BERT
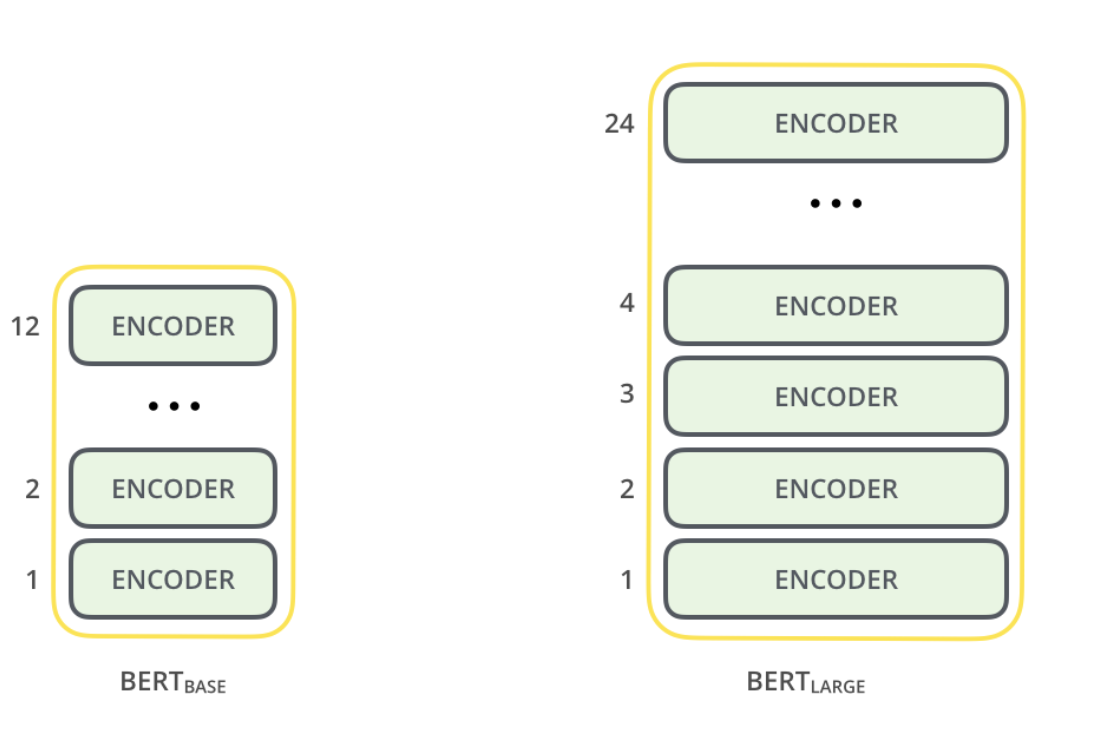
It comes in two model sizes BERT Base and BERT Large.
BERT is a trained transformer Encoder stack.
They have large feedforward networks (768 and 1024 hidden units) and 12 and 16 attention heads respectively.
