From Data Lake to Data Swamp: Why It Happens and How to Prevent It
Data lakes are powerful tools for storing, managing and analyzing vast amounts of data from a variety of sources. They promise to provide businesses with invaluable insights that can help drive growth and innovation. However, like any powerful tool, data lakes can also pose significant risks if not managed properly. Without careful planning and management, a data lake can quickly become a “data swamp,” filled with irrelevant, low-quality, and outdated data that can harm business operations and hinder decision-making. In this blog post, we will explore the common causes of data swamps in data lakes and provide practical tips and best practices to help you avoid the risks and ensure your data lake remains a valuable asset for your organization.
Before discussing data swamps, let’s take a look at what are the benefits of a data lake.
Benefits of a Data Lake
There are several benefits to using a data lake, including:
Centralized data storage: Data lakes provide a centralized location for storing all data, making it easier to access and analyze.
Scalability: Data lakes can store and process petabytes of data, making them ideal for businesses that generate large amounts of data.
Flexibility: Data lakes can store structured, semi-structured, and unstructured data, allowing businesses to store and analyze data from a variety of sources.
Cost-effectiveness: Data lakes are typically more cost-effective, as they typically store raw data in object stores like s3 or blob storage.
Improved data analysis: Data lakes enable businesses to apply a wide range of analytics techniques to their data, including machine learning, artificial intelligence, and natural language processing. This enables businesses to gain insights and make more informed decisions.
Overall, data lakes provide businesses with a powerful tool for storing, processing, and analyzing large amounts of data, enabling better decision-making and business outcomes.
Why do data lakes become data swamps?
Data lakes are like Gardens. What makes a Garden either attractive or unattractive to us?
A garden is a thing of beauty, a place to escape the hustle and bustle of everyday life and connect with nature. However, just like any other beautiful thing, a garden requires constant maintenance to keep it looking its best. Without regular care, a garden can quickly become overgrown, unkempt, and unsightly. Weeds will sprout up where they’re not wanted, flowers will wither and die, and before long, the once-beautiful garden will be unrecognizable. But with a little bit of attention and care, a garden can thrive, with vibrant flowers, lush greenery, and a peaceful ambience that can soothe the soul. Data lakes need care and maintenance just like a beautiful garden.
Here are some reasons why a data lake becomes a data swamp:-
Lack of data governance: Without proper data governance policies and procedures, a data lake can become cluttered with irrelevant or inaccurate data, making it difficult to find and use the data that is needed.
Poor data quality: If data is ingested into the data lake without being properly validated or cleaned, it can lead to poor data quality.
Lack of metadata management: Metadata is data that describes the data, and it is essential for understanding and using the data in the data lake. Without proper metadata management, it can be difficult to understand what data is stored in the data lake and how it should be used.
Lack of data access controls: If the data lake is not properly secured, unauthorized users may be able to access and modify data, which can lead to inaccurate or irrelevant data being stored in the data lake.
Lack of privacy controls: If Personally Identifiable Information (PII) data is not handled properly, it can lead to data leakage and loss of user privacy. This can severely damage the reputation of the organization.
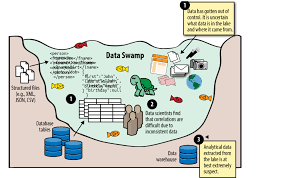
How to prevent a data lake from becoming a data swamp?
Simply put, taking regular care and maintenance can be a great way to prevent a data lake from becoming a data swamp.
Here are some ways to maintain a data lake:-
Establishing proper data governance policiesto ensure that data is properly managed throughout its lifecycle.Ensure data qualityduring the processing of the raw data. Take necessary action to ensure raw data is clean.Implement Metadata management and data discovery, your users should be able to find the required data in the data lake and also know how it was generated and what various attributes mean.Ensure data access controls, such that only authorized users can access and modify the data.Ensure user privacy is protected, never store PII data in the data lake. Ensure PII data is either masked or any appropriate privacy controls are in place. If there is no business case for using PII data then better not to store it in the first place.
These are easier said than done. It needs a lot of time, effort and coordination with different teams to ensure data lakes are crystal clear and beneficial to the organisation.
Data lakes are not the only solution to handle large amounts of an organisation’s data. There are other alternatives to data lakes like Enterprise Data Warehouse, Data Mart, Data Virtualization, Data Fabric, Data Hub and Data Mesh. Every organization should evaluate the requirements, strengths and weaknesses of each framework and choose the best solution. Let us discuss these frameworks in some of our future blog posts.
To Summarize, data lakes are capable to handle a variety of data sources in huge volumes. They are flexible and scalable. When they are planned, built and maintained properly, they can be very beneficial for any organization. If not they will become data swamps. A few ways to prevent a data lake from becoming a data swamp are ensuring data quality, governance, metadata management, data discovery, data access control, and protecting user privacy.
Hope you learned something about data lakes today and let us meet in our next blog post.