Transformer
The Transformer is a model which uses attention to boost the speed of the training. The transformer lends itself to parallelization.
The transformers will consist of encoders and decoders.
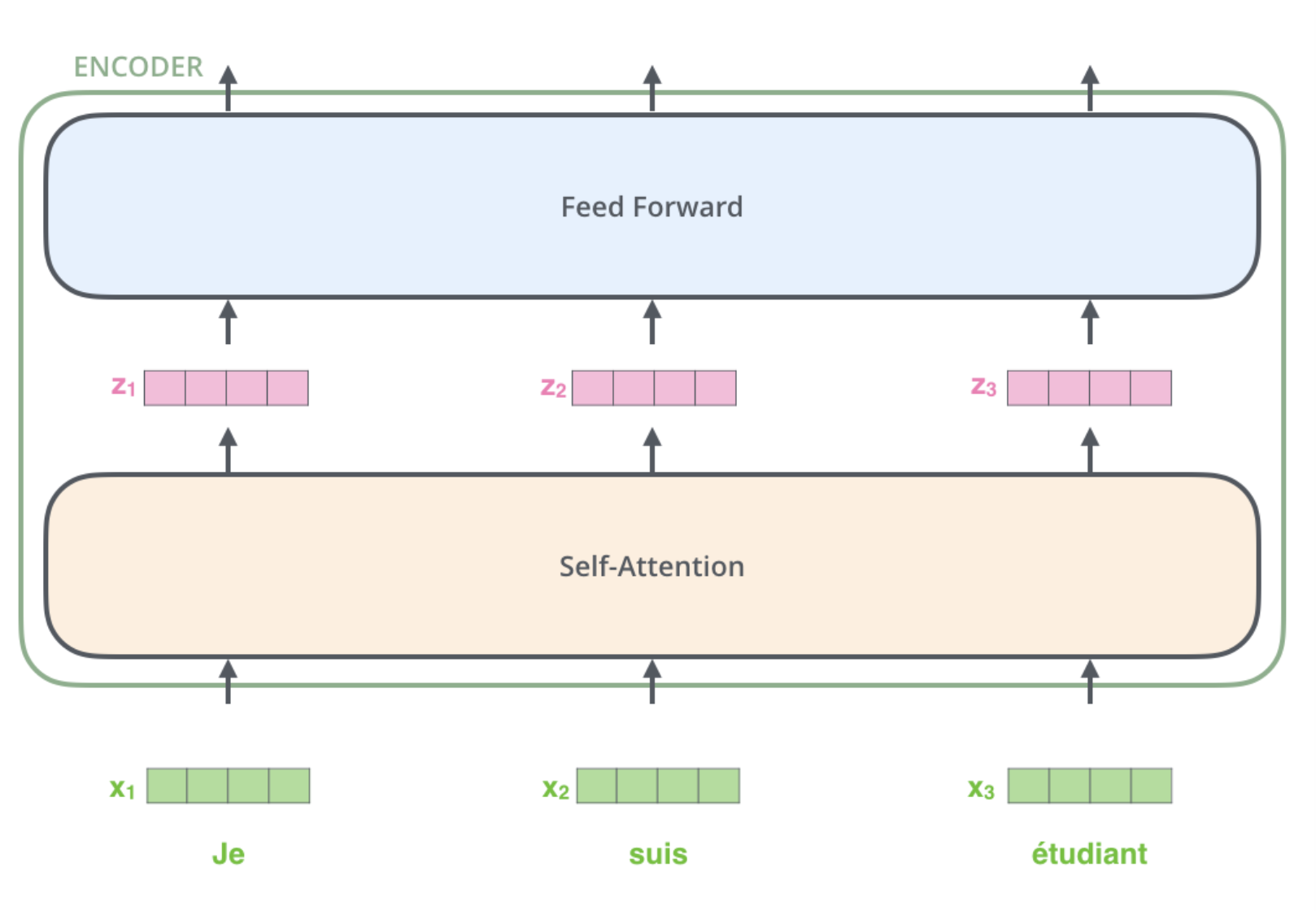
An encoder consists two sub-layers self-attention and feed forward neural network. A decoder along