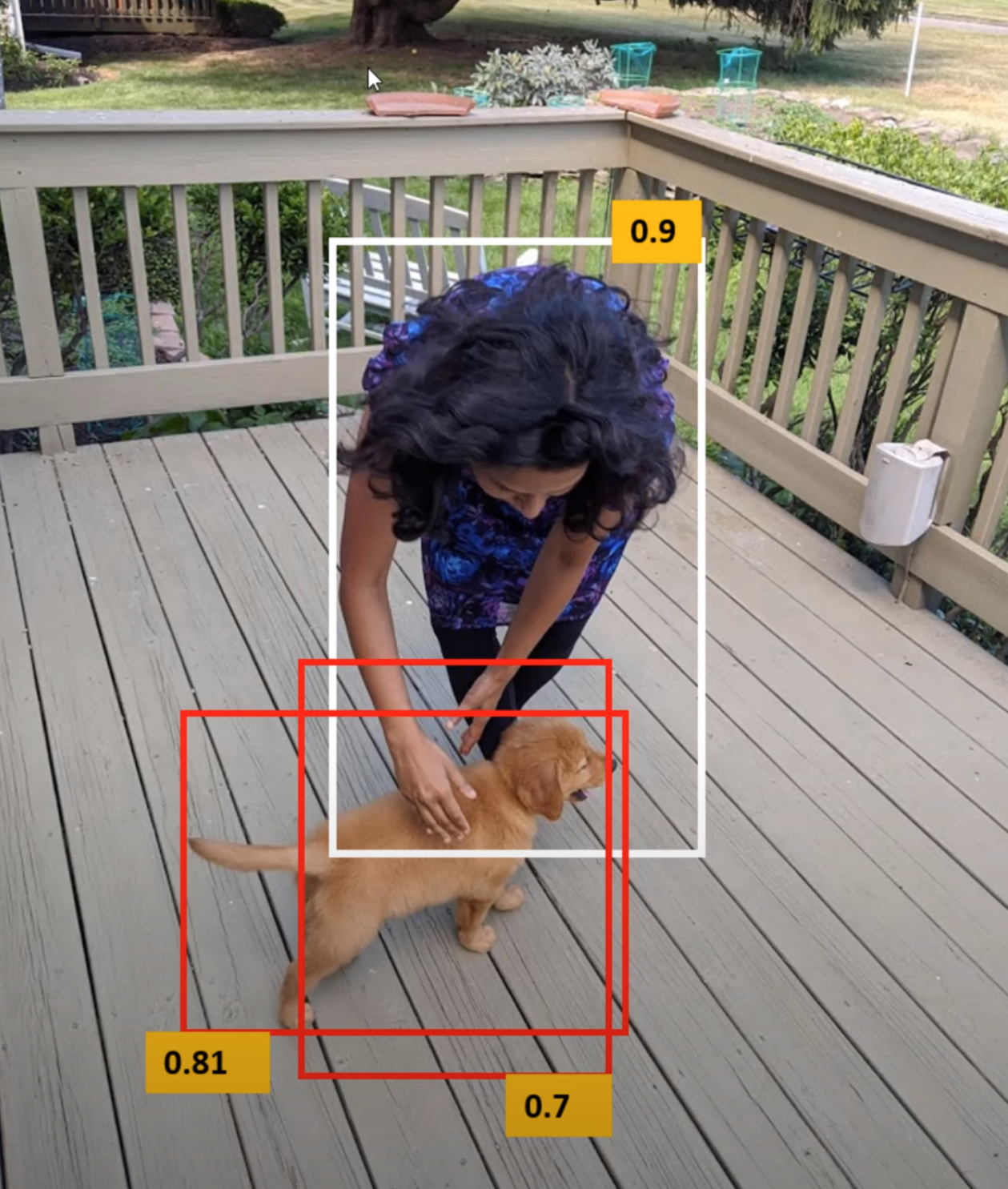
Grid containing more than one object
- Multiple anchor boxes for a single grid

If the grid cells are small enough, then it will be difficult to have many objects in one cell. However, if we have many objects for a single grid cell, then it is difficult for YOLO to deal with them.
YOLO History
- First introduced by Joseph Redmon, the latest being YOLO v8.
- YOLO V1 - 2016
- YOLO V2 - 2017
- YOLO V3 - 2018
- YOLO V4 - 2020
- YOLO v6 - 2022
YOLO Evolution
YOLO
- YOLO used a CNN model pretrained on ImageNet

YOLO v2
- Used a different CNN backbone called Darknet-19, a variant of the VGG Architecture
- Introduced anchor boxes (same size), YOLO v2 uses a combination of the anchor boxes and the predicted offsets to determine the final bounding box. This allows the algorithm to handle a wider range of object sizes and aspect ratios
- Used Batch normalization
- Multi-scale training - Training the model on images at multiple scales and then averaging the predictions
- Also introduced a new loss function suited to object detection
YOLO v3
- New CNN architecture called Darknet-53, a variant of ResNet designed for object detection
- Anchor boxes with different scales and aspect ratios.
