Catboost
Catboost is a Newton boosting algorithm
Newton Boosting + Ordering = CatBoost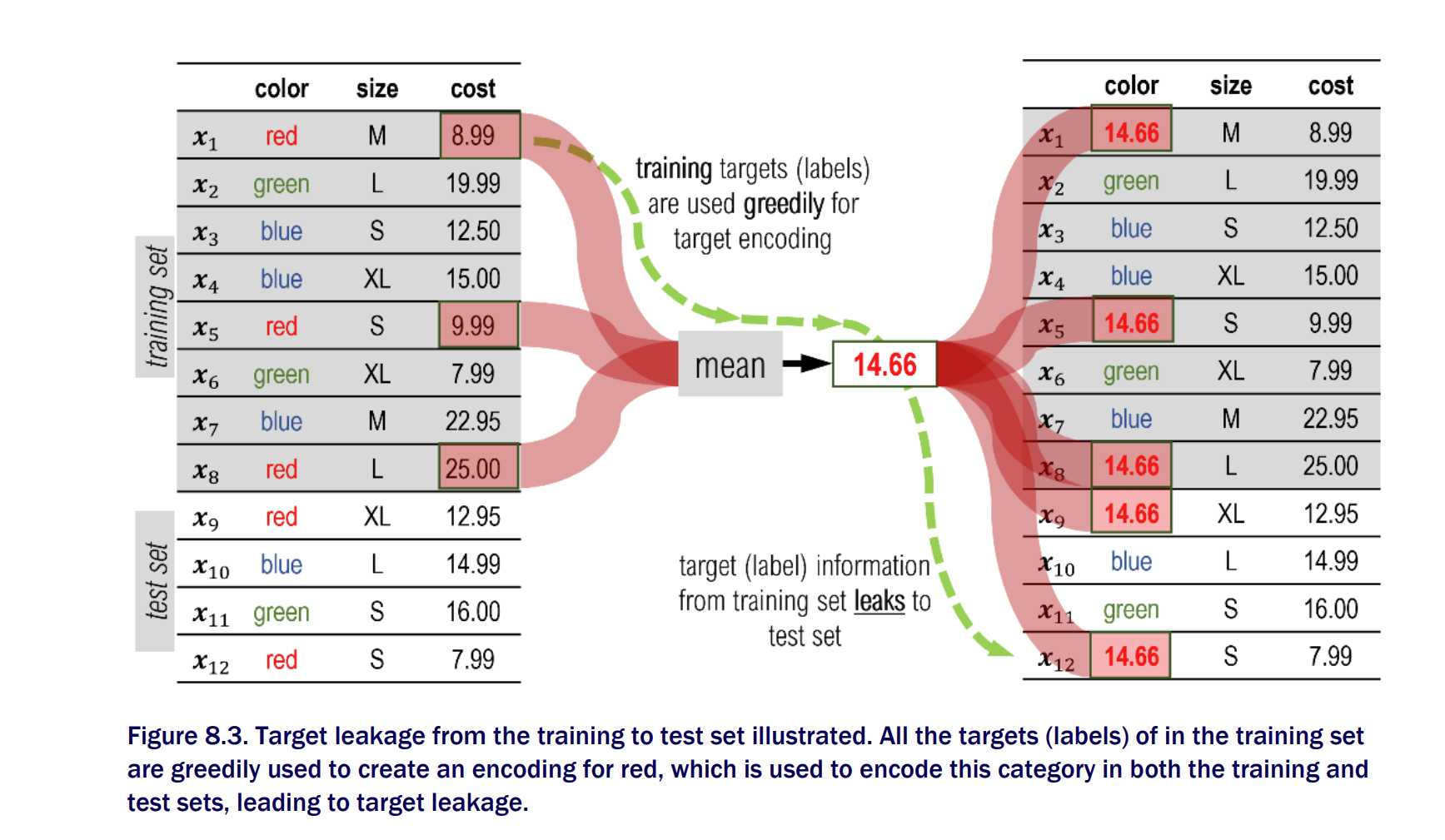
Target Leakage 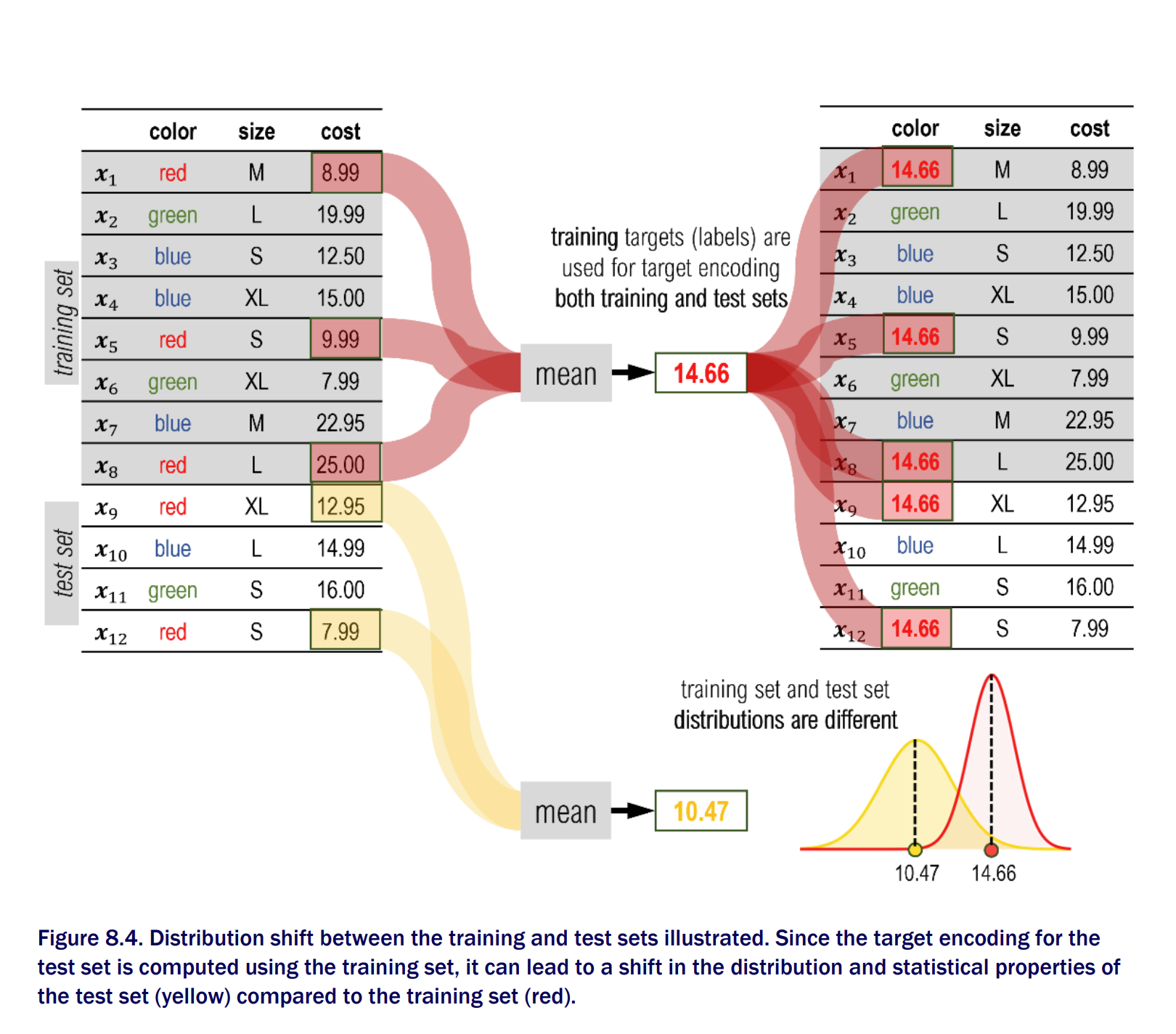
Prediction Shift 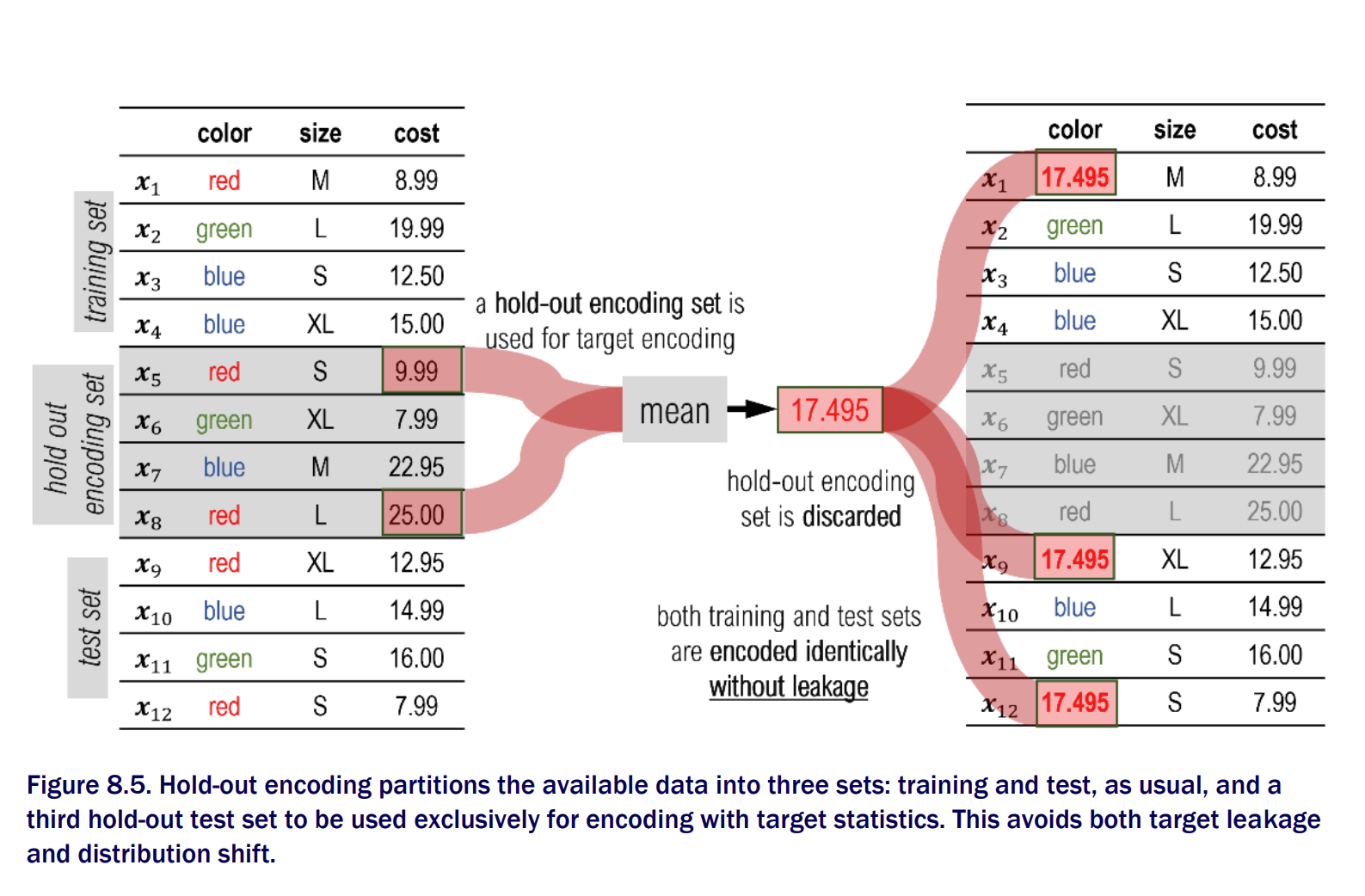
Hold out encoding 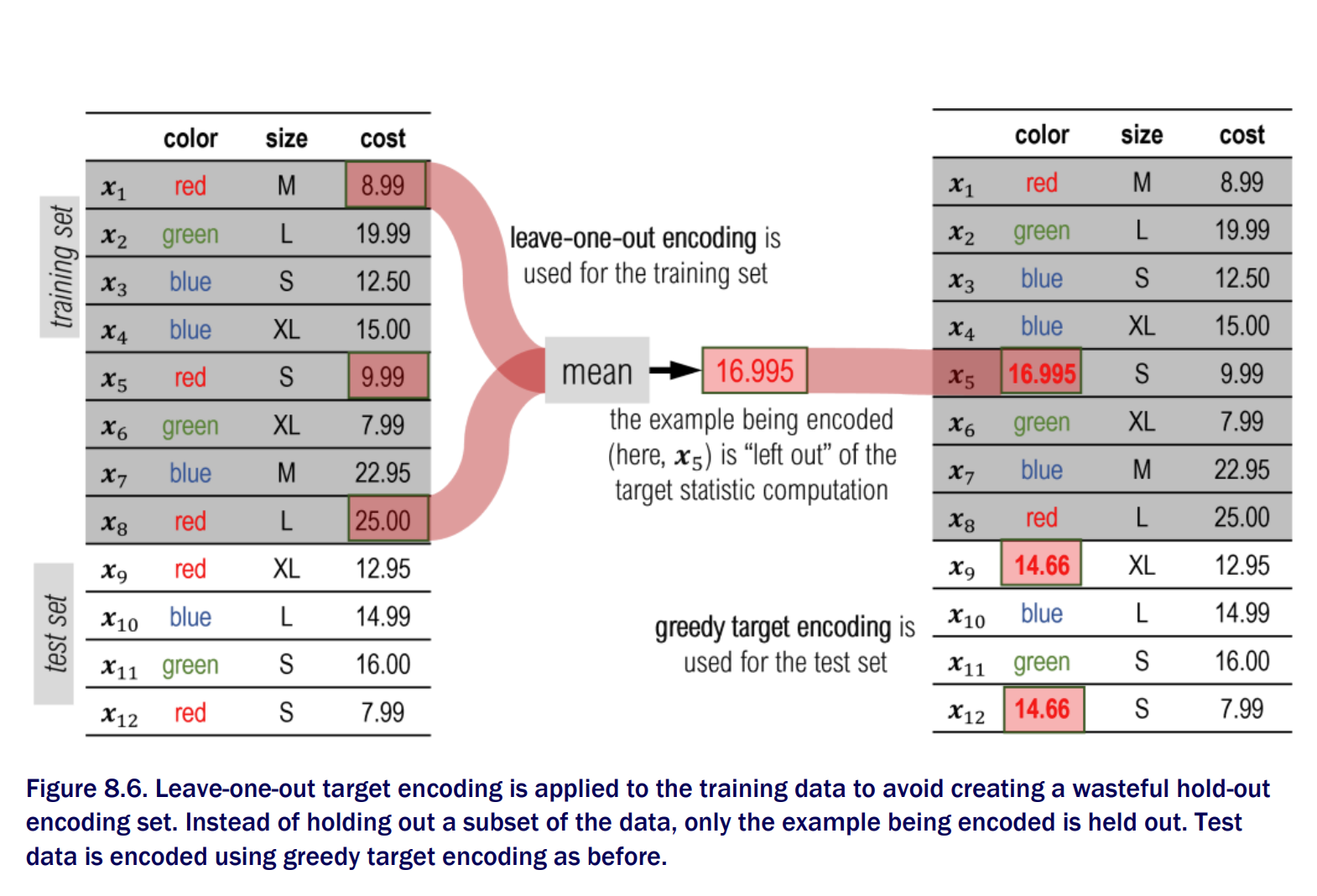
Leave one out encoding does not fully eliminate target leakage and prediction shift issues CatBoost introduces three major modifications to classical Newton Boosting approach
- It is specialized to categorical features