with these two sub-layers will also consist of an attention layer between them to focus on relevant parts of the input sentence.
![]()
Encoder
Embedding happens in the bottom most encoder. The word in each position flows through its own path in the self-attention layer. The feed-forward layer does not have those dependencies and various paths can be executed in parallel.
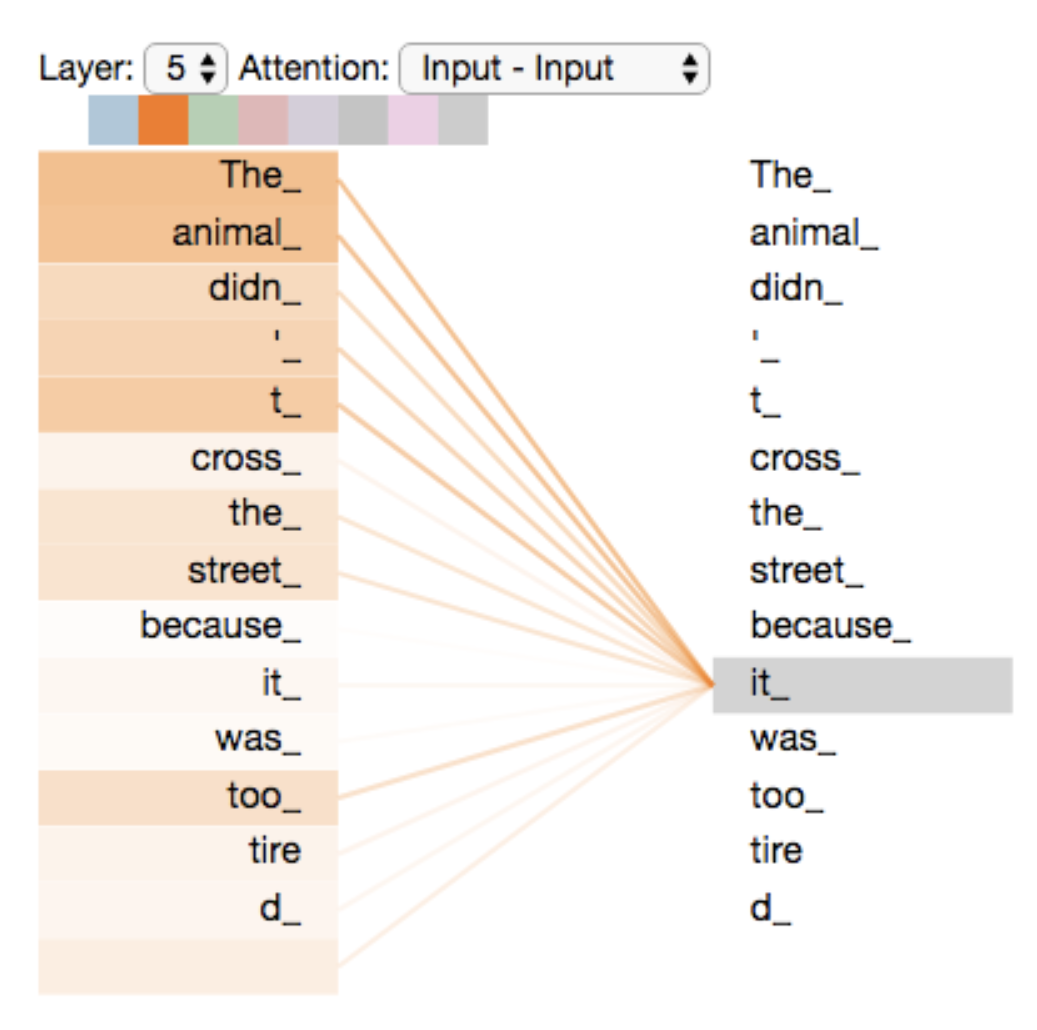
Self-Attention
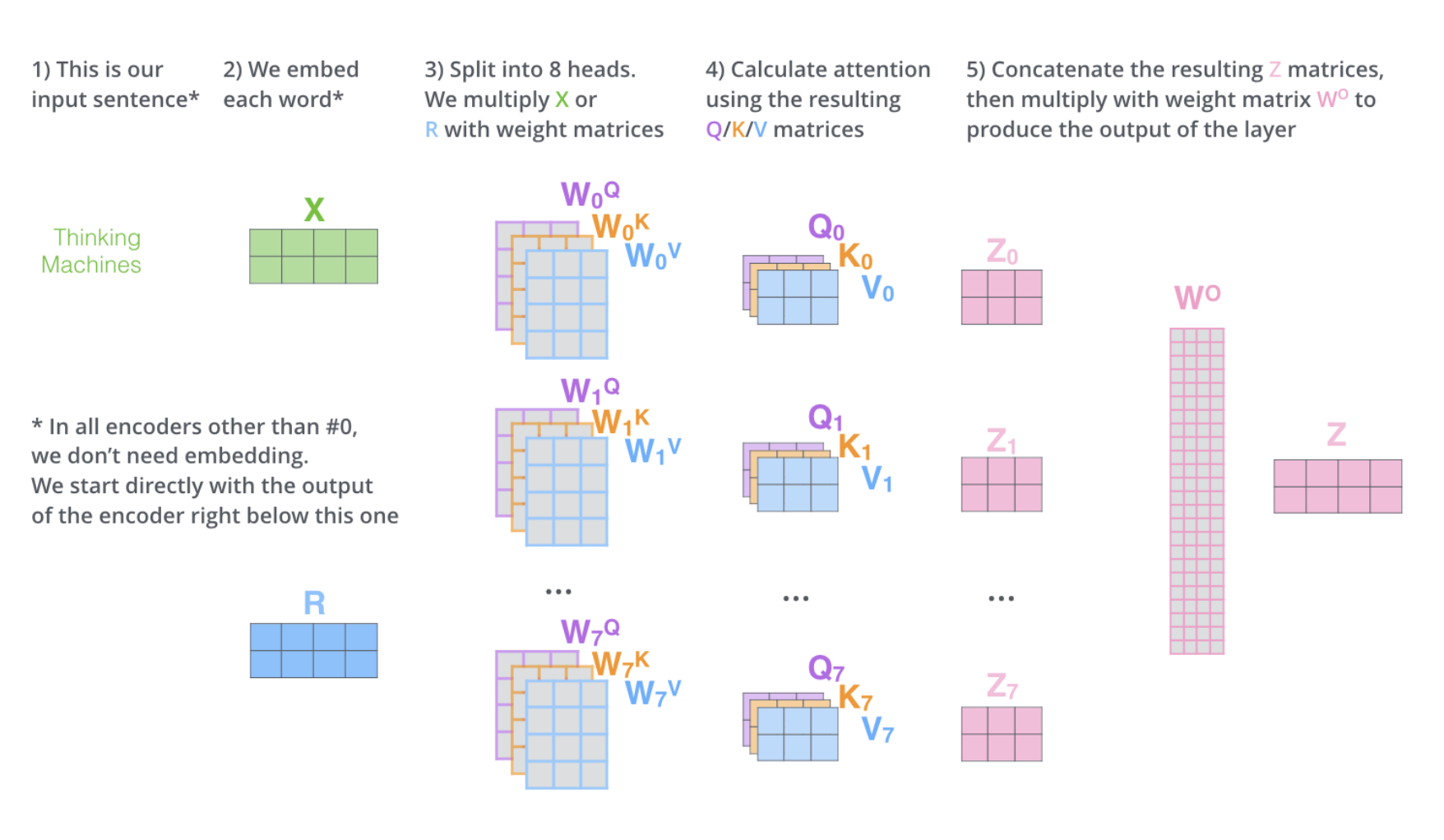
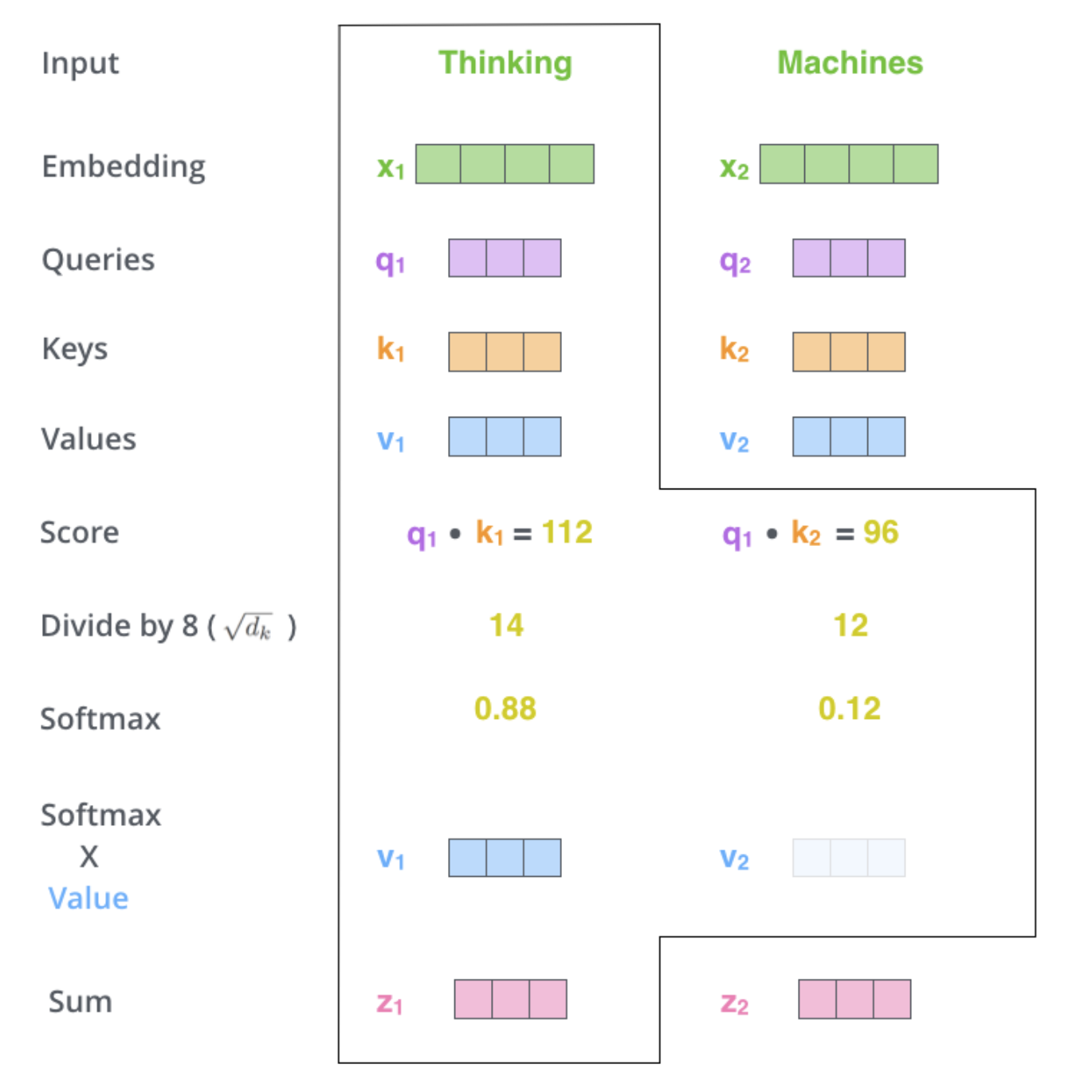
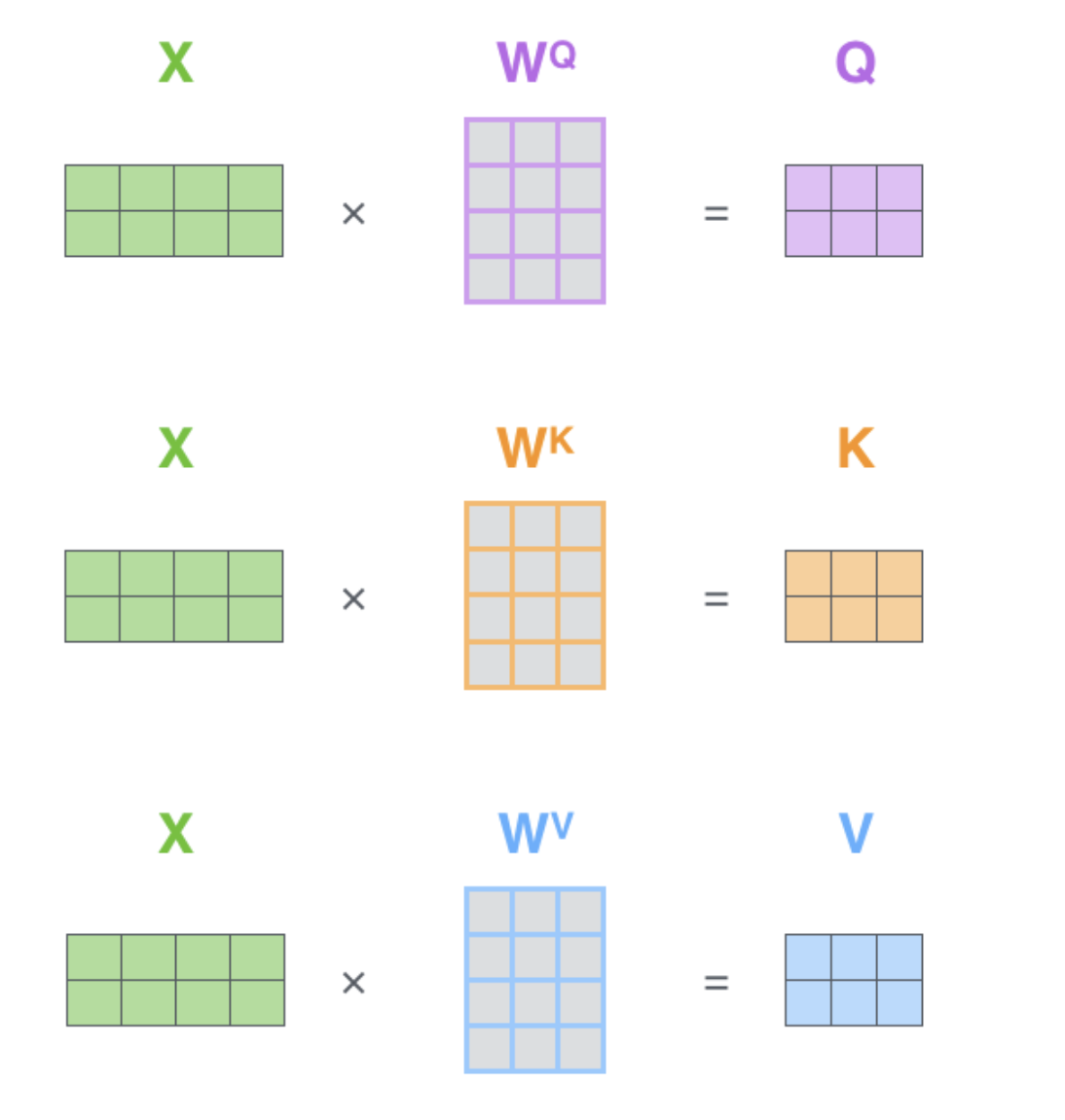
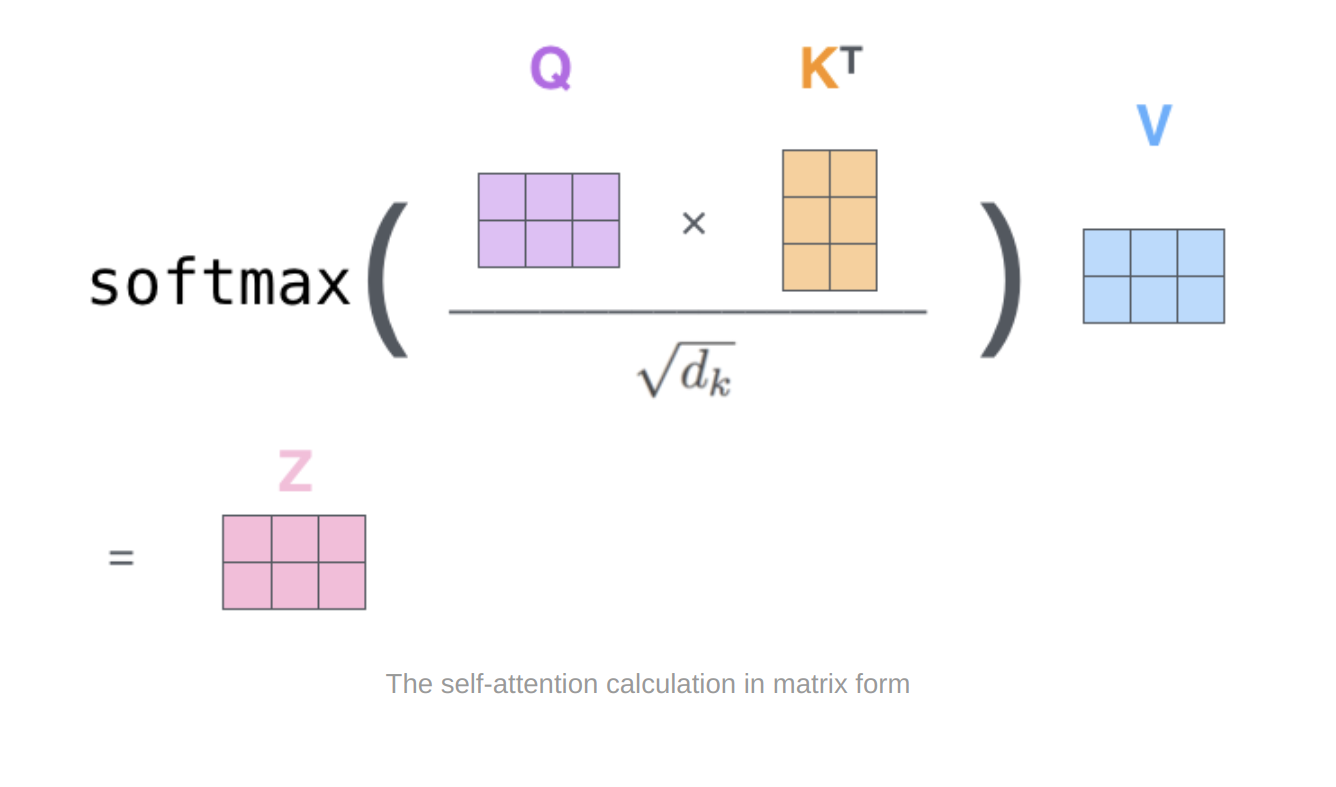
Multi-headed attention
It expands the model’s ability to focus on different positions.