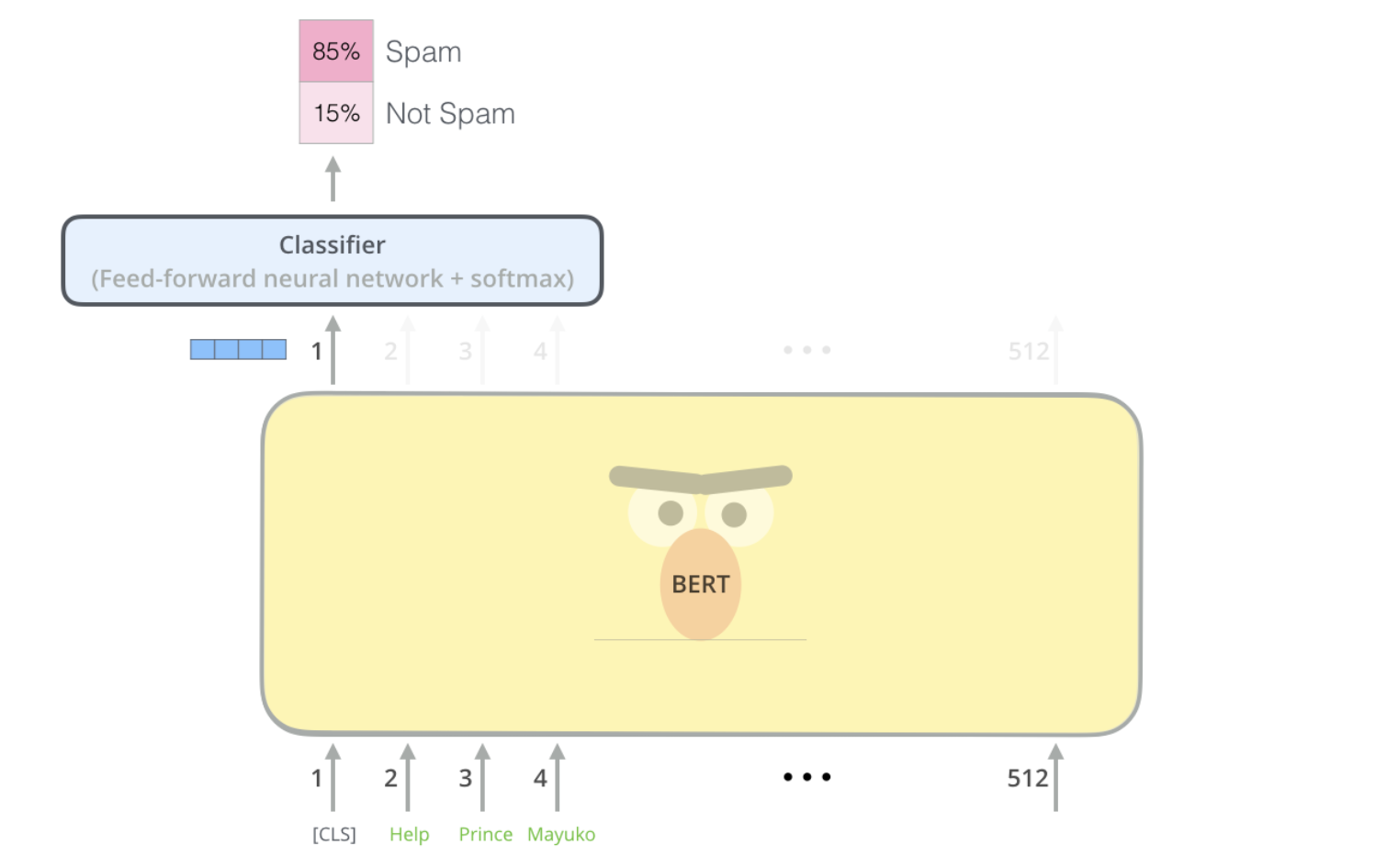
BERT has a [CLS] token which is used for classification. The output from [CLS] will go to a feedforward network along with softmax for classification.
BERT builds on clever ideas like ELMo, ULMFiT and Transformers.
ELMo - Contextualized word-embeddings
