Attention is all you need
Important points
Sequential nature of RNN precludes parallelization within training examples which becomes critical at longer sequence lengths.
Transformer allows for significantly more parallelization
![]()
Encoder and Decoder stacks
Encoder * stack of 6 identical layers * To faciliate residual connections, all sub-layers in the model, as well as the embedding layers, produce outputs of dimension 512.
Decoder * Stack of 6 indentical layers
Attention
- 8 attention heads are used
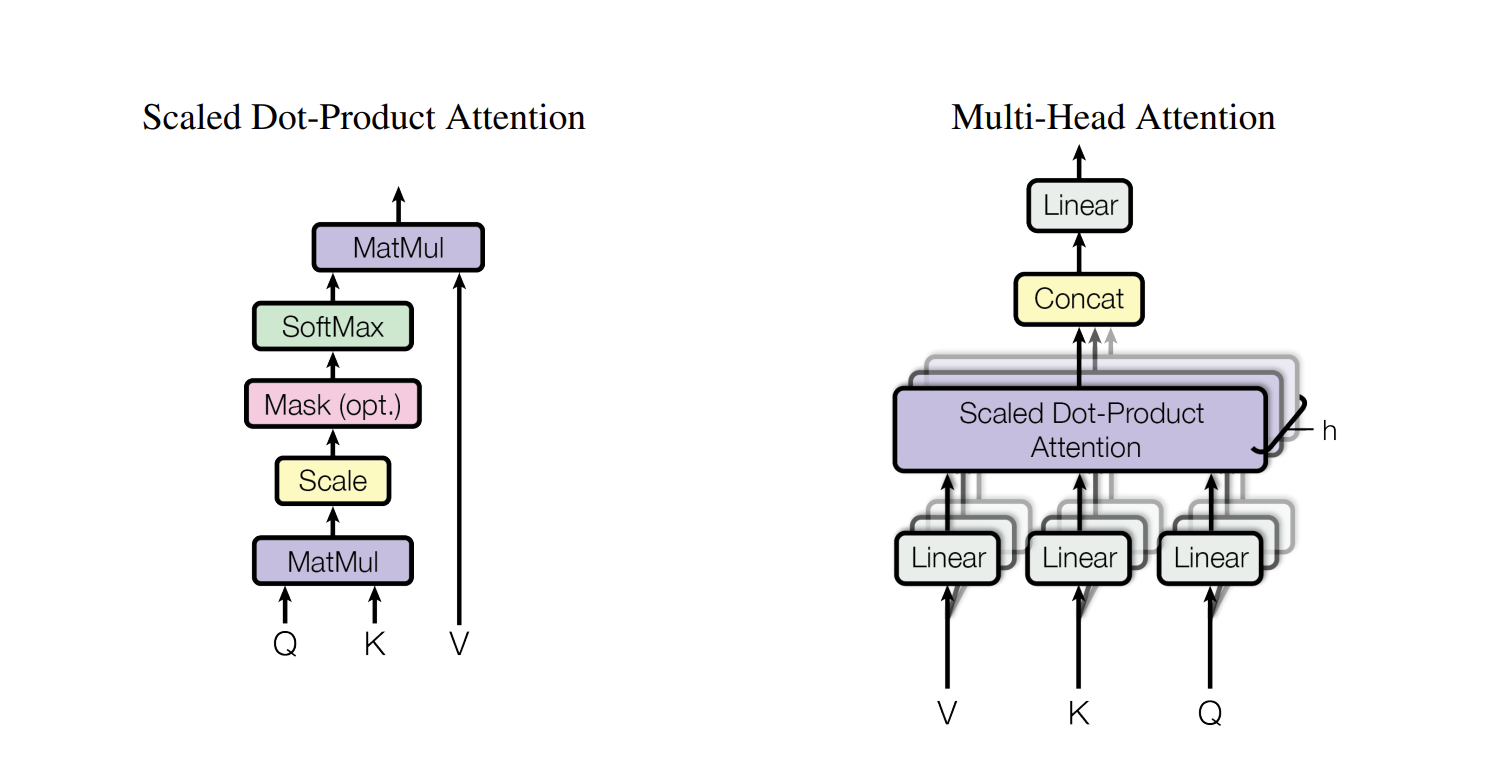
- For large values of dk, the dot products grow large in magnitude, pushing the softmax function into regions where it has extremely small gradients.To counteract this effect scaling of dot product is done.
Multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions.
Application of Attention
In “encoder-decoder attention” layers, the queries come from the previous decoder layer, and the memory keys and values come from the output of the encoder. This allows every position in the decoder to attend over all positions in the input sequence.
Each position in the encoder can attend to all positions in the previous layer of the encoder.
Similarly, self-attention layers in the decoder allow each position in the decoder to attend to all positions in the decoder up to and including that position.
Position-wise Feed-Forward Networks
- The input and output dimensions are 512
- The inner layer has dimensionality of 2048

Self attention could yield more interpretable models