It gives the attention layer multiple “representation subspaces”
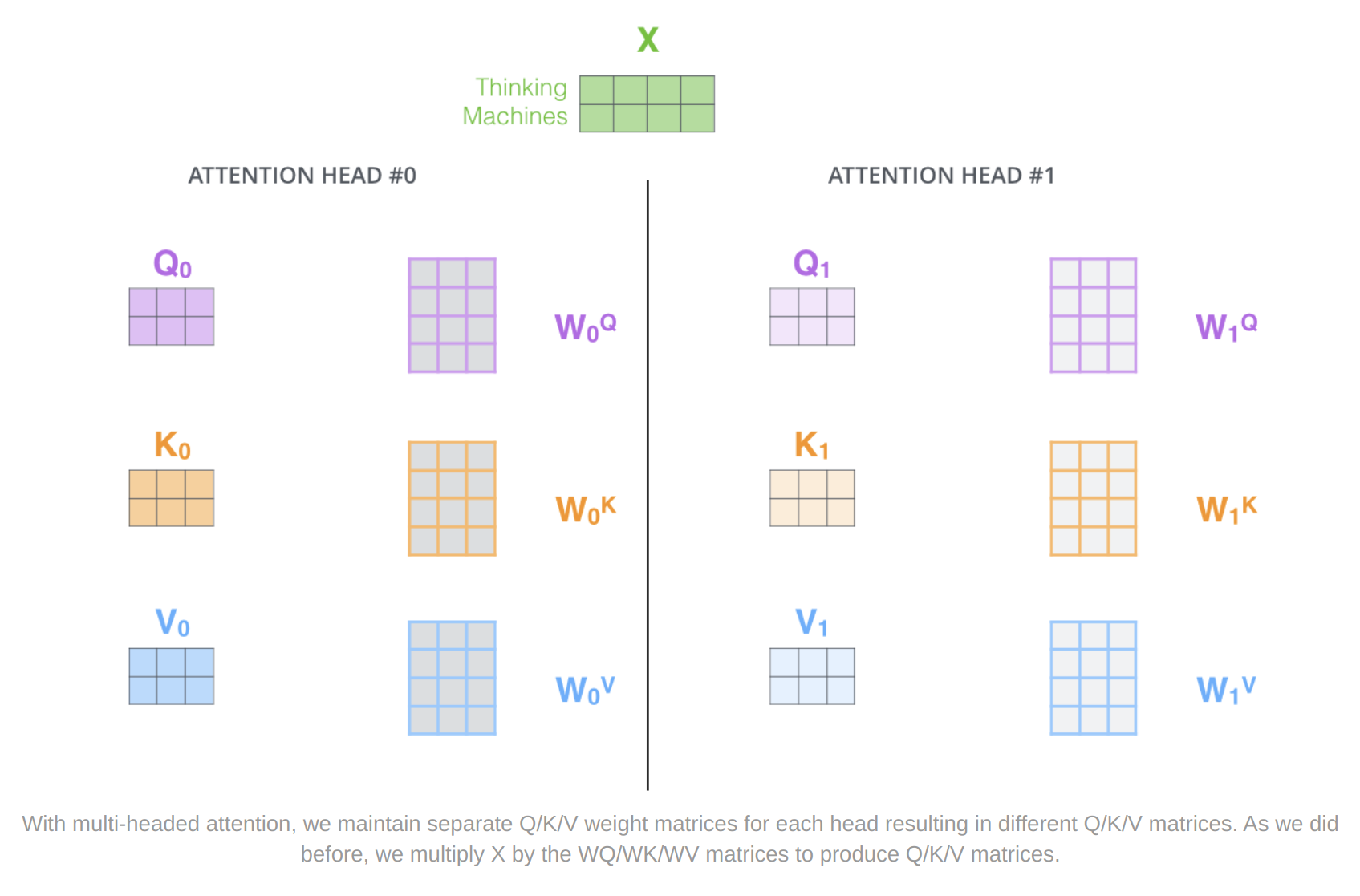
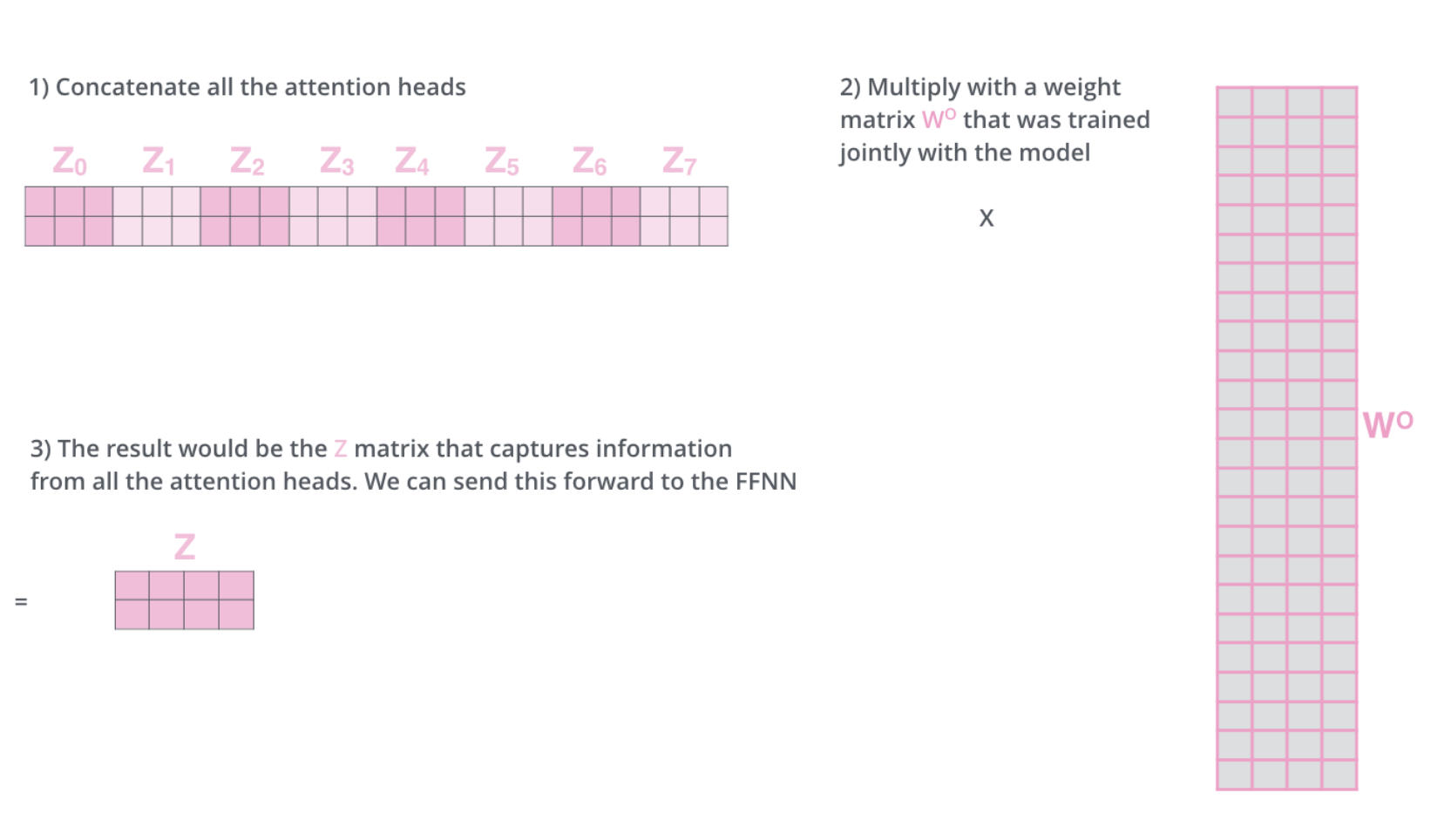
In the original paper, eight attention heads were used. This way we will end up with eight different Z matrices. The feed-forward layer is