Why ML system fails
Software system failure
- Dependency failure
- Deployment failure
- Hardware failures
- Downtime or crashing
ML specific failure
- Data distribution shifts in production
- Edge cases
- Degenerate feedback loops
- we can detect degenerate feedback loops by measuring the popularity diversity of a system’s output in recommenders. Other metrics - Aggregate diversity, average coverage of long-tail items can help measure the diversity of outputs of a recommender system
- In 2021, Chia et al. went a step further and proposed the measurement of hit rate against popularity. They first divided items into buckets based on their popularity—e.g., bucket 1 consists of items that have been interacted with less than 100 times, bucket 2 consists of items that have been interacted with more than 100 times but less than 1,000 times, etc. Then they measured the prediction accuracy of a recommender system for each of these buckets. If a recommender system is much better at recommending popular items than recommending less popular items, it likely suffers from popularity bias. Once your system is in production and you notice that its predictions become more homogeneous over time, it likely suffers from degenerate feedback loops.
- Correcting degenerate feedback loops
- Introducing randomization in the predictions can reduce homogeneity
- Each new video is randomly assigned an initial pool of traffic (which can be up to hundreds of impressions). This pool of traffic is used to evaluate each video’s unbiased quality to determine whether it should be moved to a bigger pool of traffic or be marked as irrelevant.
- To exclude positional bias, we may need to encode the position information using positional features.
- During inference, you want to predict whether a user will click on a song regardless of where the song is recommended, so you might want to set the 1st Position feature to be False. Then you look at the model’s predictions for various songs for each user and can choose the order in which to show each song.
Data distribution shifts
- Concept Drift
- Covariate shift
- Label shift
P(X) - probability density of the input P(Y) - probability density of the output


Covariate Shift

- During model development, covariate shifts can happen due to biases during the data selection process
- Covariate shifts can also happen because the training data is artifically altered to make it easier for the model to learn, Ex - oversampling or undersampling the imbalanced datasets
- In production, this can happen because of major changes in environment or in the way application is used
Label Shift
- Remember that covariate shift is when the input distribution changes. When the input distribution changes, the output distribution also changes, resulting in both covariate shift and label shift happening at the same time. Because label shift is closely related to covariate shift, methods for detecting and adapting models to label shifts are similar to covariate shift adaptation methods. We’ll discuss them more later in this chapter.
Concept Drift
- Consider you’re in charge of a model that predicts the price of a house based on its features. Before COVID-19, a three-bedroom apartment in San Francisco could cost $2,000,000. However, at the beginning of COVID-19, many people left San Francisco, so the same apartment would cost only $1,500,000. So even though the distribution of house features remains the same, the conditional distribution of the price of a house given its features has changed.
- Concept drift is seasonal
Detecting Data Distribution Shifts
- Are the model’s performance degrading?
- When ground truth labels are unavailable or too delayed, we can monitor other distributions of interest - P(X)
- Monitor P(X), P(Y), P(X|y), P(y|X) when Y is available
Statistical Methods
- Compute the stats of the values of feature during inference and compare them to the metrics computed during training - Min, Max, Mean, Median, Variance, Quantiles, Skewness, Kurtosis etc
- Use two-sample hypothesis test to test if the difference between two populations is statistically significant.
Alibi Detect is an open-source package for drift detection.
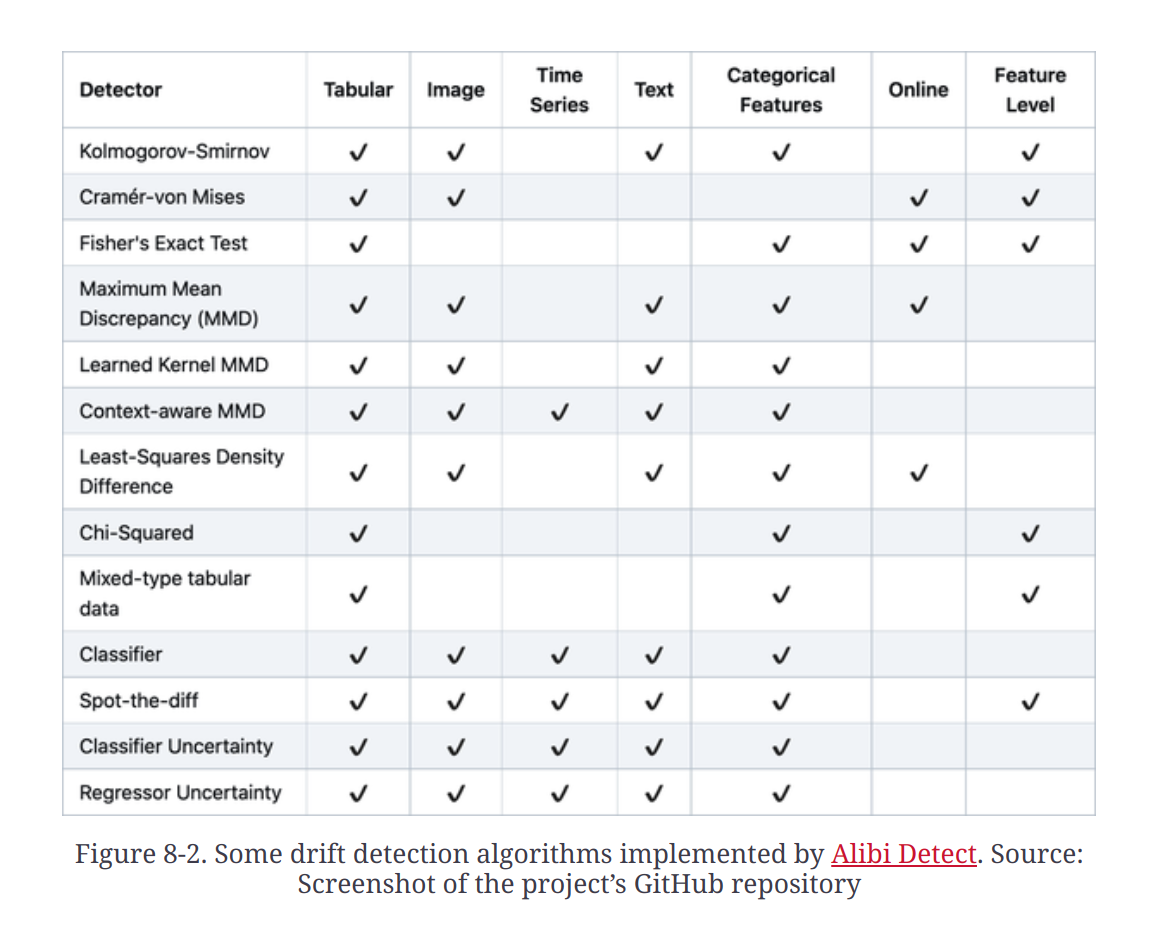
Monitoring ML Specific Metrics
- Accuracy related metrics
- Predictions
- Monitor predictions for distribution shifts
- Prediction distribution shifts are also a proxy for input distribution shifts
- Monitor predictions for anything odd happening, such as predicting an unusual number of False in a row
- Monitoring features
- Feature validation: ensuring that features follow an expected schema
- Great Expectations and Deequ are open-source packages to do data validation

- Monitoring Raw inputs
Resources
Dataset shift in Machine learning by Quinonero-Candela