- It uses ordered boosting as its underlying approach which allows it to address data leakage and prediction shift
- It uses
oblivious decision treesas base estimators which often leads to faster training times
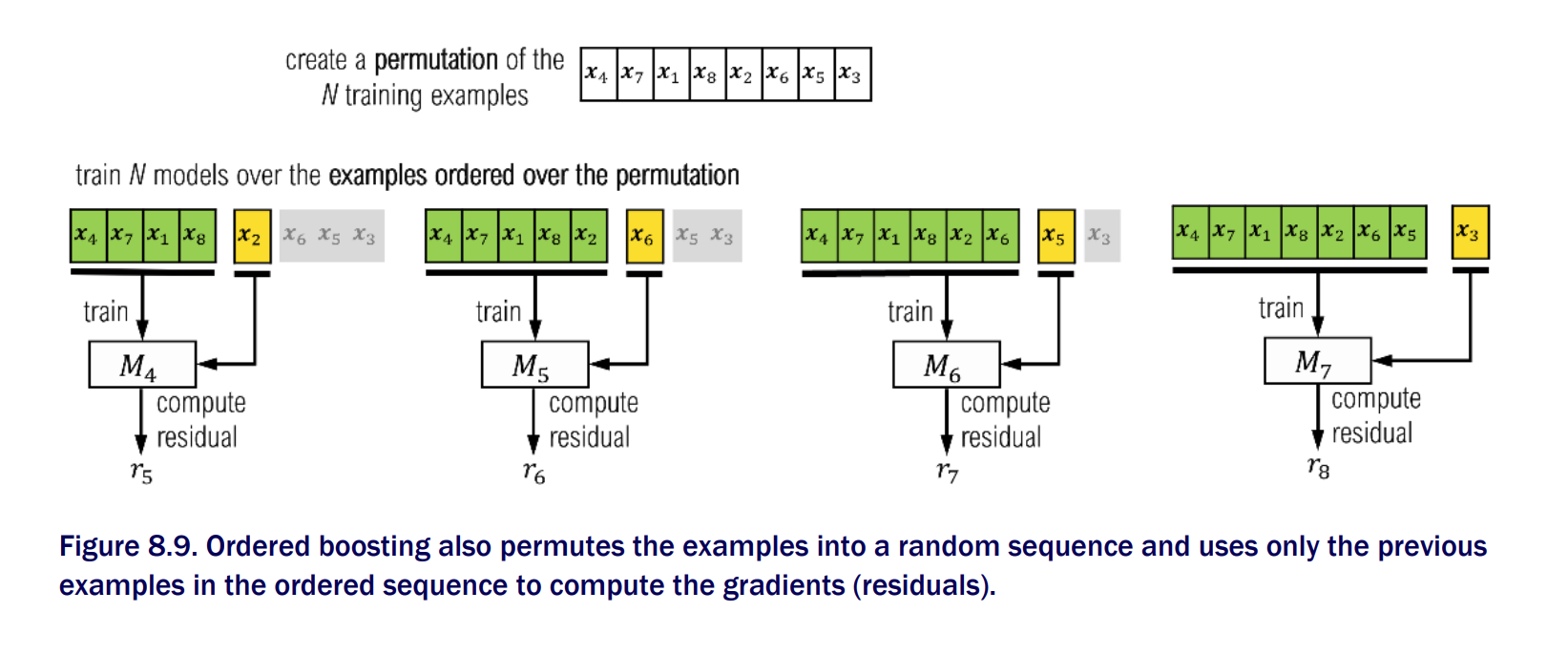
Catboost addresses prediction shift by using permutation for ordering training examples
Ordered Target Statistics
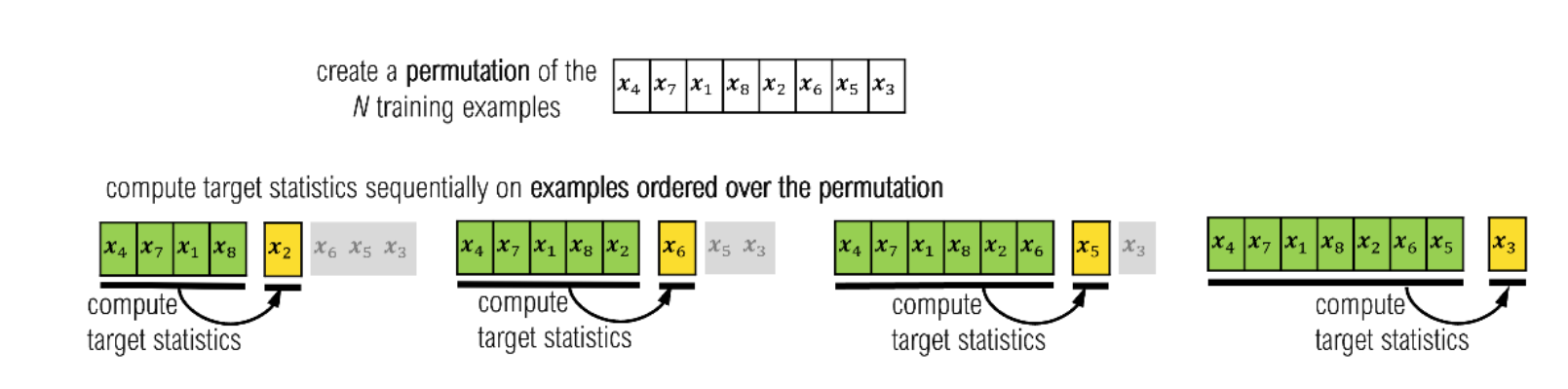
Ordered Target Statistics One downside to this approach is that training examples that occur early in a randomized sequence are encoded with far fewer examples.
To compensate for this in practice and increase robustness, CatBoost maintains several sequences, or “histories” which are, in turn, randomly chosen. This means that CatBoost recomputes target statistics for categorical variables at each iteration
Ordered Boosting
- In addition to issues with encoding features, gradient and Newton boosting both reuse data between iterations, leading to a gradient distribution shift, which ultimately causes a further prediction shift. That is to say, even if we didn’t have categorical features, we would still have a prediction shift problem, which would bias our estimates of model generalization!
Oblivious Decision Trees
- Oblivious decision trees use the same splitting criterion in all the nodes across an entire level/depth of the tree

Oblivious decision trees lead to less split criteria, as opposed to the standard decision tree. This makes them easier and more efficient to learn, which has the effect of speeding up overall training.
Oblivious trees are balanced and symmetric, making them less complex and less prone to overfitting
Tips to handle Categorical Features
- use
string similarityto handle spelling mistakes in categorical features. (String similarity approaches - character based or token based) dirty-catpackage provides functionality off-the-shelf. Different methods available for handling dirty categories are

Reference
- Manning book - Ensemble methods for Machine learning