not expecting eight matrices – it’s expecting a single matrix (a vector for each word). So we need a way to condense these eight down into a single matrix.
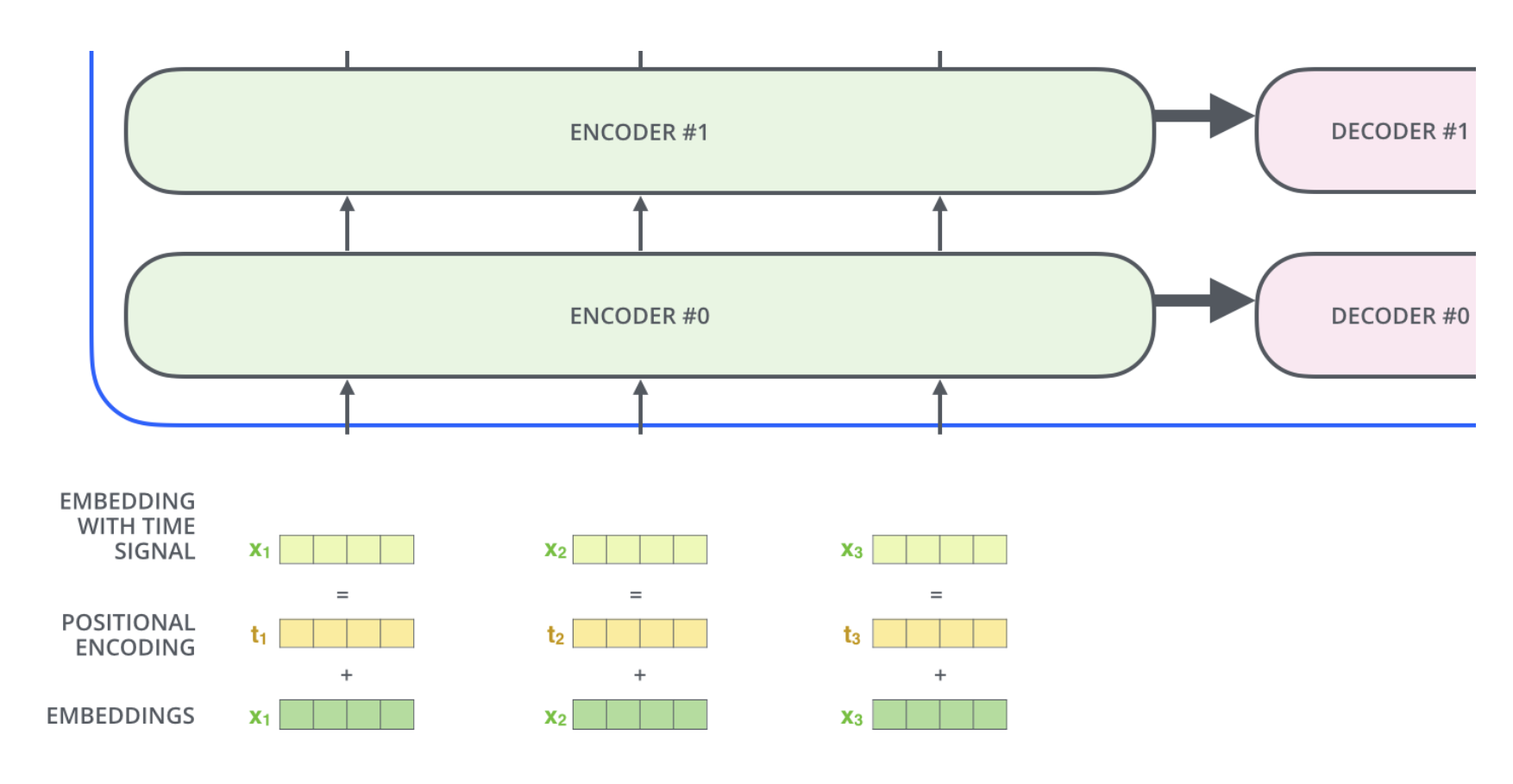
Positional Encoding
This will account for the order of the words in the input sequence.
