Instruction Finetuned Text Embeddings
An instruction-finetuned text embedding model that can generate text embeddings tailored to any task (e.g., classification, retrieval, clustering, text evaluation etc.) and domains(e.g,, science, finance etc) by simply providing the task instruction, without any finetuning.
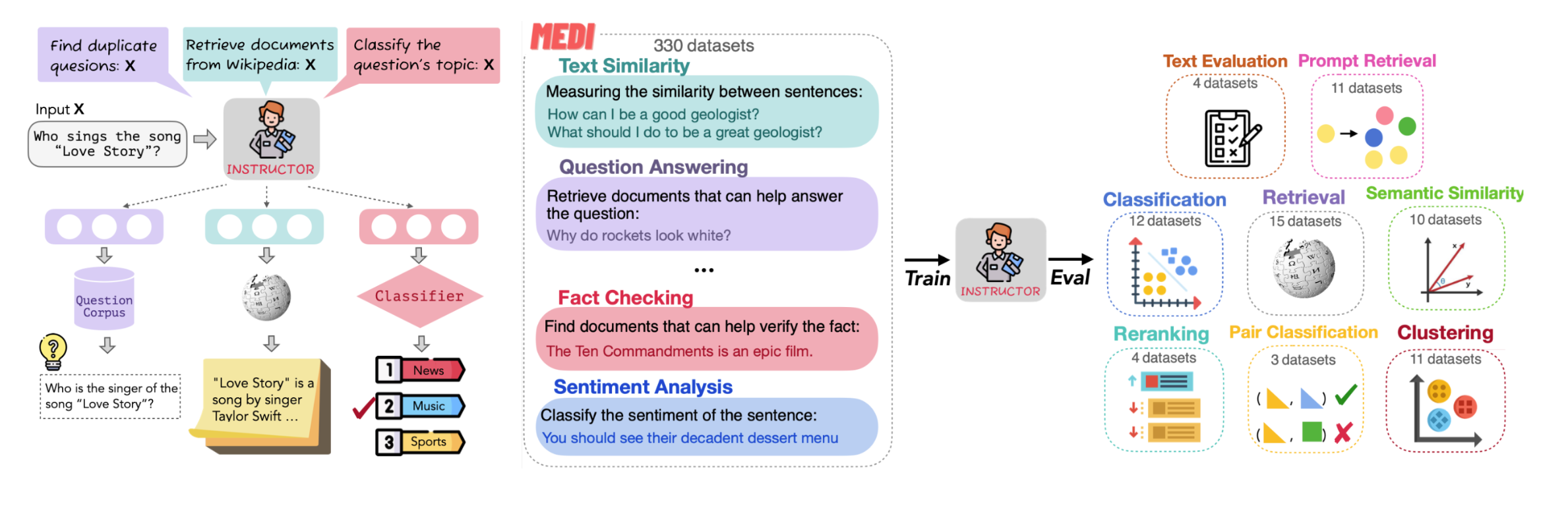
Instructor can calculate domain-specific and task-aware embeddings without any further training. It can be applied to any task for computing fixed-length embeddings of text.
Architecture
- Built on single encoder architecture
- GTR models are used as backbone
