Model Development
Model Selection
- When considering what model to use, it’s important to consider not only the model’s performance, measured by metrics such as accuracy, F1 score, and log loss, but also its other properties, such as how much data, compute, and time it needs to train, what’s its inference latency, and interpretability.
- Avoid the state-of-the-art trap
- Researchers often only evaluate models in academic settings, which means that a model being state of the art often means that it performs better than existing models on some static datasets. It doesn’t mean that this model will be fast enough or cheap enough for you to implement. It doesn’t even mean that this model will perform better than other models on your data.
- Start with the simplest models
- Simplest models are not always the same as models with the least effort. For example, pretrained BERT models are complex, but they require little effort to get started with, especially if you use a ready-made implementation like the one in Hugging Face’s Transformer. In this case, it’s not a bad idea to use the complex solution, given that the community around this solution is well developed enough to help you get through any problems you might encounter. However, you might still want to experiment with simpler solutions to ensure that pretrained BERT is indeed better than those simpler solutions for your problem. Pretrained BERT might be low effort to start with, but it can be quite high effort to improve upon. Whereas if you start with a simpler model, there’ll be a lot of room for you to improve upon your model.
- Avoid human biases in selecting models
- Evaluate good performance now versus good performance later
- While evaluating models, you might want to take into account their potential for improvements in the near future, and how easy/difficult it is to achieve those improvements.
- A situation that I’ve encountered is when a team evaluates a simple neural network against a collaborative filtering model for making recommendations. When evaluating both models offline, the collaborative filtering model outperformed. However, the simple neural network can update itself with each incoming example, whereas the collaborative filtering has to look at all the data to update its underlying matrix. The team decided to deploy both the collaborative filtering model and the simple neural network. They used the collaborative filtering model to make predictions for users, and continually trained the simple neural network in production with new, incoming data. After two weeks, the simple neural network was able to outperform the collaborative filtering model.
- Evaluate trade-offs
- Understand the model’s assumptions
Ensembles
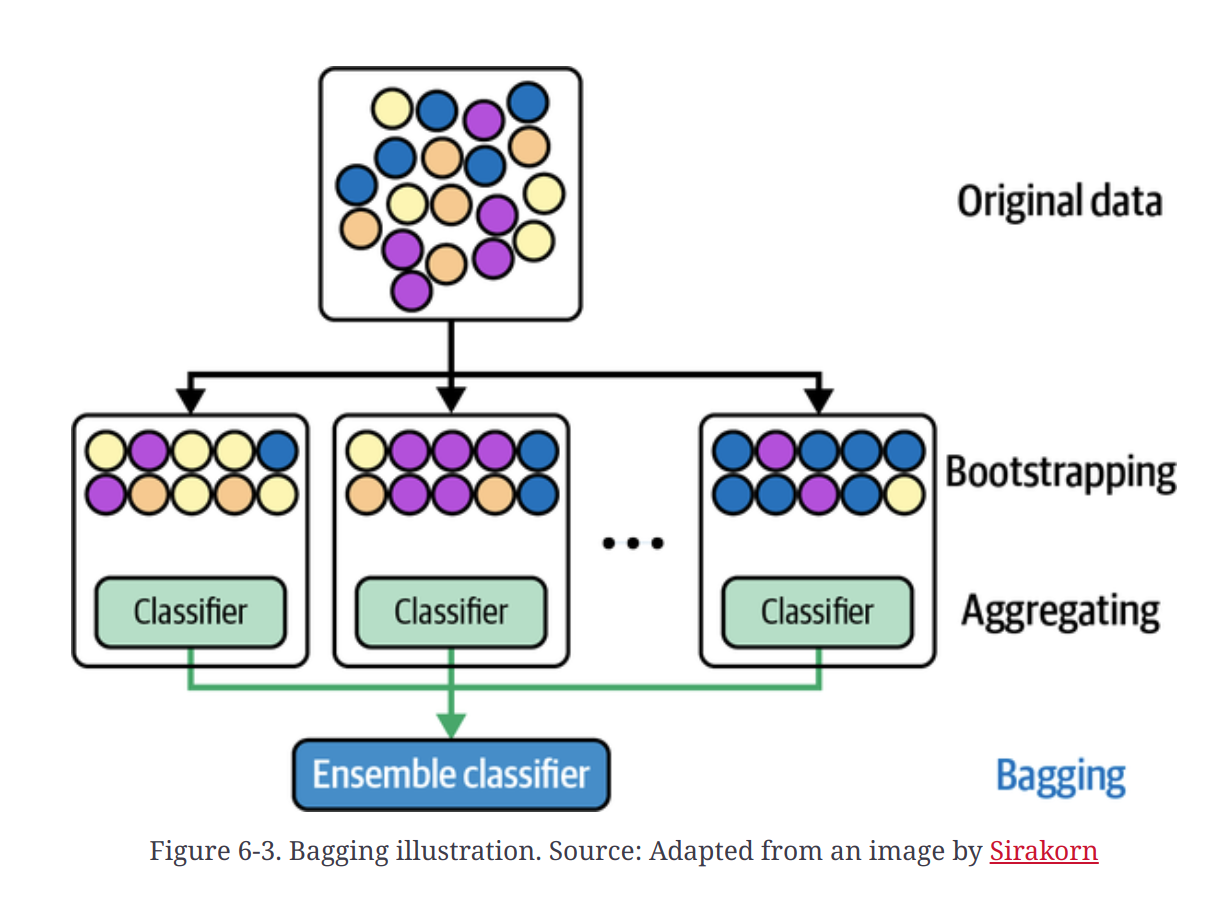
Bagging
- Bagging, shortened from bootstrap aggregating, is designed to improve both the training stability and accuracy of ML algorithms. It reduces variance and helps to avoid overfitting.
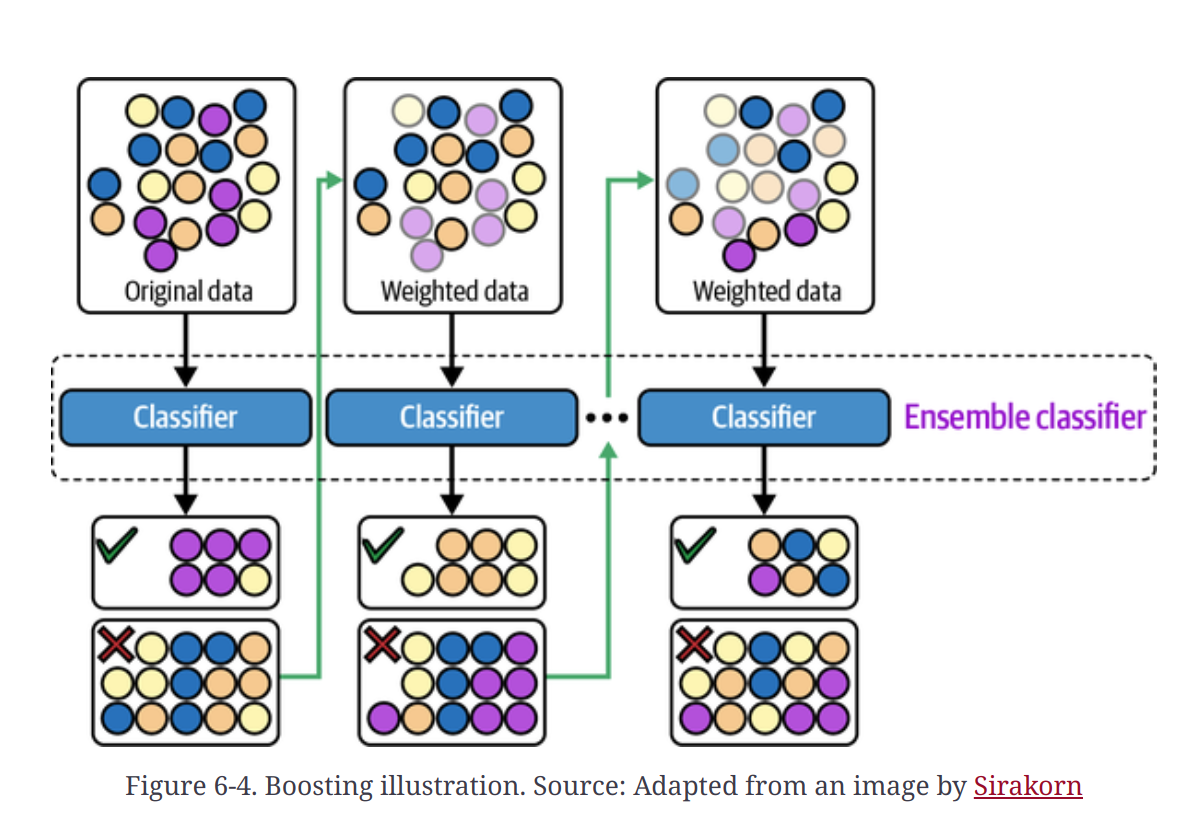
Boosting
- Boosting is a family of iterative ensemble algorithms that convert weak learners to strong ones. Each learner in this ensemble is trained on the same set of samples, but the samples are weighted differently among iterations. As a result, future weak learners focus more on the examples that previous weak learners misclassified.