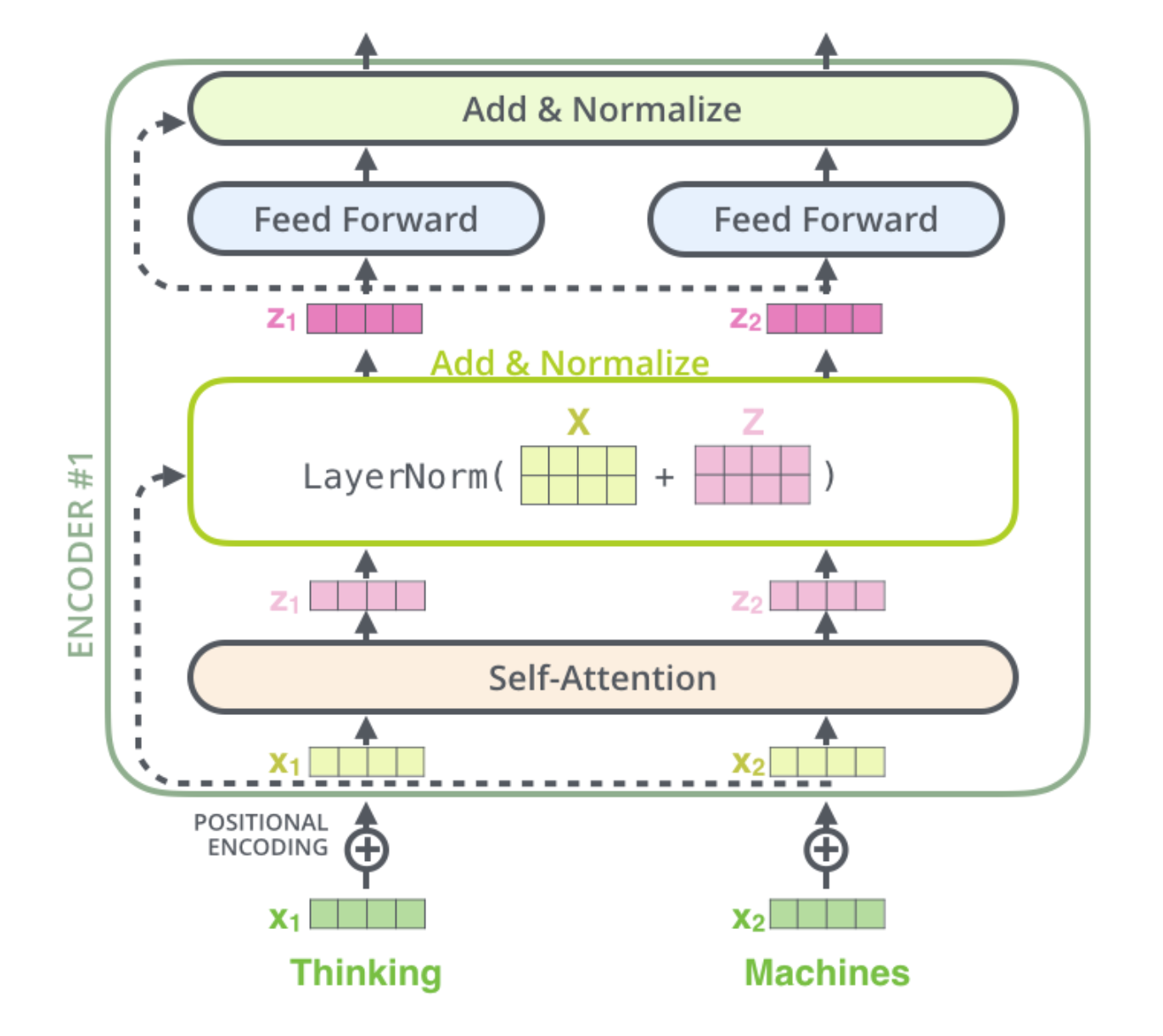
Residuals
Each sub-layer in each encoder has a residual connection around it, and is follwed by a layer-normalization step
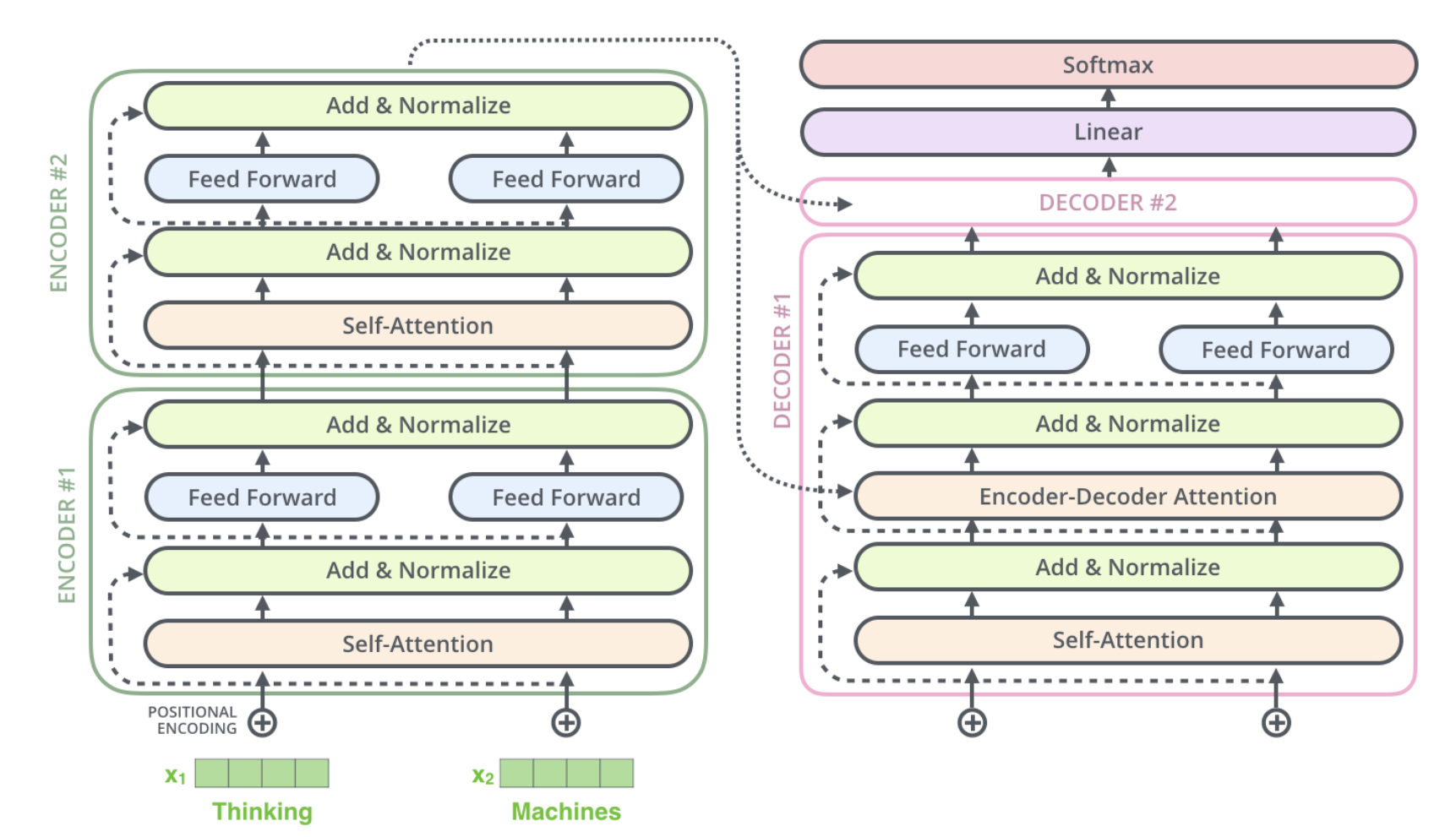
Decoder
The encoder start by processing the input sequence. The output of the top encoder is then transformed into a set of attention vectors K and V. These are to be used by each decoder in its “encoder-decoder attention” layer which helps the decoder focus on appropriate places in the input sequence.
