Training
- It’s a good practice to keep track of the origin of the data samples and labels
Natural labels
- Natural ground truth labels
- Feedback loop length is important to consider
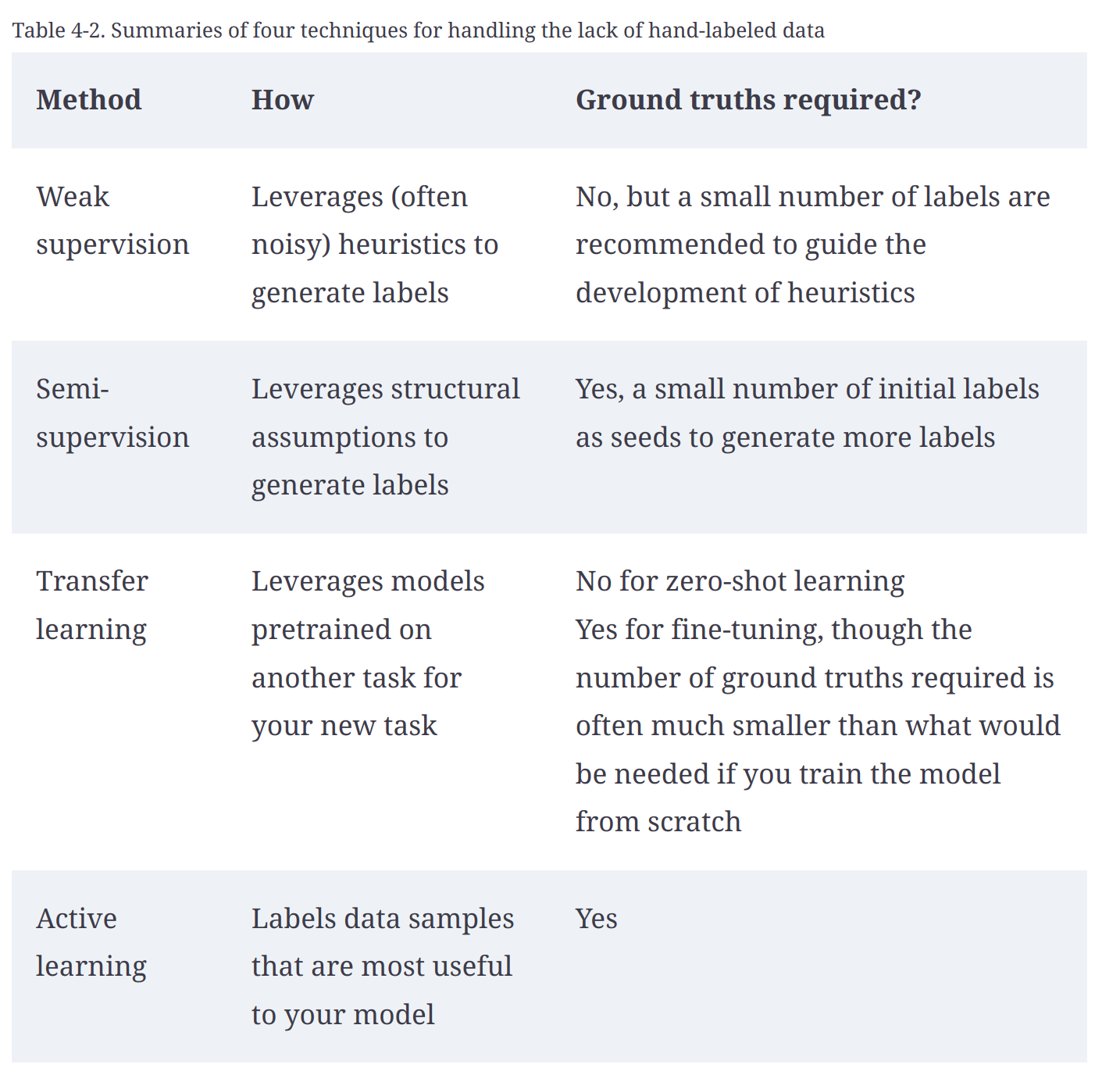
Handling lack of labels
- weak supervision
- Semi-supervision
- Transfer learning
- Active learning
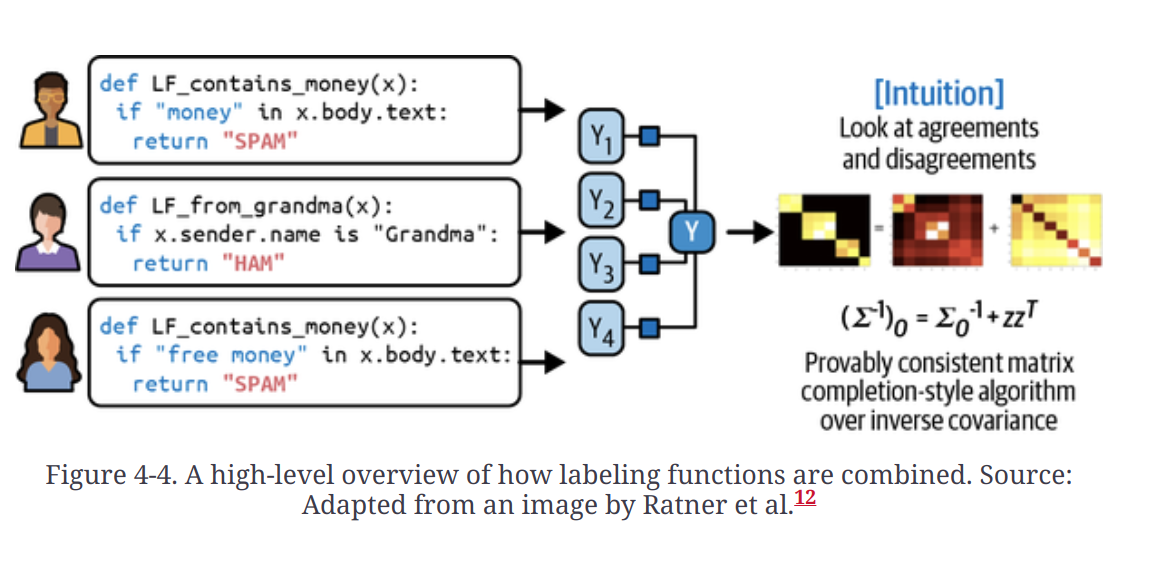
Weak Supervision
- Snorkel
- Heuristics are used to develop the label data which are called label fuctions (LF)
- LFs are combined, denoised and reweighted to get a set of most likely correct labels

Semi-supervision
- Leverages structural assumptions to generate new labels based on a small set of initial labels
- Self-training - Train a model on existing set of labeled data and use this model to make predictions for unlabeled samples
- A semi-supervision method that has gained popularity in recent years is the perturbation-based method. It’s based on the assumption that small perturbations to a sample shouldn’t change its label. So you apply small perturbations to your training instances to obtain new training instances.
- literature survey
Active learning
- Instead of randomly labeling data samples, you label the samples that are most helpful to your models according to some metrics or heuristics. The most straightforward metric is uncertainty measurement—label the examples that your model is the least certain about, hoping that they will help your model learn the decision boundary better.
- literature survey
Class Imbalance
- Using the right evaluation metrics
- Use precision-recall curve in place of ROC curve for imbalance datasets
- Changing the data distribution
- Tomek links - A popular method of undersampling low-dimensional data that was developed back in 1976 is Tomek links.With this technique, you find pairs of samples from opposite classes that are close in proximity and remove the sample of the majority class in each pair.
- oversampling low-dimensional data - SMOTE (synthetic minority oversampling technique)
- When you resample your training data, never evaluate your model on resampled data, since it will cause your model to overfit to that resampled distribution