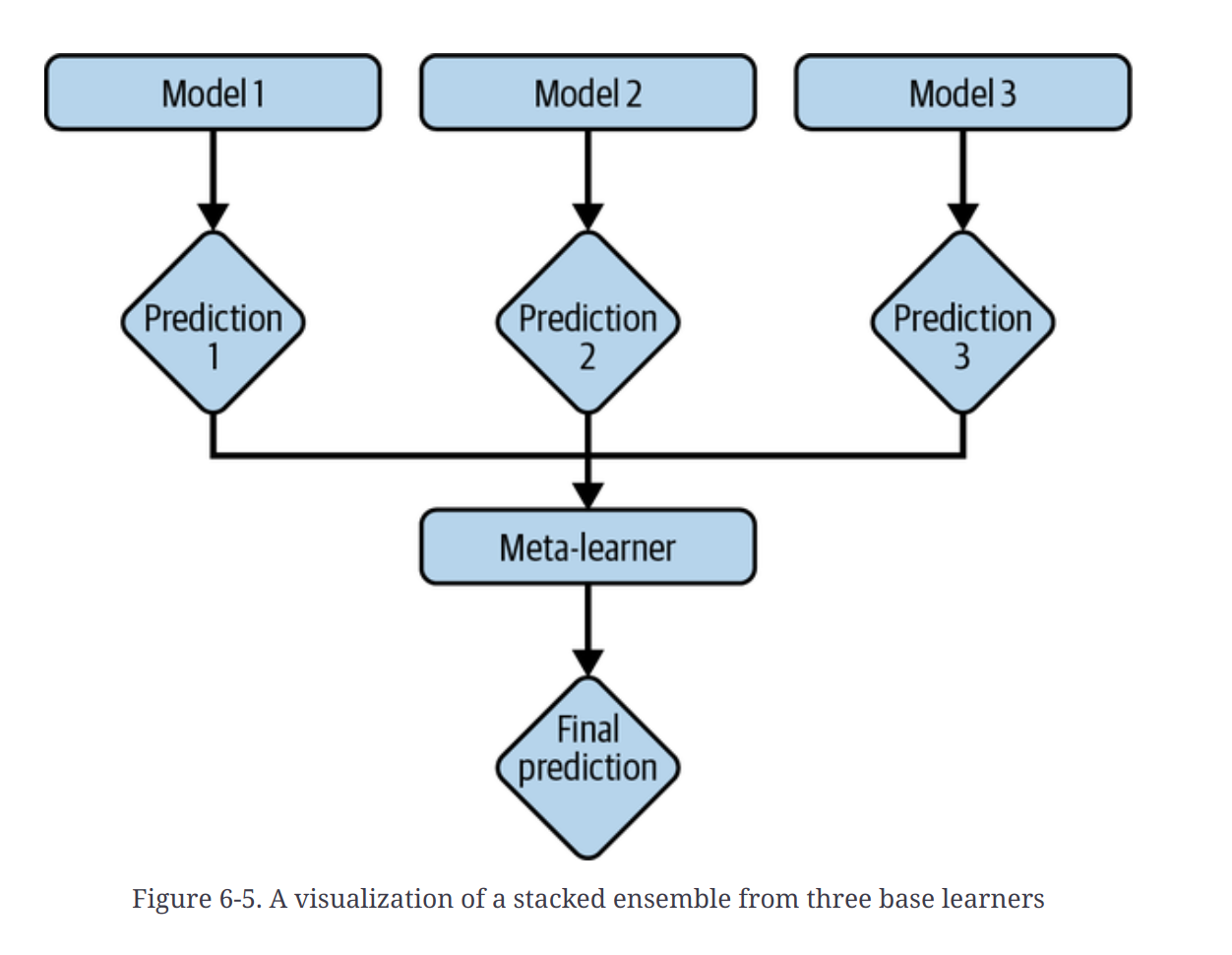
Stacking
Reference
Model Debugging
- Start simple and gradually add more components
- Overfit a single batch - If it’s for image recognition, overfit on 10 images and see if you can get the accuracy to be 100%, or if it’s for machine translation, overfit on 100 sentence pairs and see if you can get to a BLEU score of near 100. If it can’t overfit a small amount of data, there might be something wrong with your implementation.