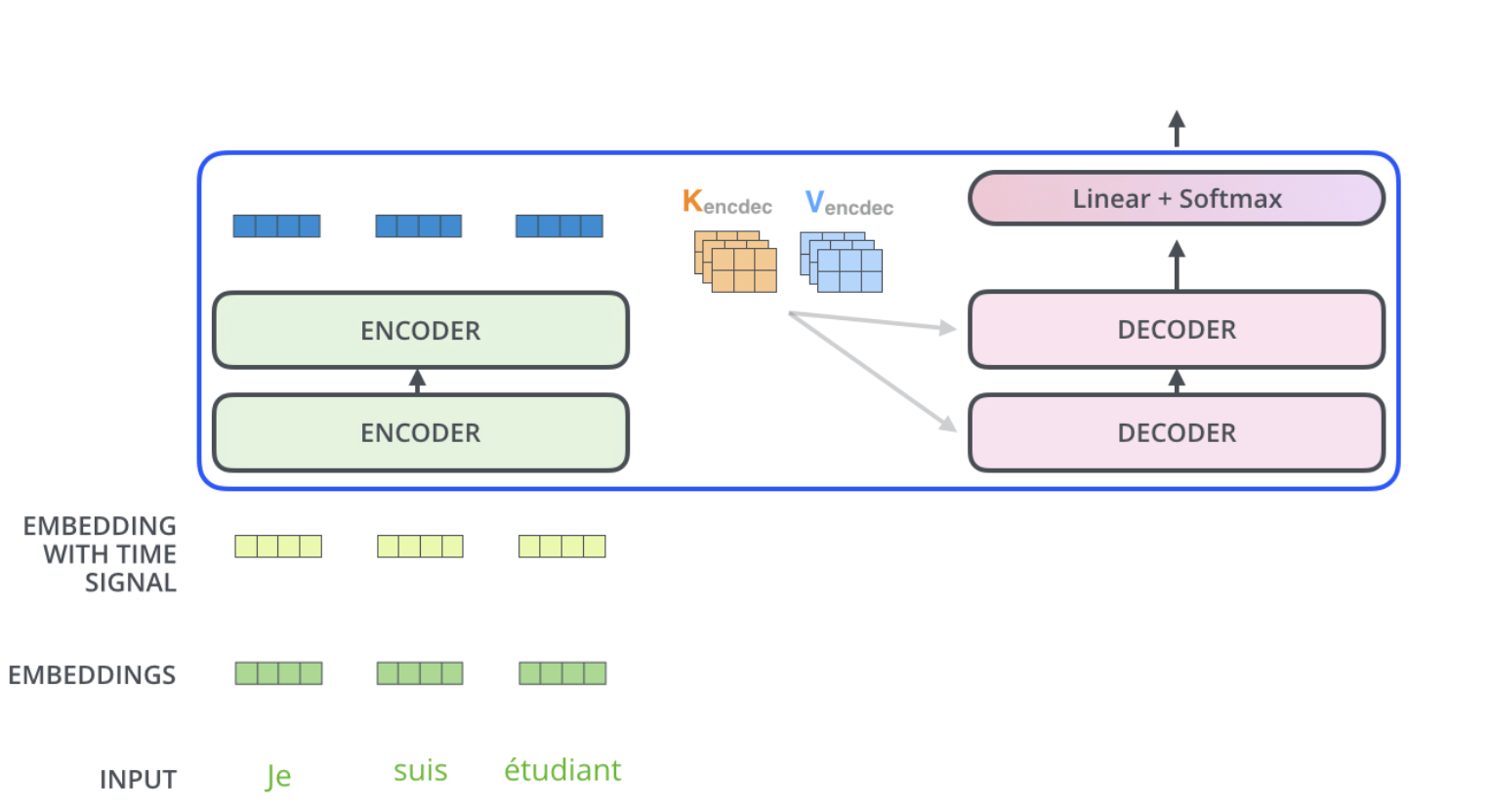
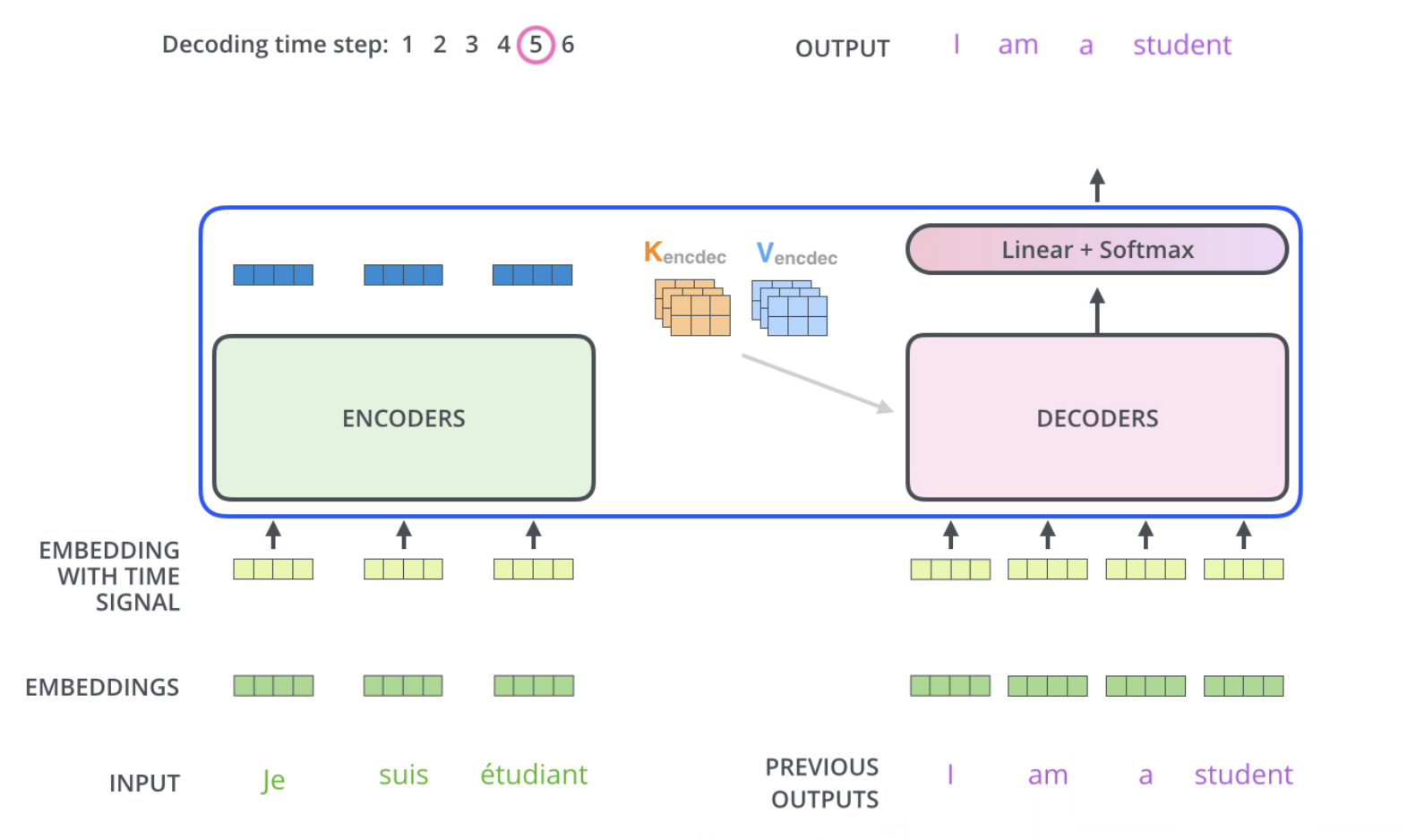
The following steps repeat the process until a special symbol is reached indicating the transformer decoder has completed its output. The output of each step is fed to the bottom decoder in the next time step, and the decoders bubble up their decoding results just like the encoders did. And just like we did with the encoder inputs, we embed and add positional encoding to those decoder inputs to indicate the position of each word.
In the decoder, the self-attention layer is only allowed to attend to earlier positions in the output sequence. This is done by masking future positions (setting them to -inf) before the softmax step in the self-attention calculation.
The “Encoder-Decoder Attention” layer works just like multiheaded self-attention, except it creates its Queries matrix from the layer below it, and takes the Keys and Values matrix from the output of the encoder stack.