The embedding for a word will remain the same irrespective of the context. ELMo provides contextualized word-embeddings. ELMo looks at the entire sentence before assigning each word in it an embedding. It uses Bi-directional LSTM (previous word and next words) trained on a specific task to be able to create embeddings.
ELMo gained its language understanding from being trained to predict the next word in a sequence of words - Language Modeling.
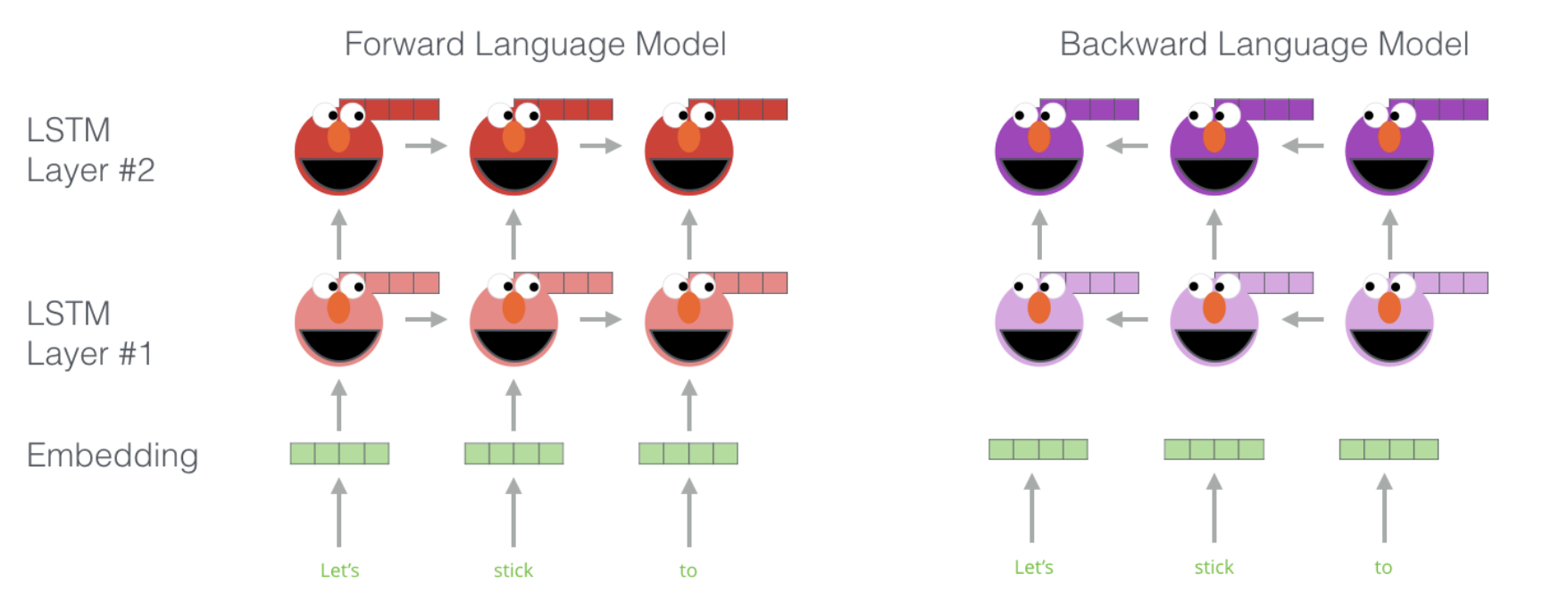
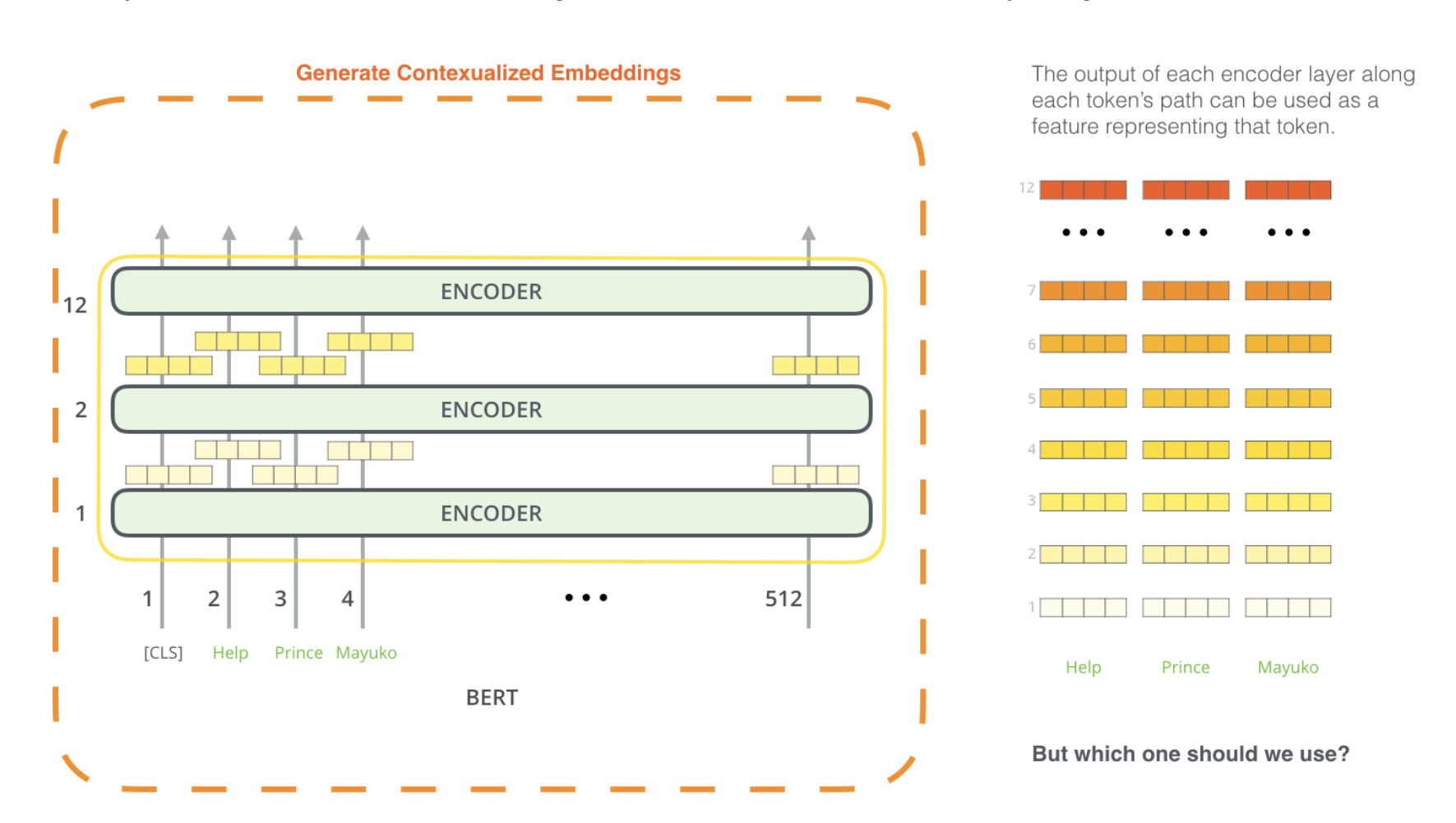