- Given an input text and a task instruction, this model encodes their concatenation, then a fixed sized task specific embedding is generated
- The model is trained by maximizing the similarity between positive pairs and minimize negative pairs
Dataset
- 330 datasets with instructions across diverse task categories and domains was constructed. The dataset is known as Multitask Embeddings Data with Instructions (MEDI)
- Inputs for Instruction
- Text type
- Task objective
- Domain
Training
- Instructor is initialized with GTR-Large model and finetune it on MEDI using AdamW optimizer and finetuned for 20k steps
Evaluation
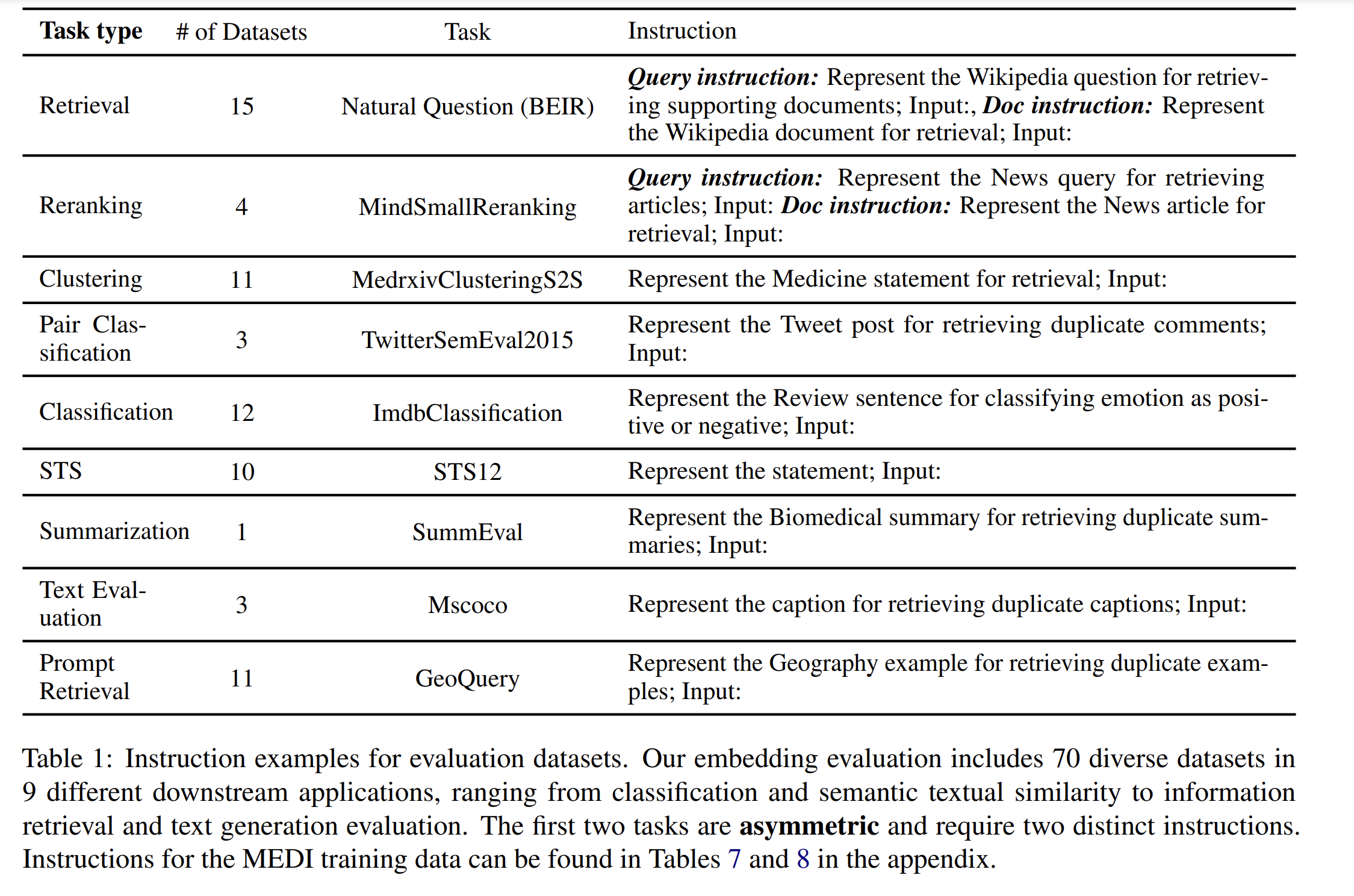