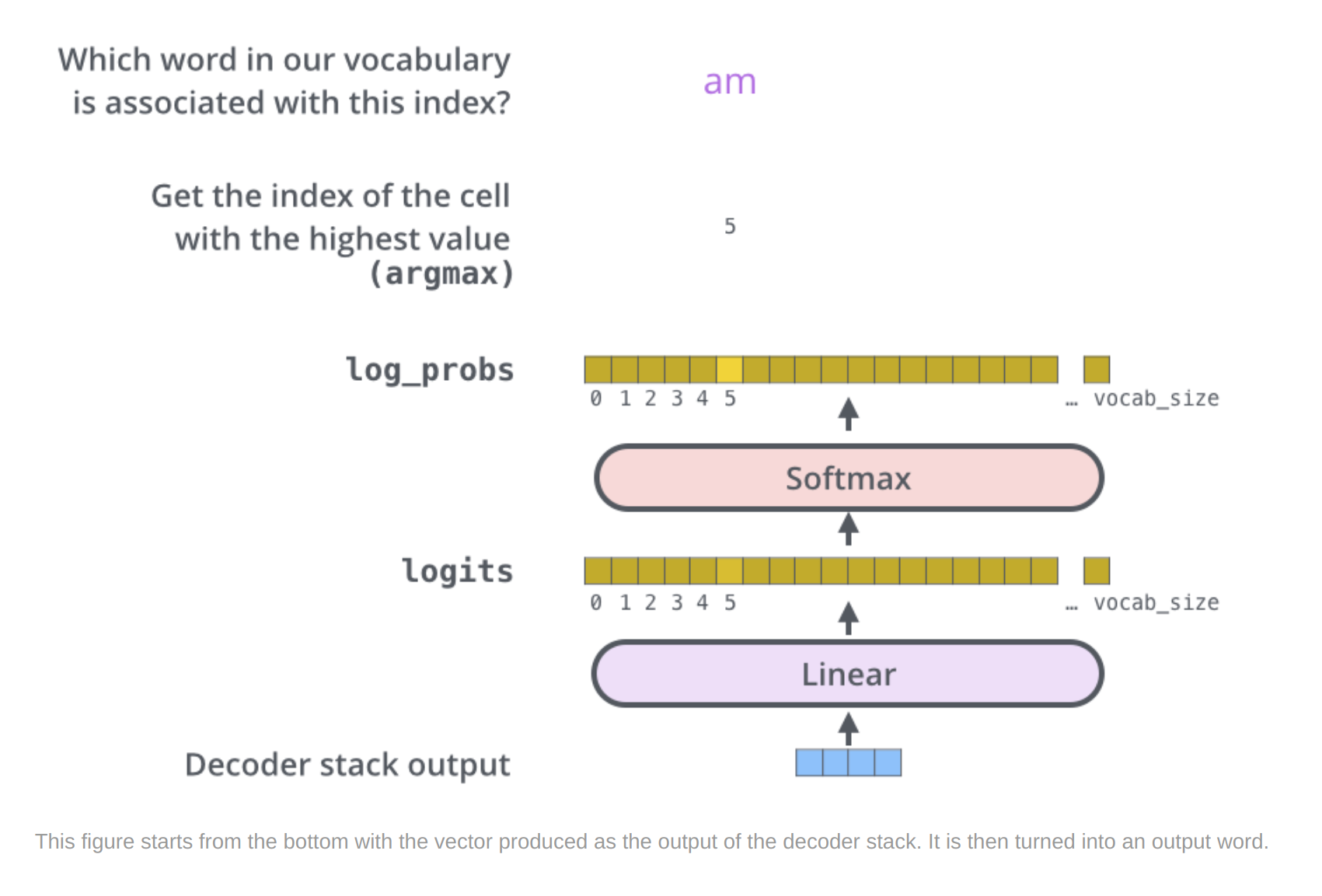
Final layer and Softmax Layer
The Linear layer is a simple fully connected neural network that projects the vector produced by the stack of decoders, into a much, much larger vector called a logits vector.
Let’s assume that our model knows 10,000 unique English words (our model’s “output vocabulary”) that it’s learned from its training dataset. This would make the logits vector 10,000 cells wide – each cell corresponding to the score of a unique word. That is how we interpret the output of the model followed by the Linear layer.
The softmax layer then turns those scores into probabilities (all positive, all add up to 1.0). The cell with the highest probability is chosen, and the word associated with it is produced as the output for this time step.