- Introduced
Feature pyramid networks(FPN) - a CNN architecture used to detect object at multiple scales. They construct a pyramid of feature maps, with each level of the pyramid being used to detect objects at a different scale. This helps to improve the detection performance on small objects, as the model is able to see the objects at multiple scales.
YOLO V4
- Joseph Redmond left developing YOLO citing ethical concerns
- Use a new CNN architecture called CSPNet “Cross Stage Partial Network”, a variant of ResNet
- It used a new method to generate anchor boxes called, “K-means clustering.” It involves using a clustering algorithm to group the ground truth bounding boxes into clusters and then using the centroids of the clusters as the anchor boxes. This allows the anchor boxes to be more closely aligned with the detected objects’ size and shape.
- It introduced “GHM loss” - a variant of focal loss to deal with imbalanced datasets.
- Improved the architecture of FPN used in YOLO V3
YOLO v5
- Maintained by
Ultralytics - It uses a complex architecture called
EfficientDet*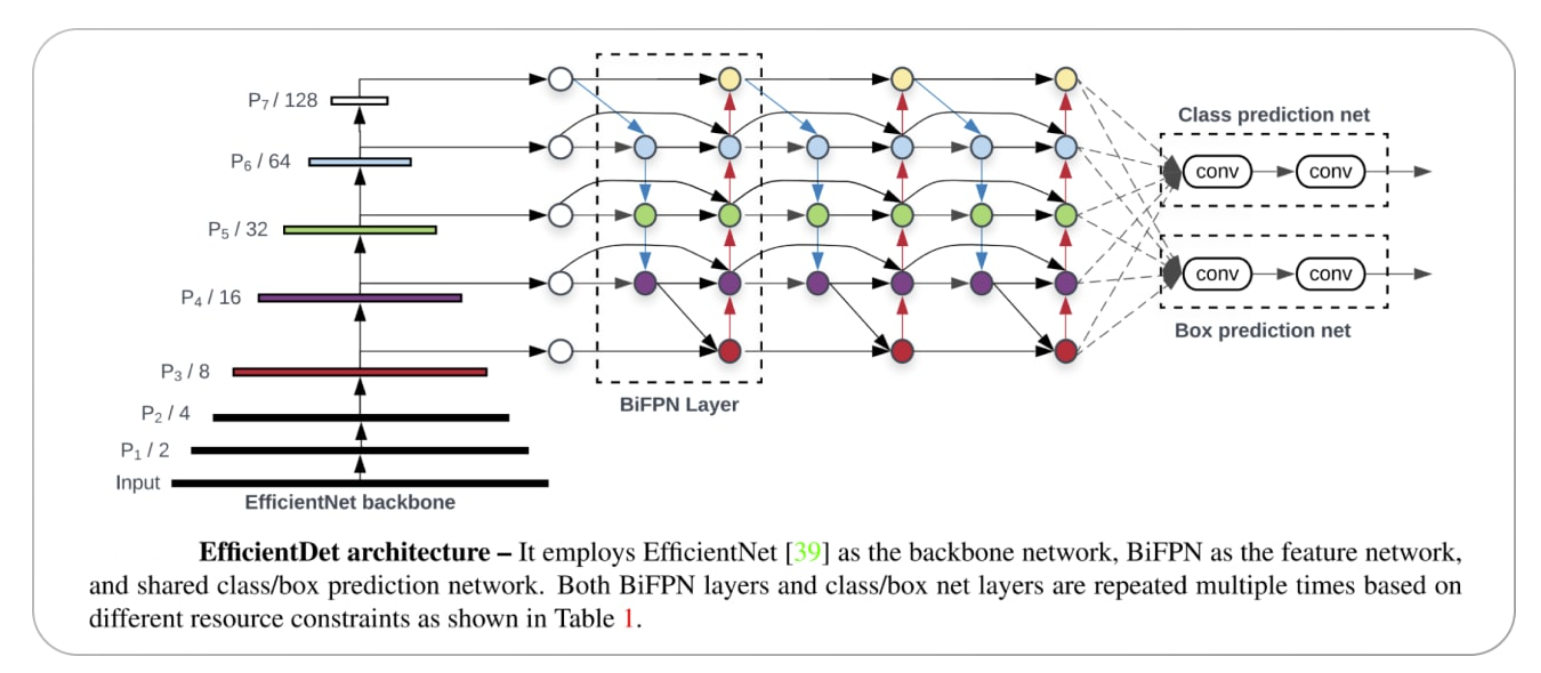
- Trained on D5 dataset, which includes 600 object categories
- Uses a new method for generating boxes called “dynamic anchor boxes”
- It uses a concept called
spatial pyramid pooling(SPP) - a type of pooling layer used to reduce the spatial dimensions of the feature maps. (SPP was used in YOLO v4, in v5 it was improved) - Introduced CIoU - a variant of IoU loss designed to improve the model’s performance on imbalanced datasets
YOLO v6
- It uses a variant of EfficientNet called EfficientNet-L2
- It ntroduced a new method for generating the anchor boxes, called “dense anchor boxes.”
YOLO v7
- Uses nine anchor boxes
- It uses “focal loss”
- Process images at higher resolution*
- It introduced a new method for generating the anchor boxes, called “dense anchor boxes.”