- Undersampling runs the risk of losing important data from removing data. Oversampling runs the risk of overfitting on training data, especially if the added copies of the minority class are replicas of existing data.
- Two phase learning - Train the model on resampled data by undersampling large classes until each class has only N instances. Then fine-tune the model on the original data
- Dynamic sampling - oversample the low-performing classes and undersample the high-performing classes during the training process.The method aims to show the model less of what it has already learned and more of what it has not.
- Algorithm-level methods
- Adjustment to the loss function
- Cost-sensitive learning
- Class-balanced loss
- Focal loss
- If a sample has a lower probability of being right, it’ll have a higher weight
Data Augmentation
- Useful even when we have a lot of data, can make our models more robust to noise and adversarial attacks
- Simple label-preserving transformations
- Perturbations - NN are sensitive to noise. 67.97% of the natural images in the Kaggle CIFAR-10 test dataset and 16.04% of the ImageNet test images can be misclassified by changing just one pixel. Adding noisy samples to training data can help models recognize the weak spots in their learned decision boundary and improve their performance. Moosavi-Dezfooli et al. proposed an algorithm, called DeepFool, that finds the minimum possible noise injection needed to cause a misclassification with high confidence.
- Data synthesis - In computer vision, a straightforward way to synthesize new data is to combine existing examples with discrete labels to generate continuous labels. Consider a task of classifying images with two possible labels: DOG (encoded as 0) and CAT (encoded as 1). From example _x_1 of label DOG and example _x_2 of label CAT, you can generate x’ such as:
x’=γx1+(1-γ)x2
The label of x’ is a combination of the labels of _x_1 and _x_2: γ×0+(1-γ)×1. This method is called mixup. The authors showed that mixup improves models’ generalization, reduces their memorization of corrupt labels, increases their robustness to adversarial examples, and stabilizes the training of generative adversarial networks.