- Intructor is evaluated on 70 downstream tasks. Out of 70 evaluation tasks, 66 are unseen during training
Results
Instructor significantly outperforms prior state-of-the-art embedding models by an average of 3.4% over the 70 diverse datasets. (This is despite the fact that Instructor has one order of magnitude fewer parameters i.e 335M)
!(As the Instructions become detailed, the performance improves)[/Images/instruction_gtre.png]
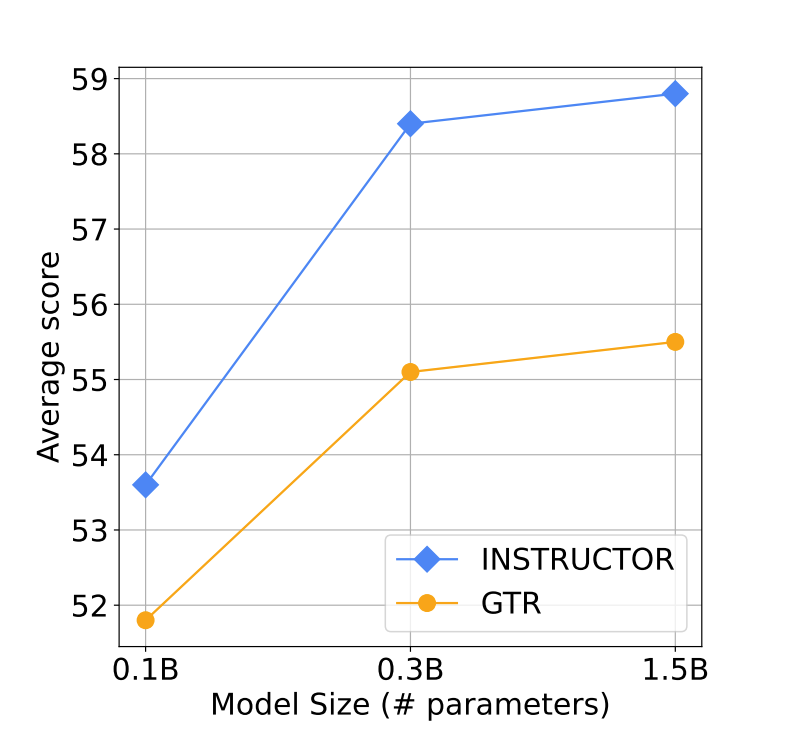
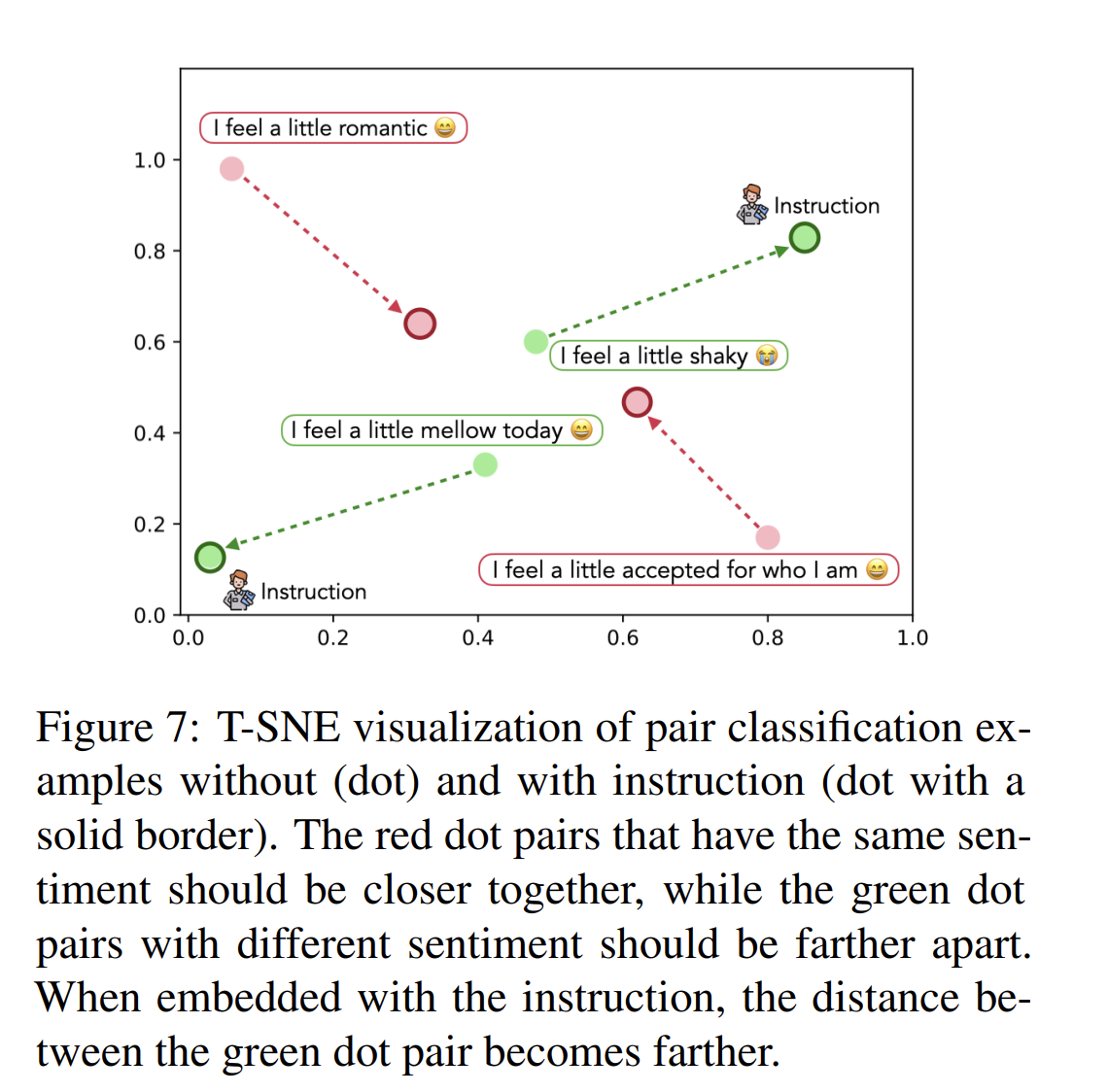
Instructions mitigate domain shifts
- Instructor largely inproves the GTR-Large’s performance on three unseen domains