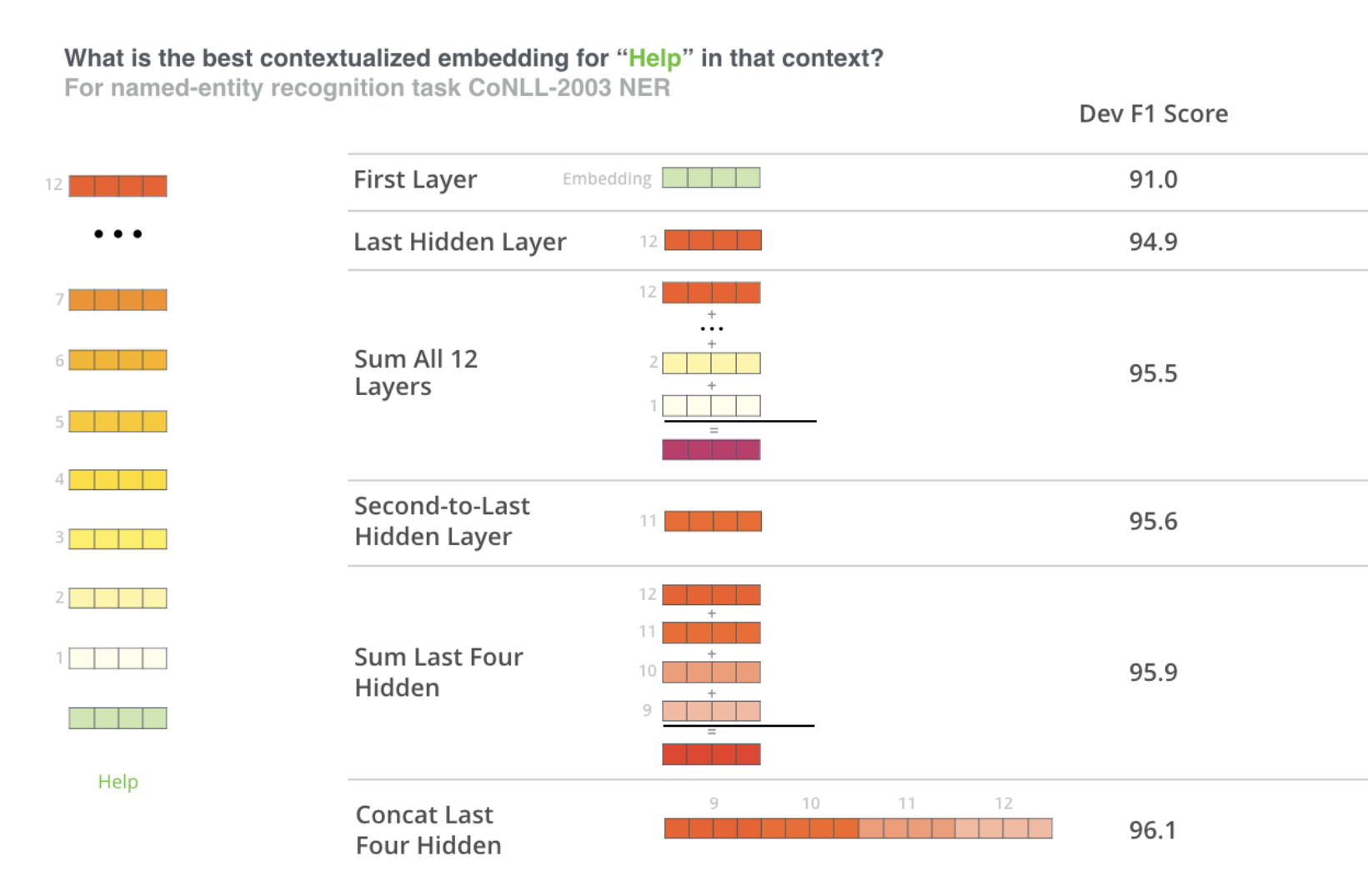
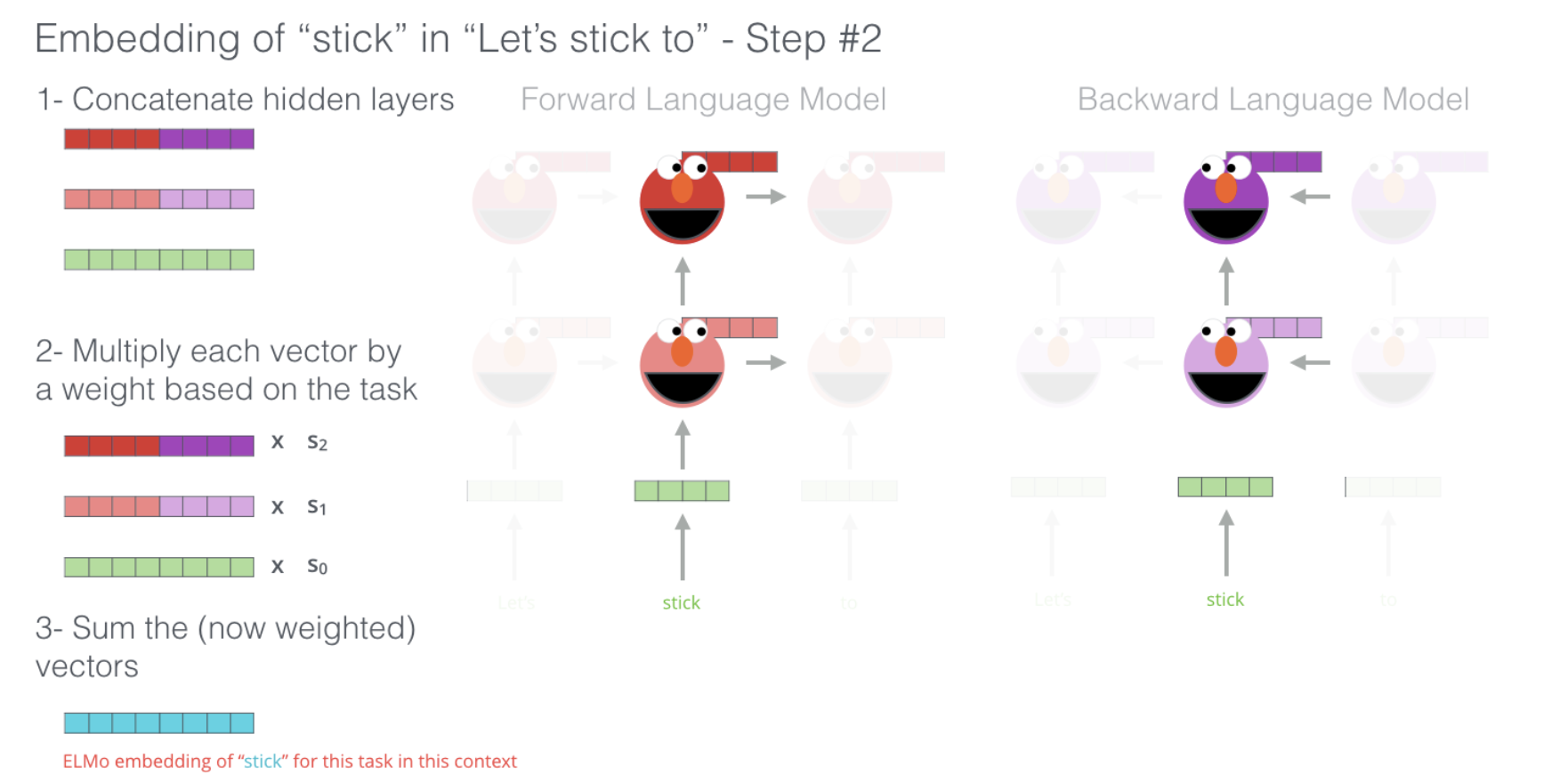
ELMo comes up with the contextualized embedding through grouping together the hidden states (and initial embedding) in a certain way (concatenation followed by weighted summation).