- Set a random seed
Distributed Training
- Gradient-checkpointing
Data parallelism
- Each worker has its own copy of the whole model and does all the computation necessary for its copy of the model
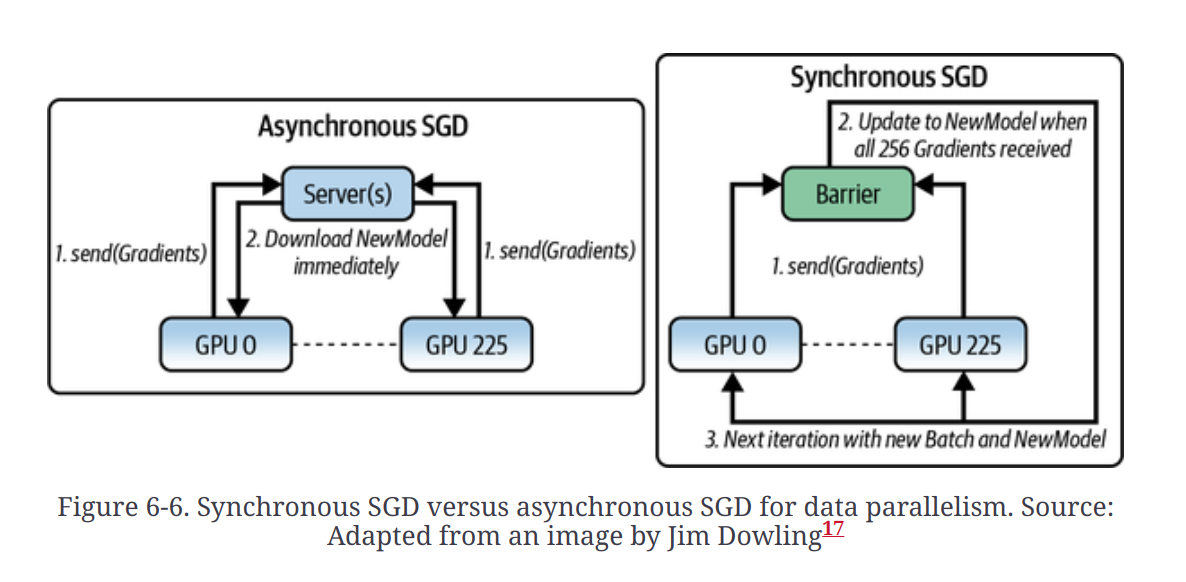
- Synchronous SGD and Asynchronous SGD - The way in which gradients are combined in parallel training
Model Parallelism
- Model parallelism is when different components of your model are trained on different machines
Pipeline parallelism

AutoML
Soft AutoML : Hyperparameter tuning
Hard AutoML: Architecture search and learned optimizer
- what if we replace the functions that specify the update rule with a neural network? How much to update the model’s weights will be calculated by this neural network. This approach results in learned optimizers, as opposed to hand-designed optimizers.