ULM-FiT
ULM-FiT introduced a language model and process to effectively fine-tune that language model for various tasks.
OpenAI Transformer
It turned out that we don’t need an entire transformer to adopt transfer learning, we can do with just the decoder of the Transformer.
The model stacked twelve decoder layers. Since there is no encoder in this set up, these decoder layers would not have the encoder-decoder attention sublayer that vanilla transformer decoder layers have. It would still have the self-attention layer, however (masked so it doesn’t peak at future tokens).
![]()
The Transformer was trained on 7000 books to learn long-term dependencies.
The OpenAI transformer once trained can be used for using it for downstream tasks.
![]()
BERT: From Decoders to Encoders
ELMo’s language model was bi-directional and OpenAI transformer only trains a forward language model.
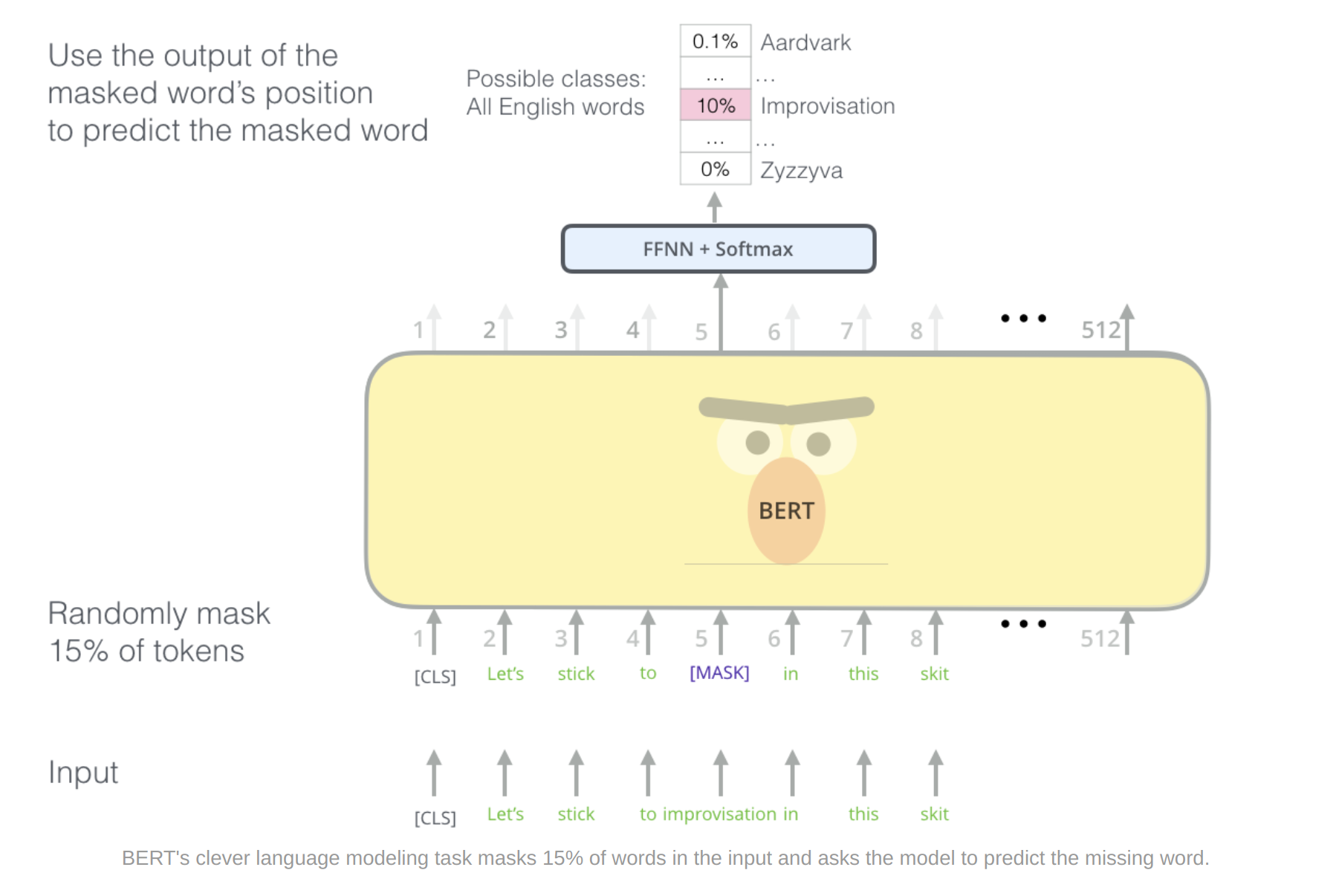
BERT randomly masks 15% of the input and predict the missing word. (A language modeling task)
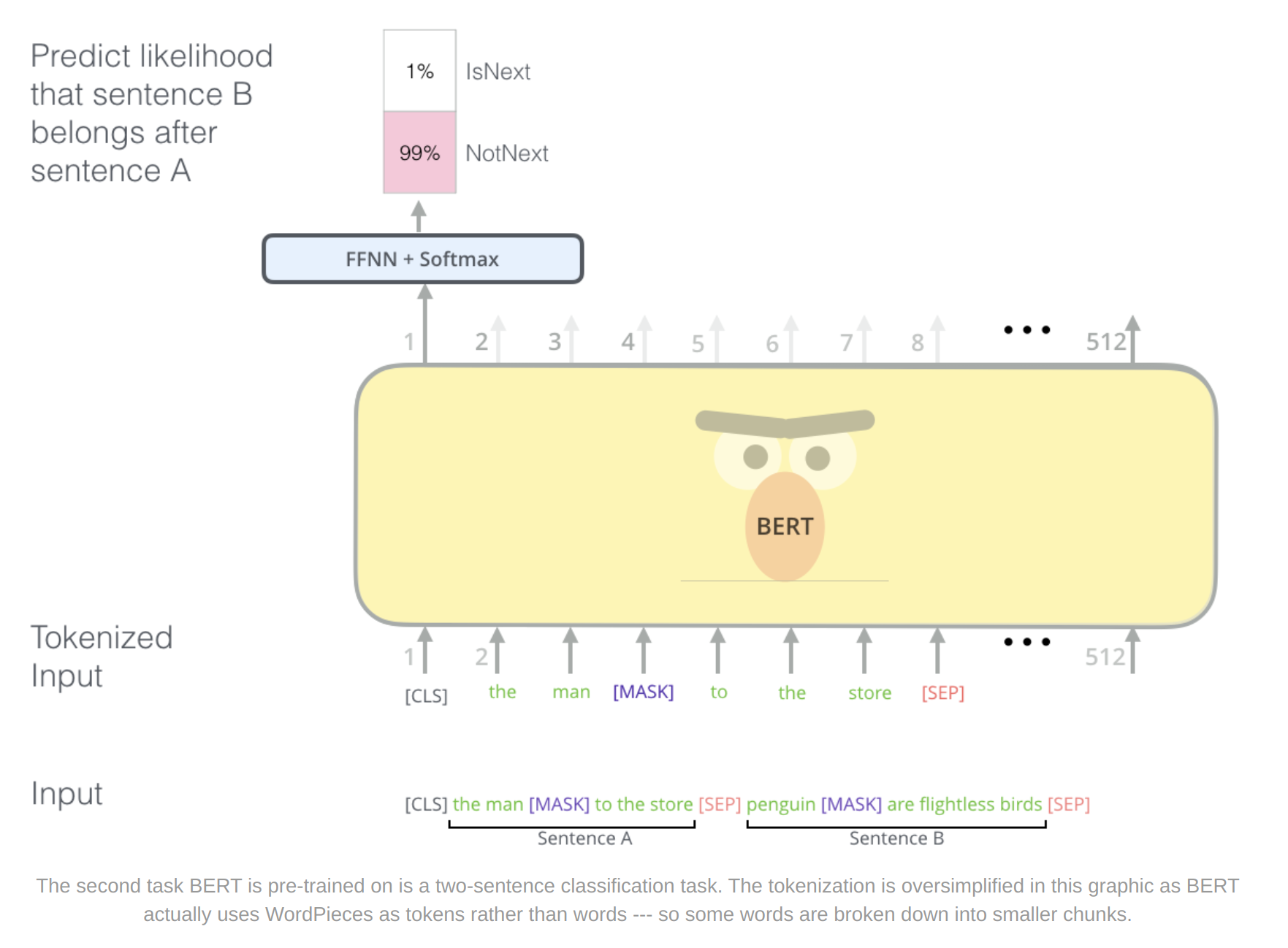
BERT also uses two-sentence tasks to handle different tasks.
Using BERT for different downstream tasks
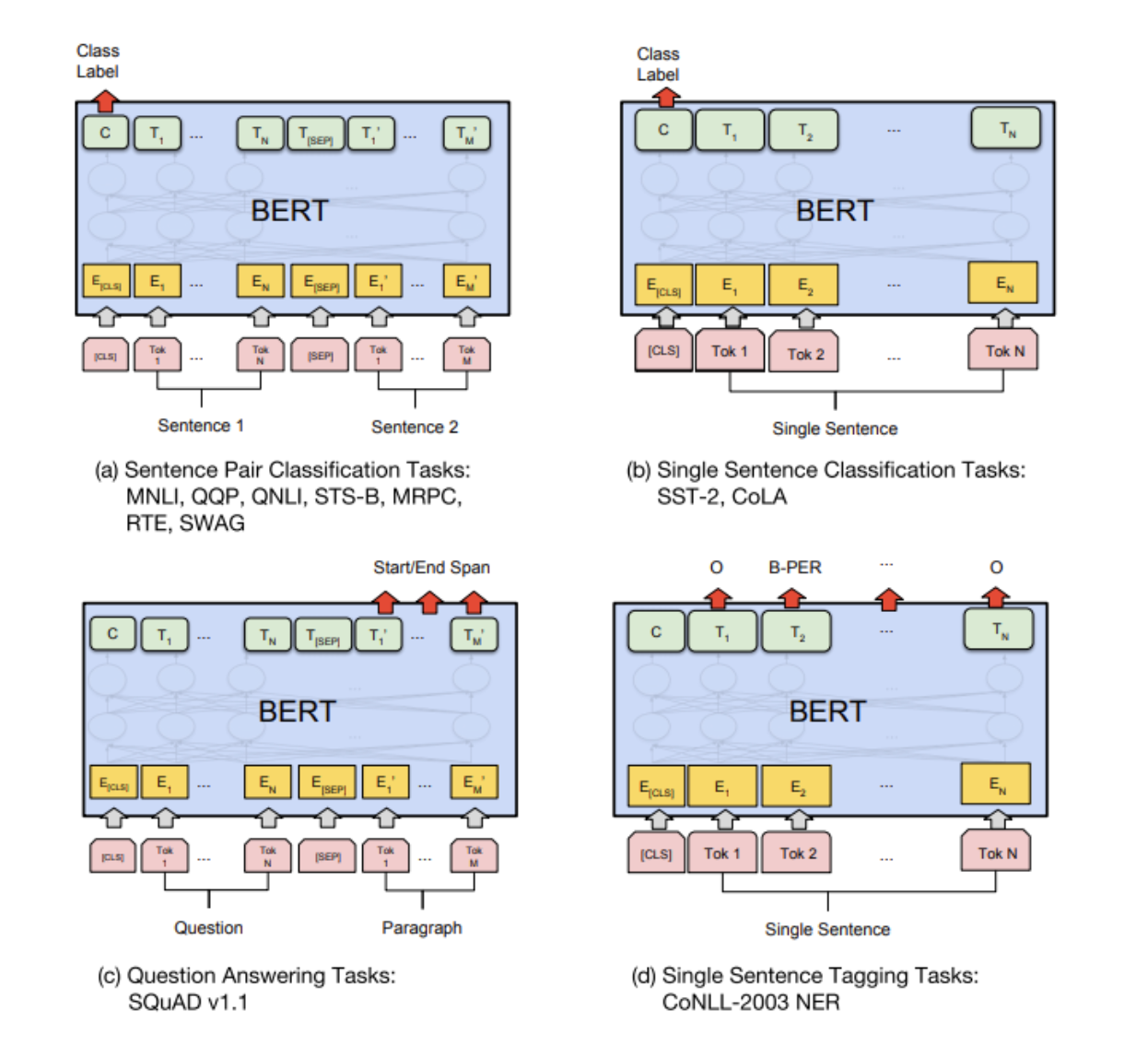
Using BERT for feature extraction